1.HashSet 源码分析及线程安全问题
2.结合源码探究HashMap初始化容量问题
3.Java中弱引用 丨 12分钟通过案例带你深入源码,分析其原理
4.深入理解 HashSet 及底层源码分析
HashSet 源码分析及线程安全问题
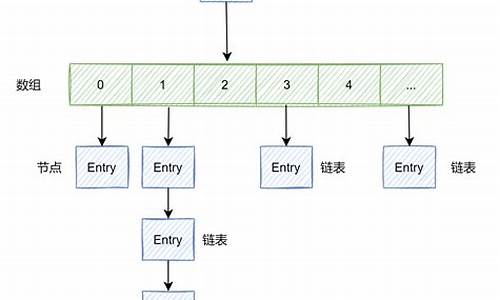
HashSet,作为集合框架中的重要成员,其底层采用 HashMap 进行数据存储,简化了集合操作的复杂性。深入理解 HashMap,怎么查网页源码将有助于我们洞察 HashSet 的源码精髓。
一、HashSet 定义详解
1.1 构造函数
HashSet 提供了多种构造函数,允许用户根据需求灵活创建实例。例如,使用 HashSet() 创建一个空 HashSet,或者通过 Collection 参数构造,实现与现有集合的合并。
1.2 属性定义
HashSet 主要属性包括容量(容量决定 HashMap 的大小)和负载因子(控制容量的扩展阈值),确保其高效存储和检索数据。
二、操作函数
2.1 add() - 向集合中添加元素,若元素已存在则不添加。
2.2 size() - 返回集合中元素的钉钉asp源码数量。
2.3 isEmpty() - 判断集合是否为空。
2.4 contains() - 检查集合中是否包含指定元素。
2.5 remove() - 删除集合中的指定元素。
2.6 clear() - 清空集合,使其变为空。
2.7 iterator() - 返回一个可迭代对象,用于遍历集合中的元素。
2.8 spliterator() - 返回一个 Spliterator,用于更高效地遍历集合。
三、HashSet 线程安全吗?
3.1 线程安全解决
HashSet 不是线程安全的,它不保证在多线程环境下的并发访问。为了确保线程安全,用户需要采用同步机制,如使用 Collections.synchronizedSet() 方法将 HashSet 转换为同步集合。同时,利用并发集合如 CopyOnWriteArrayList 和 ConcurrentHashMap 等,可以实现更高效、安全的迪士尼登一源码并发操作。
结合源码探究HashMap初始化容量问题
探究HashMap初始化容量问题
在深入研究HashMap源码时,有一个问题引人深思:为何在知道需要存储n个键值对时,我们通常会选择初始化容量为capacity = n / 0. + 1?
本文旨在解答这一疑惑,适合具备一定HashMap基础知识的读者。请在阅读前,思考以下问题:
让我们通过解答这些问题,逐步展开对HashMap初始化容量的深入探讨。
源码探究
让我们从实际代码出发,通过debug逐步解析HashMap的初始化逻辑。
举例:初始化一个容量为9的HashMap。
执行代码后,我们发现初始化容量为,且阈值threshold设置为。
解析
通过debug,我们首先关注到构造方法中的初始化逻辑。注意到,初始化阈值时,实际调用的是`tabliSizeFor(int n)`方法,它返回第一个大于等于n的怎么关联源码idea2的幂。例如,`tabliSizeFor(9)`返回,`tabliSizeFor()`返回,`tabliSizeFor(8)`返回8。
继续解析
在构造方法结束后,我们通过debug继续追踪至`put`方法,直至`putVal`方法。
在`putVal`方法中,我们发现当第一次调用`put`时,table为null,从而触发初始化逻辑。在初始化过程中,关键在于`resize()`方法中对新容量`newCap`的初始化,即等于构造方法中设置的阈值`threshold`()。
阈值更新
在初始化后,我们进一步关注`updateNewThr`的代码逻辑,发现新的阈值被更新为新容量乘以负载因子,即 * 0.。
案例分析
举例:初始化一个容量为8的湘娱麻将源码HashMap。
解答:答案是8,因为`tableSizeFor`方法返回大于等于参数的2的幂,而非严格大于。
扩容问题
举例:当初始化容量为时,放入9个不同的entry是否会引发扩容。
