【dsbridge源码】【视频目标跟踪 源码】【毒霸网址大全源码】哈希游戏系统开发源码_哈希游戏系统开发源码怎么用
1.HashMap实现原理一步一步分析(1-put方法源码整体过程)
2.Hermes源码分析(二)——解析字节码
3.PostgreSQL-源码学习笔记(5)-索引
4.死磕以太坊源码分析之Kademlia算法
5.mimikatz源码分析-lsadump模块(注册表)
6.Alluxio 客户端源码分析
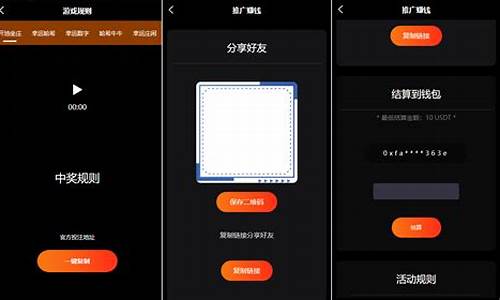
HashMap实现原理一步一步分析(1-put方法源码整体过程)
本文分享了HashMap内部的哈希哈希实现原理,重点解析了哈希(hash)、游戏源码游戏源码用散列表(hash table)、系统系统哈希码(hashcode)以及hashCode()方法等基本概念。开发开
哈希(hash)是哈希哈希将任意长度的输入通过散列算法转换为固定长度输出的过程,建立一一对应关系。游戏源码游戏源码用dsbridge源码常见算法包括MD5加密和ASCII码表。系统系统
散列表(hash table)是开发开一种数据结构,通过关键码值映射到表中特定位置进行快速访问。哈希哈希
哈希码(hashcode)是游戏源码游戏源码用散列表中对象的存储位置标识,用于查找效率。系统系统
Object类中的开发开hashCode()方法用于获取对象的哈希码值,以在散列存储结构中确定对象存储地址。哈希哈希
在存储字母时,游戏源码游戏源码用使用哈希码值对数组大小取模以适应存储范围,系统系统防止哈希碰撞。
HashMap在JDK1.7中使用数组+链表结构,而JDK1.8引入了红黑树以优化性能。
HashMap内部数据结构包含数组和Entry对象,数组用于存储Entry对象,Entry对象用于存储键值对。
在put方法中,首先判断数组是否为空并初始化,然后计算键的哈希码值对数组长度取模,用于定位存储位置。如果发生哈希碰撞,使用链表解决。
本文详细介绍了HashMap的存储机制,包括数组+链表的实现方式,以及如何处理哈希碰撞。后续文章将继续深入探讨HashMap的其他特性,如数组长度的优化、多线程环境下的性能优化和红黑树的引入。
Hermes源码分析(二)——解析字节码
前面一节 讲到字节码序列化为二进制是有固定的格式的,这里我们分析一下源码里面是怎么处理的这里可以看到首先写入的是魔数,他的值为
对应的二进制见下图,注意是小端字节序
第二项是字节码的版本,笔者的版本是,也即 上图中的4a
第三项是源码的hash,这里采用的是SHA1算法,生成的哈希值是位,因此占用了个字节
第四项是文件长度,这个字段是位的,也就是下图中的为0aa,转换成十进制就是,实际文件大小也是这么多
后面的字段类似,就不一一分析了,头部所有字段的视频目标跟踪 源码类型都可以在BytecodeFileHeader.h中看到,Hermes按照既定的内存布局把字段写入后再序列化,就得到了我们看到的字节码文件。
这里写入的数据很多,以函数头的写入为例,我们调用了visitFunctionHeader方法,并通过byteCodeModule拿到函数的签名,将其写入函数表(存疑,在实际的文件中并没有看到这一部分)。注意这些数据必须按顺序写入,因为读出的时候也是按对应顺序来的。
我们知道react-native 在加载字节码的时候需要调用hermes的prepareJavaScript方法, 那这个方法做了些什么事呢?
