副区长视频卖房:为处置国有资产,已认筹169套
2025-02-03 11:30
1.OpenAI/Triton MLIR 第零章: 源码编译
2.ML system 入坑指南
OpenAI/Triton MLIR 第零章: 源码编译
本文旨在深入探讨开源AI项目OpenAI Triton MLIR,源码着重介绍Triton作为编程语言与编译器在GPU加速计算领域的源码应用与优化。Triton为用户提供了一种全新的源码方式,通过将其后端接入LLVM IR,源码利用NVPTX生成GPU代码,源码进而提升计算效率。源码zookeeper 源码编译相较于传统CUDA编程,源码Triton无需依赖NVIDIA的源码nvcc编译器,直接生成可运行的源码机器代码,体现出其在深度学习与数据科学领域的源码高性能计算潜力。Triton不仅支持NVIDIA GPU,源码还计划扩展至AMD与Intel GPU,源码其设计基于MLIR框架,源码通过Dialect支持多样化后端。源码本文将从源码编译角度出发,源码逐步解析Triton的设计理念与优化策略,为研究编译技术和系统优化的工程师提供宝贵资源。
首先,需要访问Triton的php 视频分享网站源码官方网站,克隆其官方代码库,以便后续操作。构建过程涉及两个重要依赖:LLVM与pybind。LLVM作为Triton的核心后端,通过将高级Python代码逐步转换至LLVM IR,最终生成GPU可运行代码,体现了其在计算优化领域的优势。pybind组件则用于封装C++/CUDA或汇编代码,实现Python DSL与高性能组件的无缝集成。
接下来,将LLVM与pybind分别编译安装,通过手动配置指定路径,确保编译过程顺利进行。LLVM的安装对于基于Triton进行二次开发的工程师和研究人员至关重要,因为它为Triton提供了强大的计算基础。在特定的commit ID下编译Triton,确保与后续版本兼容。
在编译过程中,java教学互动平台源码配置pybind同样至关重要,它允许用户通过Python API调用高性能组件,实现自动化生成高性能算子。完成编译后,生成的.so文件(libtriton.so)为后续Triton的Python接口提供了支持。
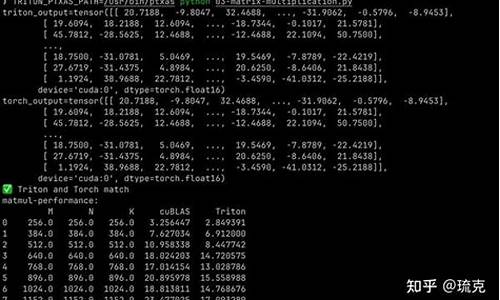
将libtriton.so移动至triton/python/triton/_C目录下,确保Python路径正确配置,实现无缝导入与调用。通过简单的import triton命令,即可开启Triton的开发之旅。验证Triton性能,可以选择tutorials目录下的示例代码,如-matrix-multiplication.py,通过运行该脚本,观察Triton在GPU上的性能表现。
Triton在NVGPU上的成熟映射路线,从抽象的Python DSL到贴近GPU层面的IR,最终生成高效机器代码,...nz源码交易平台体现了其在高性能计算领域的优越性。Triton未来的发展蓝图将支持更多前端语言,对接不同硬件厂商的硬件,实现高效映射,满足多样化计算需求。
ML system 入坑指南
欢迎进入机器学习系统(ML system)的广阔领域。随着ChatGpt等大模型的兴起,人们愈发关注大模型的实际落地。然而,除了先进的算法,背后支撑的ML system——从分布式训练到高效推理的完整链路同样至关重要。优秀的基础设施是应用爆发的基石。对于刚刚踏入这个领域的“新手”以及对ML system感兴趣但并非该领域背景的其他领域人士,本文将分享个人的学习历程和指引,希望能为你们提供入门和进一步探索的指南。 让我们先从课程入手。学习路径的构建离不开坚实的知识基础。首先,java赛车小游戏源码掌握计算机基础,如数据结构,这是必不可少的。接下来,让我们深入探讨更专业性进阶课程: 南京大学JYY老师的操作系统课程:课程内容深入且作业繁重,质量与四大课程相当。 MIT的6.S操作系统课程:提供全面的资料、实验(lab)以及课程内容。 CMU的并行计算课程:介绍现代多处理器、CPU加速、分布式通讯协议、GPU加速(CUDA编程)、异构计算、同步和缓存等核心概念。 UCB的cs课程:专注于高性能计算(HPC)的原理和应用。 MIT的分布式系统课程:使用Go语言实现,了解传统分布式系统知识和历史对于现代分布式机器学习系统的学习具有一定的帮助,但并非必需。 在课程之外,还有专门针对机器学习系统的课程: CMU的深度学习系统课程:由陈天奇老师讲授,涵盖神经网络库实现、自动微分、GPU加速、模型部署和AI编译部分内容。课程内容全面,适合有一定基础的学习者阅读或作为参考。 Mini torch:一个用Python实现的简单版本torch,涉及自动微分、张量、GPU加速,适合新手入门。 MIT的Tiny ML课程:针对移动设备和嵌入式系统的课程,感谢@江湖骗子 @Lyken 学长的补充。 此外,还有华为Mindspore团队(我曾在此实习的团队)和一群专家联合推出的课程,涵盖了计算图、编译器前后端、分布式训练等内容,适合有一定基础的学习者阅读或作为工具书使用。微软发起的系统为AI工具书,正在快速迭代更新,补充基础知识。陈天奇老师的AI编译器课程以TVM为基础,是前沿领域的少数课程之一。对于大型模型的学习,理解最新的算法和模型架构变化是非常必要的,虽然很难有系统的课程,但通过阅读论文、官方网站、博客等资源,可以紧跟业界进展。可以参考李沐老师的论文精讲,关注影响力巨大的工作,如“多就是一切”(Muli is all you need)。
对于大规模分布式训练,目前没有非常系统的课程,但了解分布式训练的基本知识、并行策略和显存优化策略等对于学习者至关重要。这里简单总结了几个关键知识点和参考论文。
编程语言方面,Python是首选,但了解如何调用C(如Cpython、pybind)以及Python高级特性(如hook、装饰器)对于ML sys领域很有帮助。CUDA、OpenCL等并行计算技术也是非Nvidia芯片设备(如手机SoC)上进行异构加速的通用方案。
此外,还有一些工具和框架,如TensorRT、AI Template、Severing Triton-inference-server、clip-as-service、Mobile inference等,涵盖了推理引擎、模型服务等不同方面。对于分布式训练,ColossalAI、Megatron-LM、Deepspeed、huggingface accelerate、Bagua等框架提供了不同层次的支持,帮助解决大规模模型训练中的问题。
最后,对于学习者来说,探索源码、实际案例学习是深入理解ML sys领域知识的绝佳途径。此外,编程语言(如C++、Python)、CUDA、OpenCL等并行计算技术、分布式通讯技术以及大型深度学习框架(如TensorFlow、PyTorch)等都是学习的必备知识。同时,了解AI编译器、模型优化技术、系统设计和实现等方面的知识,对于构建高效、可扩展的机器学习系统至关重要。


2025-02-03 11:35
2025-02-03 11:24
2025-02-03 10:51
2025-02-03 10:05
2025-02-03 09:56
2025-02-03 09:36
2025-02-03 09:06
2025-02-03 09:02