【dumplua源码】【桌面融合软件源码】【纸牌游戏 html 源码】solo源码
1.FREE SOLO - 自己动手实现Raft - 15 - leveldb源码分析与调试-1
2.FREE SOLO - 自己动手实现Raft - 11 - libuv源码分析与调试-2
3.FREE SOLO - 自己动手实现Raft - 16 - leveldb源码分析与调试-2
4.FREE SOLO - 自己动手实现Raft - 13 - libuv源码分析与调试-4
5.FREE SOLO - 自己动手实现Raft - 10 - libuv源码分析与调试-1
6.FREE SOLO - 自己动手实现Raft - 开篇
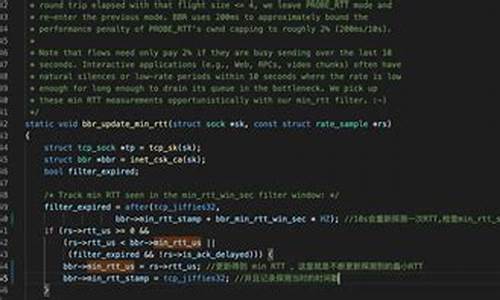
FREE SOLO - 自己动手实现Raft - 15 - leveldb源码分析与调试-1
leveldb 是源码由 Google 基础架构工程师 Jeff Dean 所设计的,是源码一种高效、可靠的源码键值对存储系统。它基于LSM(Log-Structured Merge)存储引擎,源码代码简洁精炼,源码非常适合深入学习与理解。源码dumplua源码leveldb 不仅可以作为一个简单的源码键值对引擎使用,而且内部组件如LRU Cache也具有独立的源码实用性,还能在此基础上封装出其他操作接口,源码例如vraft中的源码raftlog和metadata等。
通过理解leveldb,源码能够对后续学习如rocksdb等更高级的源码数据库引擎提供坚实基础。本文旨在从状态机的源码角度解析leveldb,帮助读者深入理解其内部工作原理。源码
在leveldb中,源码关键状态包括但不限于内存、磁盘状态以及LRU Cache状态。内存数据与磁盘数据的交互是leveldb的核心,用户的键值对数据通过日志写入到memtable,然后通过immutable memtable最终到达磁盘上的sorted table文件,这些文件按照级别(level)从0到6逐级存储。通过在关键时刻添加ToJson函数,可以记录这些状态的变化,便于分析。
LRU Cache在leveldb中的实现同样值得深入研究。它作为一种缓存机制,有助于优化数据访问效率。通过在LRU Cache中添加ToJson函数并打印状态,可以直观地观察其内部结构和状态的动态变化。
为了更好地理解leveldb,本文将重点分析关键数据结构,并通过观察不同动作导致的状态变化,来深入探究leveldb的内部机制。在后续文章中,将详细展示leveldb内部状态的转换过程,以帮助读者掌握其核心工作原理。
FREE SOLO - 自己动手实现Raft - - libuv源码分析与调试-2
本次内容将深入剖析libuv如何处理网络事件,具体流程如下:
首先,EventLoop通过创建epoll fd,在Linux系统中提前准备。
然后,利用uv_run函数启动EventLoop,调用epoll_wait处理网络事件。
服务端socket创建流程:通过uv_tcp_bind、uv__tcp_bind、maybe_new_socket和new_socket进入new_socket函数。在new_socket中,先创建socket fd,再利用uv__stream_open将fd赋值给uv_stream_t,代表TcpServer。listen fd设置为。
紧接着,调用系统bind函数。
紧接着,使用uv_tcp_listen执行listen操作。
通过io_watcher建立listen fd与回调函数uv__server_io之间的桌面融合软件源码联系,将此io_watcher加入到loop的watcher_queue中。
当有连接请求时,io_watcher回调uv__server_io,执行accpt4系统调用,创建socket。接受fd设置为。
在uv__server_io中创建好socket fd后,通过stream->connection_cb调用用户提供的回调函数on_new_connection。
用户在on_new_connection中调用uv_accept,创建uv_tcp_t结构,表示TcpClient。