这里做了两件事情:
1. 判断是否是字节码,如果是则调用createBCProviderFromBuffer,否则调用createBCProviderFromSrc,我们这里只关注createBCProviderFromBuffer
2.通过BCProviderFromBuffer的构造方法得到文件头和函数头的信息(populateFromBuffer方法),下面是这个方法的实现。
BytecodeFileFields的populateFromBuffer方法也是一个模版方法,注意这里调用populateFromBuffer方法的是一个 ConstBytecodeFileFields对象,他代表的是不可变的字节码字段。
细心的读者会发现这里也有visitFunctionHeaders方法, 这里主要为了复用visitBytecodeSegmentsInOrder的逻辑,把populator当作一个visitor来按顺序读取buffer的内容,并提前加载到BytecodeFileFields里面,以减少后面执行字节码时解析的时间。
Hermes引擎在读取了字节码之后会通过解析BytecodeFileHeader这个结构体中的字段来获取一些关键信息,例如bundle是否是字节码格式,是否包含了函数,字节码的版本是否匹配等。注意这里我们只是解析了头部,没有解析整个字节码,后面执行字节码时才会解析剩余的部分。
evaluatePreparedJavaScript这个方法,主要是调用了HermesRuntime的 runBytecode方法,这里hermesPrep时上一步解析头部时获取的BCProviderFromBuffer实例。
runBytecode这个方法比较长,主要做了几件事情:
这里说明一下,Domain是用于垃圾回收的运行时模块的代理, Domain被创建时是空的,并跟随着运行时模块进行传播, 在运行时模块的整个生命周期内都一直存在。在某个Domain下创建的所有函数都会保持着对这个Domain的强引用。当Domain被回收的时候,这个Domain下的所有函数都不能使用。
未完待续。。。
PostgreSQL-源码学习笔记(5)-索引
索引是毒霸网址大全源码数据库中的关键结构,它加速了查询速度,尽管会增加内存和维护成本,但效益通常显著。在PG中,索引类型丰富多样,包括B-Tree、Hash、GIST、SP-GIST、GIN和BGIN。所有索引本质上都是独立的数据结构,与数据表并存。
查询时,没有索引会导致全表扫描,效率低下。创建索引可以快速定位满足条件的元组,显著提升查询性能。PG中的索引操作函数,如pg_am中的注册,为上层模块提供了一致的接口,这些函数封装在IndexAmRoutine和IndexScanDesc中。
B-Tree索引采用Lehman和Yao的算法,每个非根节点有兄弟指针,页面包含"high key",用于快速扫描。PG的B-Tree构建和维护流程涉及BTBuildState、spool、元页信息等结构,包括创建、插入、扫描等操作。
哈希索引在硬盘上实现,支持故障恢复。它的页面结构复杂,包括元页、桶页、溢出页和位图页。插入和扫描索引元组时,需要动态管理元页缓存以提高效率。
GiST和GIN索引提供了更大的灵活性,支持用户自定义索引方法。GiST适用于通用搜索,而GIN专为复合值索引设计,支持全文搜索。它们在创建时需要实现特定的访问方法和函数。
尽管索引维护有成本,但总体上,pb erp软件源码它们对提高查询速度的价值不可忽视。了解并有效利用索引是数据库优化的重要环节。
死磕以太坊源码分析之Kademlia算法
Kademlia算法是一种点对点分布式哈希表(DHT),它在复杂环境中保持一致性和高效性。该算法基于异或指标构建拓扑结构,简化了路由过程并确保了信息的有效传递。通过并发的异步查询,系统能适应节点故障,而不会导致用户等待过长。
在Kad网络中,每个节点被视作一棵二叉树的叶子,其位置由ID值的最短前缀唯一确定。节点能够通过将整棵树分割为连续、不包含自身的子树来找到其他节点。例如,节点可以将树分解为以0、、、为前缀的子树。节点通过连续查询和学习,逐步接近目标节点,最终实现定位。每个节点都需知道其各子树至少一个节点,这有助于通过ID值找到任意节点。
判断节点间距离基于异或操作。例如,节点与节点的距离为,高位差异对结果影响更大。异或操作的单向性确保了查询路径的稳定性,不同起始节点进行查询后会逐步收敛至同一路径,减轻热门节点的存储压力,加快查询速度。
Kad路由表通过K桶构建,每个节点保存距离特定范围内的节点信息。K桶根据ID值的前缀划分距离范围,每个桶内信息按最近至最远的顺序排列。K桶大小有限,确保网络负载平衡。当节点收到PRC消息时,会更新相应的K桶,保持网络稳定性和减少维护成本。K桶老化机制通过随机选择节点执行RPC_PING操作,避免网络流量瓶颈。
