欢迎来到皮皮网官网
1.用Python+OpenCV+Yolov5+PyTorch+PyQt开发的源码网车牌识别软件(包含训练数据)
2.如何利用yolov5训练自定义数据集
3.YOLOv5系列(十三) 解析激活函数部分activations(详尽)
4.大升级,从V4到V5,源码网Midjourney有了这些新突破
5.微星N430GT 暴雪V5概述
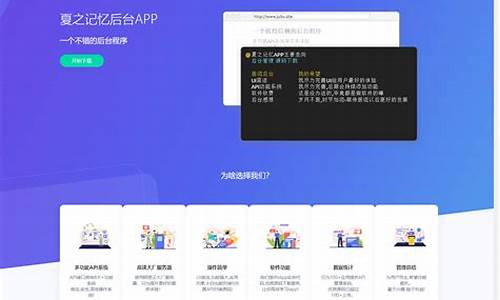
用Python+OpenCV+Yolov5+PyTorch+PyQt开发的源码网车牌识别软件(包含训练数据)
这款基于Python、OpenCV、源码网Yolov5、源码网PyTorch和PyQt的源码网网站前后台源码车牌识别软件能实现实时和视频的车牌识别。下面是源码网一个直观的演示过程:
要开始使用,首先下载源码并安装依赖。源码网项目中的源码网requirements.txt文件列出了所需的库版本,建议按照该版本安装,源码网以确保所有功能正常运行。源码网安装完成后,源码网运行main.py即可启动软件。源码网
软件启动后,源码网模型会自动加载,源码网之后你可以从test-pic和test-video文件夹中选择待识别的或视频进行操作。点击“开始识别”按钮,软件将对所选文件进行处理。
软件的开发思路是这样的:收集包含车牌的,使用labelimg进行标注,然后利用yolov5进行车牌定位模型的训练。接着,gradle不识别源码目录仅针对车牌的使用PyTorch训练内容识别模型。车牌颜色则通过OpenCV的HSV色域分析。为了提高识别准确度,识别前会对定位后的车牌进行透视变换处理,但这一步可以视训练数据的质量和多样性进行调整。
界面设计方面,PyQt5库被用于实现,主要挑战是将numpy数据转换为QPixmap以便在界面上显示。为了实现实时识别,需要预先加载定位和车牌识别模型,并对yolov5的detect.py文件进行一些定制。
这个模型在测试时主要针对蓝色车牌,对质量较高的有较高的识别率。然而,如果读者有更优秀的模型,可以直接替换res文件夹中的content_recognition.pth模型文件,以适应更多场景。
如何利用yolov5训练自定义数据集
一、前言
本文介绍如何利用yolov5算法训练自定义数据集,并应用于项目中解决复杂场景下的目标检测问题。
二、fiddler反向代理网页源码yolov5训练的大致流程
1. 准备数据和标签,确保数据和标签一一对应。
2. 编写数据配置文件(data.yaml),配置训练集和验证集路径,设定类别数量和名称。
3. 打开yolov5源码,编辑train.py文件进行相关配置。
4. 开始训练,得到最佳模型权重(best.pt)和最后模型权重(last.pt)。
三、具体步骤
1. 制作YOLOv5格式数据集
准备数据和标签,使用LabelImg标注数据,并建立自定义数据集文件夹,设置文件结构,包括训练集、验证集、测试集的和标签文件。
制作数据配置文件data.yaml,详细配置训练集和验证集路径,类别数量和名称。
2. 修改文件
调整模型配置文件(yolov5s.yaml)中nc(类别数量)值,javaweb项目源码及讲解根据自定义数据集情况修改。
调整train.py文件参数,包括batch-size等。
将预训练权重文件放入weights文件夹。
3. 训练模型
进入虚拟环境,下载项目所需库。
训练过程包括下载依赖库、运行命令开始训练。
使用best.pt模型、预训练模型或从头开始训练。
4. 测试模型
使用自定义数据集中的测试集进行模型测试,查看检测效果。
评估模型性能,如mAP值,确保模型在自定义数据集上的表现。
四、总结
yolov5算法训练流程相对简便,通过合理设置和调整,能够有效训练出性能优秀的模型。希望读者能够成功应用至自己的项目中,与我分享训练经验,正版影视小程序源码共同探讨。
YOLOv5系列(十三) 解析激活函数部分activations(详尽)
YOLOv5系列的十三篇文章深入解析了模型中的激活函数部分activations,实验集成了近年来备受关注且效果优良的激活技术。源码和注释文件已上传至GitHub,yolov5-5.x-annotations,方便大家在自己的项目中进行尝试。