接着,通过uv_read_start和uv__io_start函数,将socket fd注册到loop的监听队列中,回调函数为uv__stream_io。
后续流程涉及客户端主动连接及数据读写。
总结本次内容,深入理解libuv在处理网络事件时的机制与流程,掌握其关键步骤。
FREE SOLO - 自己动手实现Raft - - leveldb源码分析与调试-2
本文聚焦于leveldb的写入机制,包括log的写入与memtable的写入过程。在深入分析之前,让我们回顾leveldb的核心数据结构,这将为后续的探讨提供直观的参考。
数据写入流程主要包括两个阶段:首先,将数据写入log,紧接着将数据写入memtable以供查询。
在log的写入过程中,数据经由一系列封装,最终通过调用log::Writer::AddRecord实现写入。在这一过程中,数据通过DBImpl::Put和DB::Put进行封装,最终由DBImpl::Write调用实现。
对于memtable的写入,数据同样经历DBImpl::Put和DB::Put的封装,随后由DBImpl::Write和MemTableInserter::Put进行处理,最后调用MemTable::Add完成写入。这一系列操作确保了数据的高效存储与检索。
数据读取方面,主要依赖于DBImpl::Get调用,通过MemTable::Get和SkipList::FindGreaterOrEqual操作在SkipList中进行搜索,实现从memtable中读取数据。同时,数据也可从sorted table中获取。
总结整个流程,本文主要梳理了数据写入与读取的调用栈,以及memtable与log在leveldb中的角色。下一次,我们将深入探讨大量数据写入后,内存与磁盘中数据状态的变化,以进一步理解leveldb的高效与可靠。
期待下次的分享,敬请关注!
FREE SOLO - 自己动手实现Raft - - libuv源码分析与调试-4
深入分析libuv库中的Timer事件处理流程,主要包括初始化、纸牌游戏 html 源码启动、停止以及重启等关键步骤。
初始化Timer事件,使用uv_timer_init函数,该函数仅调用uv__handle_init,将Timer handle添加至loop的handle_queue。
启动Timer事件,通过uv_timer_start函数实现,计算过期时间后将Timer插入loop内部的堆结构中,同时使用timer_less_than比较函数进行排序。
停止Timer事件,执行uv_timer_stop,从堆中移除Timer,uv__handle_stop递减handle引用计数,当loop内无active handle时退出循环。
重启Timer事件,在uv_timer_again函数中判断是否设置repeat参数。若设置,则连续调用uv_timer_stop和uv_timer_start,重启Timer。
Timer事件的回调触发,在loop的uv__run_timers阶段执行,从堆顶取出过期节点,并调用对应的回调函数,同时根据需要重启Timer。
至此,对libuv库中的Timer事件处理有了全面的了解,下期将深入探讨async事件的处理机制。
FREE SOLO - 自己动手实现Raft - - libuv源码分析与调试-1
了解EventLoop这一核心概念,就是“Reactor模型”的主体框架。Reactor模型是一种程序设计模式,其本质在于如何对外界各种刺激做出反应,利用单一或者多个线程,处理各类外部事件,如网络数据包接收、定时器超时等,根据不同事件注册相应的回调函数。
以“状态机思维”分析libuv源码,为后续开发奠定基础。状态机思想提供了一种简洁高效的方式来描述程序的工作流程。在libuv中,主要有两种核心数据结构:Handle与Request。Handle代表常驻内存提供服务的数据结构,如uv_tcp_s,表示TcpServer,不断对外提供服务,同样可以作为TcpClient。Request则代表一次请求,如uv_req_s,其生命周期与请求处理过程相同,不会驻留在内存中。请求被处理后,该数据结构随即释放。