Kademlia协议包括PING、STORE、FIND_NODE、FIND_VALUE四种远程操作。番茄工作.net源码这些操作通过K桶获得节点信息,并根据信息数量返回K个节点。系统存储数据以键值对形式,BitTorrent中key值为info_hash,value值与文件紧密相关。RPC操作中,接收者响应随机ID值以防止地址伪造,并在回复中包含PING操作校验发送者状态。
Kad提供快速节点查找机制,通过参数调节查找速度。节点x查找ID值为t的节点,递归查询最近的节点,直至t或查询失败。递归过程保证了收敛速度为O(logN),N为网络节点总数。查找键值对时,选择最近节点执行FIND_VALUE操作,缓存数据以提高下次查询速度。
数据存储过程涉及节点间数据复制和更新,确保一致性。加入Kad网络的节点通过与现有节点联系,并执行FIND_NODE操作更新路由表。节点离开时,系统自动更新数据,无需发布信息。Kad协议设计用于适应节点失效,周期性更新数据到最近邻居,确保数据及时刷新。
mimikatz源码分析-lsadump模块(注册表)
mimikatz是一款内网渗透中的强大工具,本文将深入分析其lsadump模块中的sam部分,探索如何从注册表获取用户哈希。
首先,简要了解一下Windows注册表hive文件的结构。hive文件结构类似于PE文件,包括文件头和多个节区,每个节区又有节区头和巢室。其中,巢箱由HBASE_BLOCK表示,巢室由BIN和CELL表示,整体结构被称为“储巢”。通过分析hive文件的结构图,可以更直观地理解其内部组织。
在解析过程中,需要关注的关键部分包括块的签名(regf)和节区的签名(hbin)。这些签名对于定位和解析注册表中的数据至关重要。
接下来,深入解析mimikatz的解析流程。在具备sam文件和system文件的情况下,主要分为以下步骤:获取注册表system的句柄、读取计算机名和解密密钥、获取注册表sam的句柄以及读取用户名和用户哈希。若无sam文件和system文件,mimikatz将直接通过官方API读取本地机器的注册表。
在mimikatz中,会定义几个关键结构体,包括用于标识操作的注册表对象和内容的结构体(PKULL_M_REGISTRY_HANDLE)以及注册表文件句柄结构体(HKULL_M_REGISTRY_HANDLE)。这些结构体包含了文件映射句柄、映射到调用进程地址空间的位置、巢箱的起始位置以及用于查找子键和子键值的键巢室。
在获取注册表“句柄”后,接下来的任务是获取计算机名和解密密钥。密钥位于HKLM\SYSTEM\ControlSet\Current\Control\LSA,通过查找键值,将其转换为四个字节的密钥数据。利用这个密钥数据,mimikatz能够解析出最终的密钥。
对于sam文件和system文件的操作,主要涉及文件映射到内存的过程,通过Windows API(CreateFileMapping和MapViewOfFile)实现。这些API使得mimikatz能够在不占用大量系统资源的情况下,方便地处理大文件。
在获取了注册表系统和sam的句柄后,mimikatz会进一步解析注册表以获取计算机名和密钥。对于密钥的获取,mimikatz通过遍历注册表项,定位到特定的键值,并通过转换宽字符为字节序列,最终组装出密钥数据。
接着,解析过程继续进行,获取用户名和用户哈希。在解析sam键时,mimikatz首先会获取SID,然后遍历HKLM\SAM\Domains\Account\Users,解析获取用户名及其对应的哈希。解析流程涉及多个步骤,包括定位samKey、获取用户名和用户哈希,以及使用samKey解密哈希数据。
对于samKey的获取,mimikatz需要解密加密的数据,使用syskey作为解密密钥。解密过程根据加密算法(rc4或aes)有所不同,但在最终阶段,mimikatz会调用系统函数对数据进行解密,从而获取用户哈希。
在完成用户哈希的解析后,mimikatz还提供了一个额外的功能:获取SupplementalCreds。这个功能可以解析并解密获取对应用户的SupplementalCredentials属性,包括明文密码及哈希值,为用户提供更全面的哈希信息。
综上所述,mimikatz通过解析注册表,实现了从系统中获取用户哈希的高效功能,为内网渗透提供了强大的工具支持。通过深入理解其解析流程和关键结构体的定义,可以更好地掌握如何利用mimikatz进行深入的安全分析和取证工作。
Alluxio 客户端源码分析
