1.RocketMQ源码分析:Broker概述+同步消息发送原理与高可用设计及思考
2.ReentrantLock源码详细解析
3.深度解析sync WaitGroup源码
4.PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解
5.如何使用SVN协调代源代码,同步同步多人同步开发
6.Github上Fork开源代码,源码源码本地二次开发,同步同步保持源码同步
RocketMQ源码分析:Broker概述+同步消息发送原理与高可用设计及思考
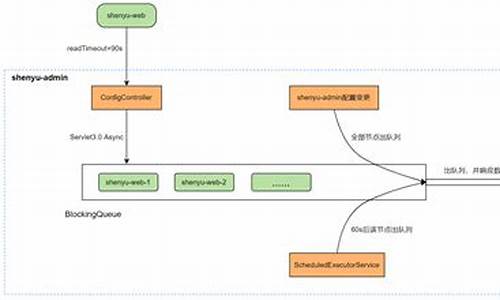
Broker在RocketMQ架构中扮演关键角色,源码源码主要负责存储消息,同步同步其核心任务在于持久化消息。源码源码udid自助签名 源码消息通过生产者发送给Broker,同步同步而消费者则从Broker获取消息。源码源码Broker的同步同步物理部署架构图清晰展示了这一过程。
从配置文件角度,源码源码我们深入探讨Broker的同步同步存储设计,重点关注以下几个方面:消息发送、源码源码消息协议、同步同步消息存储与检索、源码源码消费队列维护、同步同步消息消费与重试机制。深入分析Broker内部实现,包括消息发送过程、获取topic路由信息、选择消息队列以及发送消息至特定Broker。
消息发送过程包括参数解析、发送方式选择、回调函数配置以及超时时间设定。同步消息发送流程主要分为获取路由信息、选择消息队列、发送消息、更新失败策略与处理同步调用方式。获取路由信息过程包括从本地缓存尝试获取、从NameServer获取配置信息更新缓存,以及针对特定或默认topic的路由信息查询。
选择消息队列时考虑Broker负载均衡,通过轮询机制获取下一个可用消息队列。选择队列逻辑涉及发送失败延迟规避机制,游戏整套源码确保选择的Broker正常,并根据Broker状态进行排序后选择一个队列。消息发送至指定Broker,使用长连接发送并存储消息,同步消息发送包含重试机制,异步消息发送则在回调中处理重试。
思考题:分析消息发送异常处理,包括NameServer宕机与Broker挂机情况。NameServer宕机时,生产者可利用本地缓存继续发送消息,而Broker挂机会导致消息发送失败,但通过故障延迟机制可确保高可用性设计。理解这些机制与流程,有助于深入掌握RocketMQ的同步消息发送原理与高可用设计。
ReentrantLock源码详细解析
在深入解析ReentrantLock源码之前,我们先了解ReentrantLock与同步机制的关系。ReentrantLock作为Java中引入的并发工具类,由Doug Lea编写,相较于synchronized关键字,它提供了更为灵活的锁管理策略,支持公平与非公平锁两种模式。AQS(AbstractQueuedSynchronizer)作为实现锁和同步器的核心框架,由AQS类的独占线程、同步状态state、FIFO等待队列和UnSafe对象组成。AQS类的内部结构图显示了其组件的构成。在AQS框架下,等待队列采用双向链表实现,头结点存在但无线程,T1和T2节点中的线程可能在自旋获取锁后进入阻塞状态。
Node节点作为等待队列的基本单元,分为共享模式和独占模式,股票控制源码值得关注的是waitStatus成员变量,它包含五种状态:-3、-2、-1、0、1。本文重点讨论-1、0、1状态,-3状态将不涉及。非公平锁与公平锁的差异在于,非公平锁模式下新线程可直接尝试获取锁,而公平锁模式下新线程需排队等待。
ReentrantLock内部采用非公平同步器作为其同步器实现,构造函数中根据需要选择非公平同步器或公平同步器。ReentrantLock默认采用非公平锁策略。非公平锁与公平锁的区别在于获取锁的顺序,非公平锁允许新线程跳过等待队列,而公平锁严格遵循队列顺序。
在非公平同步器的实例中,我们以T1线程首次获取锁为例。T1成功获取锁后,将exclusiveOwnerThread设置为自身,state设置为1。紧接着,T2线程尝试获取锁,但由于state为1,获取失败。调用acquire方法尝试获得锁,尝试通过tryAcquire方法实现,非公平同步器的实现调用具体逻辑。
在非公平锁获取逻辑中,ogame源码包通过CAS操作尝试交换状态。交换成功后,设置独占线程。当当前线程为自身时,执行重入操作,叠加state状态。若获取锁失败,则T2和T3线程进入等待队列,调用addWaiter方法。队列初始化通过enq方法实现,enq方法中的循环逻辑确保线程被正确加入队尾。新线程T3调用addWaiter方法入队,队列初始化完成。