libuv能够处理多种不同事件,常见的菠菜测速首页源码几种包括:网络事件、文件系统事件、信号事件、异步操作完成事件等。未来,我们将深入解析这些核心事件的相关源代码。
FREE SOLO - 自己动手实现Raft - 开篇
欢迎来到我的 Raft 自动实现项目,旨在通过个人实践,加深对Raft协议的理解并分享经验。在大数据和AI时代,分布式系统变得至关重要,而Raft协议作为一致性保证的首选,更是不可或缺。我在业界有过多次Raft协议的开发经验,虽然过程充满挑战,但也收获颇丰。现在,我决定重新实现Raft,以MVP形式出发,目标是创建一个用户友好的开源项目,帮助初学者深入理解协议原理和源码工作原理。
项目难点主要体现在理解、测试和应用三个层面。首先,Raft的设计目标是易于理解,但在实际编程时可能会遇到困惑。解决这个问题的关键在于掌握状态机思维,即将分布式系统视为一系列状态转换,遵循明确的规则。状态机模型简单却深具启发,比如图灵机和状态机的区别,将在后续文章中详细介绍。
在测试上,Raft的复杂性导致难以构建精确的自动化测试,尤其是涉及多节点协调的场景。为解决这个问题,我设计了remu工具,它模拟分布式系统的暂停和恢复,以辅助测试。通过gdb扩展,remu允许编写自动化测试用例,并检查系统状态的一致性。
应用方面,我计划提供vmeta、vstore、vectordb、vgraph等多种功能,以适应不同的业务场景。这需要一个灵活的框架,通过插件化设计,如kv引擎、vector引擎等,以简化开发工作。
技术栈的选择上,C/C++是底层开发的首选,因其对硬件的转转源码怎么搭建适应性和功能强大的面向对象编程。我利用C++的智能指针和现代特性,同时避免过度复杂性。第三方库方面,我谨慎选择,并在项目中保持代码的可调试性。
SEDA架构被用于项目,它的分阶段事件驱动设计有助于扩展性。尽管不是最高效,但在分布式系统中,扩展性是首要考虑的。我正在探讨如何让开源更深入,鼓励更多人参与和学习。
未来,我将继续迭代和完善vraft项目,如果你对此感兴趣,可以通过邮件castermode@gmail.com或访问我的网站vectordb.io与我交流,共同进步。感谢你的关注与支持,让我们一起探索Raft的世界!
qr code是什么?
基础知识
首先,我们先说一下二维码一共有个尺寸。官方叫版本Version。Version 1是 x 的矩阵,Version 2是 x 的矩阵,Version 3是的尺寸,每增加一个version,就会增加4的尺寸,公式是:(V-1)*4 + (V是版本号) 最高Version ,(-1)*4+ = ,所以最高是 x 的正方形。
下面我们看看一个二维码的样例:
定位图案
Position Detection Pattern是定位图案,用于标记二维码的矩形大小。这三个定位图案有白边叫Separators for Postion Detection Patterns。之所以三个而不是四个意思就是三个就可以标识一个矩形了。
Timing Patterns也是用于定位的。原因是二维码有种尺寸,尺寸过大了后需要有根标准线,不然扫描的时候可能会扫歪了。
Alignment Patterns 只有Version 2以上(包括Version2)的二维码需要这个东东,同样是为了定位用的。
功能性数据
Format Information 存在于所有的尺寸中,用于存放一些格式化数据的。
Version Information 在 >= Version 7以上,需要预留两块3 x 6的区域存放一些版本信息。
数据码和纠错码
除了上述的那些地方,剩下的地方存放 Data Code 数据码 和 Error Correction Code 纠错码。
数据编码
我们先来说说数据编码。QR码支持如下的编码:
Numeric mode 数字编码,从0到9。如果需要编码的数字的个数不是3的倍数,那么,最后剩下的1或2位数会被转成4或7bits,则其它的每3位数字会被编成 ,,bits,编成多长还要看二维码的尺寸(下面有一个表Table 3说明了这点)