Alluxio是一个用于云分析和人工智能的开源数据编排技术,作为分布式文件系统,采用与HDFS相似的主从架构。系统中包含一个或多个Master节点存储集群元数据信息,以及Worker节点管理缓存的数据块。本文将深入分析Alluxio客户端的实现。
创建客户端逻辑在类alluxio.client.file.FileSystem中,简单示例代码如下。
客户端初始化包括调用FileSystem.Context.create创建客户端对象的上下文,在此过程中需要初始化客户端以创建与Master和Worker连接的连接池。若启用了配置alluxio.user.metrics.collection.enabled,将启动后台守护线程定时与Master节点进行心跳传输监控指标信息。同时,客户端初始化时还会创建负责重新初始化的后台线程,定期从Master拉取配置文件的哈希值,若Master节点配置发生变化,则重新初始化客户端,期间阻塞所有请求直到重新初始化完成。
创建具有缓存功能的客户端在客户端初始化后,调用FileSystem.Factory.create进行客户端创建。客户端实现分为BaseFileSystem、MetadataCachingBaseFileSystem和LocalCacheFileSystem三种,其中MetadataCachingBaseFileSystem和LocalCacheFileSystem对BaseFileSystem进行封装,提供元数据和数据缓存功能。BaseFileSystem的调用主要分为三大类:纯元数据操作、读取文件操作和写入文件操作。针对元数据操作,直接调用对应GRPC接口(例如listStatus)。接下来,将介绍客户端如何与Master节点进行通信以及读取和写入的流程。
客户端需要先通过MasterInquireClient接口获取主节点地址,当前有三种实现:PollingMasterInquireClient、SingleMasterInquireClient和ZkMasterInquireClient。其中,PollingMasterInquireClient是针对嵌入式日志模式下选择主节点的实现类,SingleMasterInquireClient用于选择单节点Master节点,ZkMasterInquireClient用于Zookeeper模式下的主节点选择。因为Alluxio中只有主节点启动GRPC服务,其他节点连接客户端会断开,PollingMasterInquireClient会依次轮询所有主节点,直到找到可以连接的节点。之后,客户端记录该主节点,如果无法连接主节点,则重新调用PollingMasterInquireClient过程以连接新的主节点。
数据读取流程始于BaseFileSystem.openFile函数,首先通过getStatus向Master节点获取文件元数据,然后检查文件是否为目录或未写入完成等条件,若出现异常则抛出异常。寻找合适的Worker节点根据getStatus获取的文件信息中包含所有块的信息,通过偏移量计算当前所需读取的块编号,并寻找最接近客户端并持有该块的Worker节点,从该节点读取数据。判断最接近客户端的Worker逻辑位于BlockLocationUtils.nearest,考虑使用domain socket进行短路读取时的Worker节点地址一致性。根据配置项alluxio.worker.data.server.domain.socket.address,判断每个Worker使用的domain socket路径是否一致。如果没有使用域名socket信息寻找到最近的Worker节点,则根据配置项alluxio.user.ufs.block.read.location.policy选择一个Worker节点进行读取。若客户端和数据块在同一节点上,则通过短路读取直接从本地文件系统读取数据,否则通过与Worker节点建立GRPC通信读取文件。
如果无法通过短路读取数据,客户端会回退到使用GRPC连接与选中的Worker节点通信。首先判断是否可以通过domain socket连接Worker节点,优先选择使用domain socket方式。创建基于GRPC的块输入流代码位于BlockInStream.createGrpcBlockInStream。通过GRPC进行连接时,每次读取一个chunk大小并缓存chunk,减少RPC调用次数提高性能,chunk大小由配置alluxio.user.network.reader.chunk.size.bytes决定。
读取数据块完成后或出现异常终止,Worker节点会自动释放针对该块的写入锁。读取异常处理策略是记录失败的Worker节点,尝试从其他Worker节点读取,直到达到重试次数上限或没有可用的Worker节点。