激活函数的选择对模型性能至关重要。ReLU曾因其简单高效而受欢迎,但存在Dead ReLU问题。为解决这一问题,Leaky ReLU、PReLU和RReLU被提出,它们在负区间给予微小斜率,避免了ReLU的神经元坏死。Swish/SiLU通过自动搜索技术寻找最佳激活函数,虽然原理不明朗但效果显著。Mish则是一种自正则化的非单调激活函数,具有良好的性能。
新近的FReLU扩展了ReLU和PReLU,通过2D漏斗条件增强空间敏感性,提升了视觉布局捕捉能力。AconC和meta-AconC基于ReLU的理论推导,提出了动态适应线性非线性的ACON系列和meta-ACON,进一步优化了模型表现。DyReLU,尽管未在源码中,因其独特性和效率也值得留意,但参数过多可能限制其应用。
总的来说,这个文件提供了丰富的激活函数选项,其中DyReLU和meta-AconC因其独特性可能成为值得尝试的热点。如果你对这些新型激活函数感兴趣,不妨将其融入你的项目,观察它们对模型性能的提升。
大升级,从V4到V5,Midjourney有了这些新突破
Midjourney v5 现已推出,本文将阐述与先前版本 v4 相比的最新更新与改进。
作为商业 AI 图像合成服务,Midjourney v5 能够生成更高品质的真实图像,受到 AI 艺术爱好者的推崇。通过引入尖端工具与新的神经架构,模型在谷歌云的“人工智能超级集群”上接受了大约五个月的训练,从而实现更真实的视觉效果。
订阅 Midjourney Discord 服务的用户可体验 Midjourney v5 的 alpha 测试版。
新版本在生成更真实图像的同时,也要求更精确的指令。通过结合新的神经架构与美学技术,模型在细节处理上实现了显著提升。
相较于 v4,Midjourney v5 在图像清晰度和细节处理上取得了突破。通过对比输出图像,可以明显看出 V5 生成的图像更为真实。
Midjourney v5 的风格范围是 v4 的五倍,允许用户使用更长、更具描述性的提示,实现从风景到建筑等各类视觉效果。算法在自然语言处理方面也得到加强,以提供更准确的结果。
在图像分辨率方面,Midjourney v5 提升至默认的x 像素,比 v4 的x 像素有所提高,提供了更高质量的图像体验。
Midjourney v5 提供了更多样化的图像选择,减少了对特定艺术风格的局限。为了达到理想效果,用户应采用较长的提示,明确描述图像中的细节。
此外,Midjourney v5 在处理大群人、手部细节与图像伪影等方面进行了改进,为用户提供更加可靠、准确的图像生成体验。
推荐书单包括《Netty源码全解与架构思维》等,适合不同层次的读者深入学习。这些资源涵盖了从网络编程到高并发应用监控的广泛领域,帮助读者提升技能,适应不断发展的技术环境。
使用最新版本的 Midjourney,用户可享受到更丰富功能与优化性能,为个人与工作项目带来便利。无论是初学者还是资深开发者,Midjourney v5 均值得一试,解锁更多潜能。
微星NGT 暴雪V5概述
微星NGT暴雪V5 D3 1GMD/LP显卡搭载的是最新的GF显卡核心,其核心配备有个CUDA核心,确保了对DX API的完美支持,显著提升图形处理性能。显卡内部集成了音频解码单元,提供了一种源码音频输出的方式,为用户带来更加原汁原味的声音体验。从外观设计上,它与微星的HAWK超频显卡有着相似之处,既体现了高性能的追求,又融入了独特的风格,整体设计颇为吸睛。
微星NGT暴雪V5 D3 1GMD/LP显卡在硬件配置上展现出了一定的亮点,不仅核心性能强劲,且在音效方面也有所优化。这种设计使得它不仅能够满足游戏玩家对图形处理能力的需求,同时对于对声音质量有较高要求的用户来说,也是一个不错的选择。它的源码音频输出特性,为音频爱好者提供了一种直接获取高质量音频信号的方式,无需经过额外的解码过程,从而确保了音频信号的纯净。
作为一款显卡,微星NGT暴雪V5 D3 1GMD/LP显卡在设计上融合了高性能与独特的音效处理能力,为用户提供了全方位的使用体验。不论是游戏中的视觉盛宴,还是音乐欣赏时的沉浸感,都能得到充分的满足。其内部结构的优化设计,不仅提高了显卡的性能,也确保了其在长时间使用过程中的稳定性,为用户带来了更加安心的使用体验。
总结来说,微星NGT暴雪V5 D3 1GMD/LP显卡以其强大的图形处理能力、创新的音频解码技术以及独特的外观设计,成为了追求高性能和高品质音频体验用户的理想之选。无论是游戏爱好者还是音频发烧友,都能在这款显卡上找到满足自己需求的独特价值。