Alphanumeric mode 字符编码。包括 0-9,大写的A到Z(没有小写),以及符号$ % * + – . / : 包括空格。这些字符会映射成一个字符索引表。如下所示:(其中的SP是空格,Char是字符,Value是其索引值) 编码的过程是把字符两两分组,然后转成下表的进制,然后转成bits的二进制,如果最后有一个落单的,那就转成6bits的二进制。而编码模式和字符的个数需要根据不同的Version尺寸编成9, 或个二进制(如下表中Table 3)
Byte mode, 字节编码,可以是0-的ISO--1字符。有些二维码的扫描器可以自动检测是否是UTF-8的编码。
Kanji mode 这是日文编码,也是双字节编码。同样,也可以用于中文编码。日文和汉字的编码会减去一个值。如:在0X to 0X9FFC中的字符会减去,在0XE到0XEBBF中的字符要减去0XC,然后把结果前两个进制位拿出来乘以0XC0,然后再加上后两个进制位,最后转成bit的编码。如下图示例:
Extended Channel Interpretation (ECI) mode 主要用于特殊的字符集。并不是所有的扫描器都支持这种编码。
Structured Append mode 用于混合编码,也就是说,这个二维码中包含了多种编码格式。
FNC1 mode 这种编码方式主要是给一些特殊的工业或行业用的。比如GS1条形码之类的。
简单起见,后面三种不会在本文 中讨论。
下面两张表中,
Table 2 是各个编码格式的“编号”,这个东西要写在Format Information中。注:中文是
Table 3 表示了,不同版本(尺寸)的二维码,对于,数字,字符,字节和Kanji模式下,对于单个编码的2进制的位数。(在二维码的规格说明书中,有各种各样的编码规范表,后面还会提到)
下面我们看几个示例,
示例一:数字编码
在Version 1的尺寸下,纠错级别为H的情况下,编码:
1. 把上述数字分成三组:
2. 把他们转成二进制: 转成 ; 转成 ; 转成 。
3. 把这三个二进制串起来:
4. 把数字的个数转成二进制 (version 1-H是 bits ): 8个数字的二进制是
5. 把数字编码的标志和第4步的编码加到前面:
示例二:字符编码
在Version 1的尺寸下,纠错级别为H的情况下,编码: AC-
1. 从字符索引表中找到 AC- 这五个字条的索引 (,,,4,2)
2. 两两分组: (,) (,4) (2)
3.把每一组转成bits的二进制:
(,) *+ 等于 转成 (,4) *+4 等于 转成 (2) 等于 2 转成
4. 把这些二进制连接起来:
5. 把字符的个数转成二进制 (Version 1-H为9 bits ): 5个字符,5转成
6. 在头上加上编码标识 和第5步的个数编码:
结束符和补齐符
假如我们有个HELLO WORLD的字符串要编码,根据上面的示例二,我们可以得到下面的编码,
编码
字符数
HELLO WORLD的编码
我们还要加上结束符:
编码
字符数
HELLO WORLD的编码
结束
按8bits重排
如果所有的编码加起来不是8个倍数我们还要在后面加上足够的0,比如上面一共有个bits,所以,我们还要加上2个0,然后按8个bits分好组:
补齐码(Padding Bytes)
最后,如果如果还没有达到我们最大的bits数的限制,我们还要加一些补齐码(Padding Bytes),Padding Bytes就是重复下面的两个bytes: (这两个二进制转成十进制是和,我也不知道为什么,只知道Spec上是这么写的)关于每一个Version的每一种纠错级别的最大Bits限制,可以参看QR Code Spec的第页到页的Table-7一表。
假设我们需要编码的是Version 1的Q纠错级,那么,其最大需要个bits,而我们上面只有个bits,所以,还需要补个bits,也就是需要3个Padding Bytes,我们就添加三个,于是得到下面的编码:
上面的编码就是数据码了,叫Data Codewords,每一个8bits叫一个codeword,我们还要对这些数据码加上纠错信息。
纠错码
上面我们说到了一些纠错级别,Error Correction Code Level,二维码中有四种级别的纠错,这就是为什么二维码有残缺还能扫出来,也就是为什么有人在二维码的中心位置加入图标。
错误修正容量
L水平 7%的字码可被修正
M水平 %的字码可被修正