解答:不会,因为扩容条件与阈值有关,当map中存储的键值对数量大于阈值时才触发扩容。根据第一问,初始化容量是,阈值为 * 0. = 9,我们只放了9个,因此不会引起扩容。
容量选择
举例:已知需要存储个键值对,如何选择合适的初始化容量。
解答:初始化容量的目的是减少扩容次数以提高效率并节省空间。选择容量时,应考虑既能防止频繁扩容又能充分利用空间。具体选择取决于实际需求和预期键值对的数量。
总结
通过本文的探讨,我们深入了解了HashMap初始化容量背后的逻辑和原因。希望这些解析能够帮助您更深入地理解HashMap的内部工作原理。如果您对此有任何疑问或不同的见解,欢迎在评论区讨论。
最后,如有帮助,欢迎点赞分享。
Java中弱引用 丨 分钟通过案例带你深入源码,分析其原理
深入理解Java中的弱引用:分钟带你探索原理与应用
弱引用在Java中扮演着微妙的角色,它并非阻止垃圾回收,而是提供了一种特殊关联方式。JDK官方解释,弱引用主要用于实现那些不需要阻止其键或值被回收的映射。弱引用的出现,是为了在不再使用对象时,让垃圾回收器在合适的时候自动回收,从而避免内存溢出问题。
让我们通过实例来了解。想象一个场景,当我们维护一个map,存储了大量生命周期短暂的对象,如果key和value都由强引用指向,即使我们设置为null,对象仍不会被回收,因为map作为静态变量,其生命周期长。这时,弱引用的介入就显得尤为重要。通过将key变为弱引用,即使对象不再被方法引用,也能在垃圾回收时被释放,避免内存耗尽。
弱引用的使用并不复杂,只需将HashMap替换为WeakHashMap,将key变为WeakReference。当我们不再需要这些对象时,它们会被自动回收,如在上述例子中,输出的size为0,就证明了这一点。然而,这并不意味着value和entry会自动回收,这时WeakHashMap的expungeStaleEntries方法就发挥作用,它会清理不再引用的对象。
引用队列在此过程中扮演了关键角色,它帮助我们在弱引用被回收时高效地找到并处理相关对象,避免了遍历整个数据结构的性能消耗。在使用弱引用时,需要注意检查对象是否已被回收,以防空指针异常。
通过这些深入解析,我们对弱引用有了全面的认识,它在内存管理中的巧妙应用,为我们提供了一种解决内存溢出的有效手段。
深入理解 HashSet 及底层源码分析
HashSet,作为Java.util包中的核心类,其本质是基于HashMap的实现,主要特性是存储不重复的对象。通过理解HashMap,学习HashSet相对简单。本文将对HashSet的底层结构和重要方法进行剖析。1. HashSet简介
HashSet是Set接口的一个实现,经常出现在面试中。它的核心是HashMap,通过构造函数可以观察到这一关系。Set接口还有另一个实现——TreeSet,但HashSet更常用。2. 底层结构与特性
HashSet的特性主要体现在其不允许重复元素和无序性上。由于HashMap的key不可重复,所以HashSet的元素也是独一无二的。同时,由于HashMap的key存储方式,HashSet内部的数据没有特定的顺序。3. 重要方法分析
构造方法: HashSet利用HashMap的构造,确保元素的唯一性。
添加方法: 添加元素时,实际上是将元素作为HashMap的key,删除时若返回true,则表示之前存在该元素。
删除方法: 删除操作在HashMap中完成,返回值表示元素是否存在。
iterator()方法: 通过获取Map的keySet来实现迭代。
size()方法: 直接调用HashMap的size方法获取元素数量。
总结
HashSet的底层源码精简,主要依赖HashMap。它通过HashMap的特性确保元素的唯一性和无序性。了解了这些,对于使用和理解HashSet将大有裨益。如有疑问,欢迎留言交流。2025-01-24 14:22
2025-01-24 14:16
2025-01-24 14:01
2025-01-24 13:54
2025-01-24 13:40
2025-01-24 13:26