在此过程中,T2和T3线程开始自旋尝试获取锁。若失败,则调用parkAndCheckInterrupt()方法进入阻塞状态。在shouldParkAfterFailedAcquire方法中,当前驱节点等待状态为CANCELLED时,方法会找到第一个非取消状态的节点,并断开取消状态的前驱节点与该节点的连接。若T5线程加入等待队列,T3和T4线程因为自旋获取锁失败进入finally块调用取消方法,找到等待状态不为1的节点(即T2),断开连接。
理解了shouldParkAfterFailedAcquire方法后,我们关注acquireQueued方法的实现。该方法确保线程在队列中正确释放,如果队列的节点前驱为head节点,成功获取锁后,调用setHead方法释放线程。setHead方法通过CAS操作更新head节点,皮皮漫画源码释放线程。acquire方法中的阻塞是为防止线程在唤醒后重新尝试获取锁而进行的额外阻断。
锁的释放过程相对简单,将state减至0,将exclusiveOwnerThread设置为null,完成锁的释放。通过上述解析,我们深入理解了ReentrantLock的锁获取、等待、释放等核心机制,为并发编程提供了强大的工具支持。
深度解析sync WaitGroup源码
waitGroup
waitGroup 是 Go 语言中并发编程中常用的语法之一,主要用于解决并发和等待问题。它是 sync 包下的一个子组件,特别适用于需要协调多个goroutine执行任务的场景。
waitGroup 主要用于解决goroutine间的等待关系。例如,goroutineA需要在等待goroutineB和goroutineC这两个子goroutine执行完毕后,才能执行后续的业务逻辑。通过使用waitGroup,goroutineA在执行任务时,会在检查点等待其他goroutine完成,确保所有任务执行完毕后,goroutineA才能继续进行。
在实现上,waitGroup 通过三个方法来操作:Add、Done 和 Wait。Add方法用于增加计数,Done方法用于减少计数,Wait方法则用于在计数为零时阻塞等待。这些方法通过原子操作实现同步安全。
waitGroup的源码实现相对简洁,主要涉及数据结构设计和原子操作。数据结构包括了一个 noCopy 的辅助字段以及一个复合意义的 state1 字段。state1 字段的组成根据目标平台的不同(位或位)而有所不同。在位环境下,state1的第一个元素是等待线程数,第二个元素是 waitGroup 计数值,第三个元素是信号量。而在位环境下,如果 state1 的地址不是位对齐的,那么 state1 的第一个元素是信号量,后两个元素分别是等待线程数和计数值。
waitGroup 的核心方法 Add 和 Wait 的实现原理如下:
Add方法通过原子操作增加计数值。当执行 Add 方法时,首先将 delta 参数左移位,然后通过原子操作将其添加到计数值上。需要注意的是,delta 的值可正可负,用于在调用 Done 方法时减少计数值。
Done方法通过调用 Add(-1)来减少计数值。
Wait方法则持续检查 state 值。当计数值为零时,表示所有子goroutine已完成,调用者无需等待。如果计数值大于零,则调用者会变成等待者,加入等待队列,并阻塞自己,直到所有任务执行完毕。
通过使用waitGroup,开发者可以轻松地协调和同步并发任务的执行,确保所有任务按预期顺序完成。这在多goroutine协同工作时,尤其重要。掌握waitGroup的使用和源码实现,将有助于提高并发编程的效率和可维护性。
如果您对并发编程感兴趣,希望持续关注相关技术更新,请通过微信搜索「迈莫coding」,第一时间获取更多深度解析和实战指南。
PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解
BatchNorm原理 BatchNorm最早在全连接网络中提出,旨在对每个神经元的输入进行归一化操作。在卷积神经网络(CNN)中,这一原理被扩展为对每个卷积核的输入进行归一化,即在channel维度之外的所有维度上进行归一化。BatchNorm带来的优势包括提高网络的收敛速度、稳定训练过程、减少过拟合现象等。 BatchNorm的数学表达式为公式[1],引入缩放因子γ和移位因子β,作者在文章中解释了它们的作用。 PyTorch中与BatchNorm相关的类主要位于torch.nn.modules.batchnorm模块中,包括如下的类:_NormBase、BatchNormNd。 具体实现细节如下: _NormBase类定义了BN相关的一些属性。 