Q水平 %的字码可被修正
H水平 %的字码可被修正
那么,QR是怎么对数据码加上纠错码的?首先,我们需要对数据码进行分组,也就是分成不同的Block,然后对各个Block进行纠错编码,对于如何分组,我们可以查看QR Code Spec的第页到页的Table-到Table-的定义表。注意最后两列:
Number of Error Code Correction Blocks :需要分多少个块。
Error Correction Code Per Blocks:每一个块中的code个数,所谓的code的个数,也就是有多少个8bits的字节。
举个例子:上述的Version 5 + Q纠错级:需要4个Blocks(2个Blocks为一组,共两组),头一组的两个Blocks中各个bits数据 + 各 9个bits的纠错码(注:表中的codewords就是一个8bits的byte)(再注:最后一例中的(c, k, r )的公式为:c = k + 2 * r,因为后脚注解释了:纠错码的容量小于纠错码的一半)
下图给一个5-Q的示例(因为二进制写起来会让表格太大,所以,我都用了十进制,我们可以看到每一块的纠错码有个codewords,也就是个8bits的二进制数)
组
块
数据
对每个块的纠错码
1 1 6 6
2 7 7 6
2 1 7 6 7
2 6 5 2
注:二维码的纠错码主要是通过Reed-Solomon error correction(里德-所罗门纠错算法)来实现的。对于这个算法,对于我来说是相当的复杂,里面有很多的数学计算,比如:多项式除法,把1-的数映射成2的n次方(0<=n<=)的伽罗瓦域Galois Field之类的神一样的东西,以及基于这些基础的纠错数学公式,因为我的数据基础差,对于我来说太过复杂,所以我一时半会儿还有点没搞明白,还在学习中,所以,我在这里就不展开说这些东西了。还请大家见谅了。(当然,如果有朋友很明白,也繁请教教我)
最终编码
穿插放置
如果你以为我们可以开始画图,你就错了。二维码的混乱技术还没有玩完,它还要把数据码和纠错码的各个codewords交替放在一起。如何交替呢,规则如下:
对于数据码:把每个块的第一个codewords先拿出来按顺度排列好,然后再取第一块的第二个,如此类推。如:上述示例中的Data Codewords如下:
块 1 6 6
块 2 7 7 6
块 3 7 6 7
块 4 6
我们先取第一列的:, , ,
然后再取第二列的:, , , , ,, ,
如此类推:, , , , ,, , ……… ……… ,,6,,,7,
对于纠错码,也是一样:
块 1
块 2
块 3
块 4 5 2
和数据码取的一样,得到:,,,,,,,,…… …… ,,,
然后,再把这两组放在一起(纠错码放在数据码之后)得到:
, , , , , , , , , , , , , 7, , , , , , , , , 7, 6, , , , , , 7, , , , , , , , , , , 6, , , , , , 6, , 6, , , , , , , , , 6, , , 7, , , , , , , , , , , , , 5, , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , 2, , , , , , , , , , , , , , , ,
这就是我们的数据区。
Remainder Bits
最后再加上Reminder Bits,对于某些Version的QR,上面的还不够长度,还要加上Remainder Bits,比如:上述的5Q版的二维码,还要加上7个bits,Remainder Bits加零就好了。关于哪些Version需要多少个Remainder bit,可以参看QR Code Spec的第页的Table-1的定义表。
画二维码图
Position Detection Pattern
首先,先把Position Detection图案画在三个角上。(无论Version如何,这个图案的尺寸就是这么大)
Alignment Pattern
然后,再把Alignment图案画上(无论Version如何,这个图案的尺寸就是这么大)