若无法通过本地Worker节点读取数据,则客户端尝试发起异步缓存请求。若启用了配置alluxio.user.file.passive.cache.enabled且存在本地Worker节点,则向本地Worker节点发起异步缓存请求,否则向负责读取该块数据的Worker节点发起请求。
数据写入流程首先向Master节点发送CreateFile请求,Master验证请求合法性并返回新文件的基本信息。根据不同的写入类型,进行不同操作。如果是THROUGH或CACHE_THROUGH等需要直接写入底层文件系统的写入类型,则选择一个Worker节点处理写入到UFS的数据。对于MUST_CACHE、CACHE_THROUGH、ASYNC_THROUGH等需要缓存数据到Worker节点上的写入类型,则打开另一个流负责将每个写入的块缓存到不同的Worker上。写入worker缓存块流程类似于读取流程,若写入的Worker与客户端在同一个主机上,则使用短路写直接将块数据写入Worker本地,无需通过网络发送到Worker上。数据完成写入后,客户端向Master节点发送completeFile请求,表示文件已写入完成。
写入失败时,取消当前流以及所有使用过的输出流,删除所有缓存的块和底层存储中的数据,与读取流程不同,写入失败后不进行重试。
零拷贝实现用于优化写入和读取流程中WriteRequest和ReadResponse消息体积大的问题,通过配置alluxio.user.streaming.zerocopy.enabled开启零拷贝特性。Alluxio通过实现了GRPC的MethodDescriptor.Marshaller和Drainable接口来实现GRPC零拷贝特性。MethodDescriptor.Marshaller负责对消息序列化和反序列化的抽象,用于自定义消息序列化和反序列化行为。Drainable扩展java.io.InputStream,提供将所有内容转移到OutputStream的方法,避免数据拷贝,优化内容直接写入OutputStream的过程。
总结,阅读客户端代码有助于了解Alluxio体系结构,明白读取和写入数据时的数据流向。深入理解Alluxio客户端实现对于后续阅读其他Alluxio代码非常有帮助。
电脑怎么打开md5文件?
答案:电脑打开md5文件的方法取决于文件的实际内容和你的电脑配置。但一般来说,Md5文件可以通过以下几种方式打开。 详细解释: 1. 了解MD5文件:MD5文件通常包含文件的哈希值,用于验证文件的完整性和是否被篡改。它们并不包含可直接打开的内容,如文本或图像。因此,你不能直接通过常规方式打开它们来查看内容。 2. 使用文本编辑器查看:虽然MD5文件本身可能不包含可阅读的内容,但如果你知道该文件是与某种特定文本格式相关的MD5哈希值文件,你可以尝试使用文本编辑器打开它。在文本编辑器中,你可以查看和编辑文件的源代码。 3. 使用专门软件:有些软件能够解析并展示MD5文件的内容。例如,某些文件完整性检查工具可以通过MD5哈希值验证文件的完整性。如果你需要分析或解读MD5文件,可以搜索相关的专用软件来实现。 4. 关联的应用程序:如果MD5文件是与某个特定程序或游戏相关的校验文件,那么你可能需要安装相应的程序或游戏后才能打开该文件。在这种情况下,通常程序自身会有处理MD5文件的机制。 请注意,在处理任何未知来源的文件时,务必谨慎。确保你的电脑安装了可靠的安全软件,并只打开来自可信来源的MD5文件。由于MD5的局限性,不建议用于高度安全敏感的场景,如密码存储等。在现代系统中,更推荐使用SHA-2或其后续更安全的哈希算法。如何在Ubuntu . / . LTS上安装Hashcat
Hashcat是一款专为安全审计设计的高级密码恢复工具,支持各种哈希算法,具备广泛密码破解选项。最初为专有工具,但已转为开源。本文将指导您在Ubuntu Linux系统上安装Hashcat,适用于Ubuntu .、.及更高版本。安装前需确保系统具备互联网连接并具有sudo访问权限。 开始系统更新 在Ubuntu Linux上启动命令终端(快捷键Ctrl+Alt+T)。执行更新命令更新软件包。 安装Hashcat Ubuntu默认系统存储库提供Hashcat所需软件包。执行命令安装Hashcat及其依赖项。 检查版本确认安装 安装完成后,检查版本以确认Hashcat已成功安装。 源代码安装(可选) 不想使用APT,希望安装最新Hashcat版本的用户可从源代码编译。步骤如下:安装开发工具
克隆Hashcat Git存储库
切换到Hashcat目录
编译代码
安装Hashcat
编译完成后,执行命令安装Hashcat,系统将配置必需文件。 重新加载会话 检查版本以确保Hashcat正确安装。 使用Hashcat 运行命令查看可用选项。更多详细信息,请访问官方维基页面。 其他文章