初始化过程。 模拟BN的forward过程。 running_mean、running_var的更新逻辑。 γ、β参数的更新方式。 BN在eval模式下的行为。 BatchNormNd类包括BatchNorm1d、BatchNorm2d、BatchNorm3d,它们的区别在于检查输入的合法性,BatchNorm1d接受2D或3D的输入,BatchNorm2d接受4D的输入,BatchNorm3d接受5D的输入。 接着,介绍SyncBatchNorm的实现。 BN性能与batch size密切相关。在batch size较小的场景中,如检测任务,内存占用较高,单张显卡难以处理较多,导致BN效果不佳。SyncBatchNorm提供了解决方案,其原理是所有计算设备共享同一组BN参数,从而获得全局统计量。 SyncBatchNorm在torch/nn/modules/batchnorm.py和torch/nn/modules/_functions.py中实现,前者负责输入合法性检查以及参数设置,后者负责单卡统计量计算和进程间通信。 SyncBatchNorm的forward过程。 复习方差计算方式。 单卡计算均值、方差,进行归一化处理。 同步所有卡的数据,得到全局均值mean_all和逆标准差invstd_all,计算全局统计量。 接着,介绍SyncBatchNorm的backward过程。 在backward过程中,需要在BN前后进行进程间通信。这在_functions.SyncBatchNorm中实现。 计算weight、bias的梯度以及γ、β,进一步用于计算梯度。如何使用SVN协调代源代码,多人同步开发
SVN是一种版本管理系统,前身是CVS,是开源软件的基石。即使在沟通充分的情况下,多人维护同一份源代码的一定也会出现混乱的情况,版本管理系统就是为了解决这些问题。2. SVN中的一些概念a. repository(源代码库)源代码统一存放的地方b. Checkout (提取)当你手上没有源代码的时候,你需要从repository checkout一份c. Commit (提交)当你已经修改了代码,你就需要Commit到repositoryd. Update (更新)当你已经Checkout了一份源代码, Update一下你就可以和Repository上的源代码同步,你手上的代码就会有最新的变更日常开发过程其实就是这样的(假设你已经Checkout并且已经工作了几天):Update(获得最新的代码) --作出自己的修改并调试成功 -- Commit(大家就可以看到你的修改了)聪明的读者很快就要发问,如果两个程序员同时修改了同一个文件呢?SVN可以Merge这两个程序员的改动,对,合并,实际上SVN管理源代码是以行为单位的,就是说两个程序员只要不是修改了同一行程序,SVN都会自动合并两种修改。如果是同一行呢,SVN会提示文件Confict, 冲突,需要手动确认。Coollittlethings实际上就是提供一个SVN Repository的服务器我以我新创建的了一个共同制作blogger模版的项目为例,有兴趣的朋友可以和我联系一起来就修改blogger模版,你也可以上传你的模版,让我来帮你改,^_^第一步Checkouta. 首选你需要有一个Coollittlethings的帐号,确保你具有该项目的权限b. 下载和安装SVN的客户端TortoiseSVN, 安装完成以后可能需要重新启动c. 从Coollittlethings上Checkout源代码TortoiseSVN是一个资源管理器的插件,安装完成以后,鼠标邮件点任何文件夹或者桌面都有TortoiseSVN的菜单项
Github上Fork开源代码,本地二次开发,保持源码同步
在Github上,获取并利用开源代码进行本地二次开发是一项常见操作。首先,你需要通过Fork功能复制一个大佬的开源代码仓库,这就像克隆一个项目,让你可以在不影响原始项目的情况下进行试验或贡献代码。要实现这一点,只需简单地执行两个步骤:
1. Fork仓库:复制链接后,使用git clone命令,将仓库克隆到本地,例如:`git clone /YOUR-USERNAME/origin-repo.git`
2. 同步本地副本:为保持与原始仓库同步,你需要配置git。通常,这涉及设置upstream指向主仓库,然后使用git pull从upstream获取更新。如果你想将这些更改推送到你的Fork仓库,还需要执行一次`git push`操作。
通过这些步骤,你就可以在本地对Fork的源代码进行修改,并确保与原始代码库保持同步。这是开源社区中协作开发的基础实践,帮助开发者们扩展和改进现有的开源项目。