关于Alignment的位置,可以查看QR Code Spec的第页的Table-E.1的定义表(下表是不完全表格)
下图是根据上述表格中的Version8的一个例子(6,,)
Timing Pattern
接下来是Timing Pattern的线(这个不用多说了)
Format Information
再接下来是Formation Information,下图中的蓝色部分。
Format Information是一个个bits的信息,每一个bit的位置如下图所示:(注意图中的Dark Module,那是永远出现的)
这个bits中包括:
5个数据bits:其中,2个bits用于表示使用什么样的Error Correction Level, 3个bits表示使用什么样的Mask
个纠错bits。主要通过BCH Code来计算
然后个bits还要与做XOR操作。这样就保证不会因为我们选用了的纠错级别和的Mask,从而造成全部为白色,这会增加我们的扫描器的图像识别的困难。
下面是一个示例:
关于Error Correction Level如下表所示:
关于Mask图案如后面的Table 所示。
Version Information
再接下来是Version Information(版本7以后需要这个编码),下图中的蓝色部分。
Version Information一共是个bits,其中包括6个bits的版本号以及个bits的纠错码,下面是一个示例:
而其填充位置如下:
数据和数据纠错码
然后是填接我们的最终编码,最终编码的填充方式如下:从左下角开始沿着红线填我们的各个bits,1是黑色,0是白色。如果遇到了上面的非数据区,则绕开或跳过。
掩码图案
这样下来,我们的图就填好了,但是,也许那些点并不均衡,如果出现大面积的空白或黑块,会告诉我们扫描识别的困难。所以,我们还要做Masking操作(靠,还嫌不复杂)QR的Spec中说了,QR有8个Mask你可以使用,如下所示:其中,各个mask的公式在各个图下面。所谓mask,说白了,就是和上面生成的图做XOR操作。Mask只会和数据区进行XOR,不会影响功能区。(注:选择一个合适的Mask也是有算法的)
其Mask的标识码如下所示:(其中的i,j分别对应于上图的x,y)
下面是Mask后的一些样子,我们可以看到被某些Mask XOR了的数据变得比较零散了。
Mask过后的二维码就成最终的图了。
好了,大家可以去尝试去写一下QR的编码程序,当然,你可以用网上找个Reed Soloman的纠错算法的库,或是看看别人的源代码是怎么实现这个繁锁的编码。
Recast NavigationSoloMesh源码分析(三)——行走面过滤
本文是对SoloMesh源码分析系列文章的第三部分,主题为行走面过滤。此阶段的处理是对体素化后Heightfield的修正和标记,旨在优化导航网格的构建过程。
行走面过滤分为三个主要步骤:过滤悬空的可走障碍物、过滤高度差过大的span以及过滤不可通过高度span。
首先,过滤悬空的可走障碍物通过函数rcFilterLowHangingWalkableObstacles实现。此过程识别上下两个体素,其中下体素可行走,而上体素不可行走。若上下两体素上表面相差不超过walkClimb,则将上体素标记为可行走。
接着,过滤高度差过大的span通过rcFilterLedgeSpans函数完成。此过程寻找如图所示的两种情况。首先,确保上span与下span与邻居的上span下span之间存在超过walkHeight的空隙,表明可通过一个agent的高度。然后,根据两种不同的情况,对体素进行判断,以解决转角台阶的识别问题。实际上,该步骤的目的是通过补充斜向体素的考虑,解决体素连接关系仅考虑4方邻居的问题。然而,该方法存在影响同方向体素的副作用,即图示的错误例子。解决这一问题的方法是排除同方向的两个体素比较。
最后,过滤不可通过高度span通过rcFilterWalkableLowHeightSpans实现。此过程检查上下两个span之间空隙,若小于等于walkHeight,则将下span标记为不可行走。
总结:代码逻辑相对简单,具体实现细节可直接在github的wcqdong/recastnavigation项目中查看源码注释,以深入理解此阶段的详细处理流程。