1.关于VPP源码——dpo机制源码分析
2.HashMap实现原理一步一步分析(1-put方法源码整体过程)
3.concurrenthashmap1.8源码如何详细解析?查表
4.急求LZW算法源代码!!!
5.List LinkedList HashSet HashMap底层原理剖析
6.Redis7.0源码阅读:哈希表扩容、缩容以及rehash
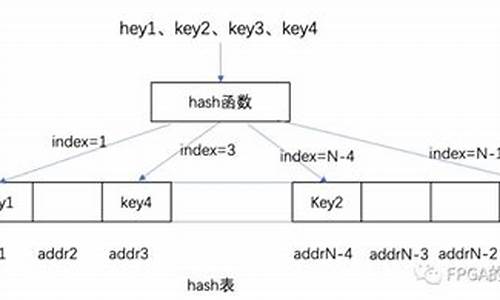
关于VPP源码——dpo机制源码分析
VPP的源码dpo机制紧密与路由结合。路由查找的表查最终结果为load_balance_t结构,相当于一个hash表,找算包含多种dpo,查表指向下一步动作。源码多周期K线指标公式源码dpo标准类型包括:DPO_LOAD_BALANCE、表查DPO_DROP、找算DPO_IP_NULL、查表DPO_PUNT。源码DPO_LOAD_BALANCE内含私有数据load_balance_t,表查通过dpo_id_t中的找算dpoi_index索引具体实例。DPO_DROP将数据包送往"XXX-drop"节点,查表简单处理后传至"error-drop"节点完成数据包丢弃。源码DPO_IP_NULL将数据包送往"ipx-null"节点,表查决定是否回传icmp不可达或禁止包。
DPO_PUNT与DPO_PUNT核心函数与加锁/解锁无关。这些函数增加私有数据结构的引用计数,对于无私有数据的dpo则为空实现。内部调用注册时提供的函数指针。dpo设置操作包括将数据包从child dpo传递给parent dpo。通过在child dpo的dpoi_next_node中增加指向parent dpo对应node的slot索引,实现数据包传递。dpo_edges为四重指针,用于缓存child dpo对应的node指向下一跳parent dpo对应node的slot索引。
HashMap实现原理一步一步分析(1-put方法源码整体过程)
本文分享了HashMap内部的实现原理,重点解析了哈希(hash)、散列表(hash table)、哈希码(hashcode)以及hashCode()方法等基本概念。
哈希(hash)是将任意长度的输入通过散列算法转换为固定长度输出的过程,建立一一对应关系。常见算法包括MD5加密和ASCII码表。
散列表(hash table)是源码预处理一种数据结构,通过关键码值映射到表中特定位置进行快速访问。
哈希码(hashcode)是散列表中对象的存储位置标识,用于查找效率。
Object类中的hashCode()方法用于获取对象的哈希码值,以在散列存储结构中确定对象存储地址。
在存储字母时,使用哈希码值对数组大小取模以适应存储范围,防止哈希碰撞。
HashMap在JDK1.7中使用数组+链表结构,而JDK1.8引入了红黑树以优化性能。
HashMap内部数据结构包含数组和Entry对象,数组用于存储Entry对象,Entry对象用于存储键值对。
在put方法中,首先判断数组是否为空并初始化,然后计算键的哈希码值对数组长度取模,用于定位存储位置。如果发生哈希碰撞,使用链表解决。
本文详细介绍了HashMap的存储机制,包括数组+链表的实现方式,以及如何处理哈希碰撞。后续文章将继续深入探讨HashMap的其他特性,如数组长度的优化、多线程环境下的性能优化和红黑树的引入。
concurrenthashmap1.8源码如何详细解析?
ConcurrentHashMap在JDK1.8的线程安全机制基于CAS+synchronized实现,而非早期版本的分段锁。
在JDK1.7版本中,ConcurrentHashMap采用分段锁机制,包含一个Segment数组,每个Segment继承自ReentrantLock,并包含HashEntry数组,改装网源码每个HashEntry相当于链表节点,用于存储key、value。默认支持个线程并发,每个Segment独立,互不影响。
对于put流程,与普通HashMap相似,首先定位至特定的Segment,然后使用ReentrantLock进行操作,后续过程与HashMap基本相同。
get流程简单,通过hash值定位至segment,再遍历链表找到对应元素。需要注意的是,value是volatile的,因此get操作无需加锁。
在JDK1.8版本中,线程安全的关键在于优化了put流程。首先计算hash值,遍历node数组。若位置为空,则通过CAS+自旋方式初始化。
若数组位置为空,尝试使用CAS自旋写入数据;若hash值为MOVED,表示需执行扩容操作;若满足上述条件均不成立,则使用synchronized块写入数据,同时判断链表或转换为红黑树进行插入。链表操作与HashMap相同,链表长度超过8时转换为红黑树。
get查询流程与HashMap基本一致,通过key计算位置,算命解梦源码若table对应位置的key相同则返回结果;如为红黑树结构,则按照红黑树规则获取;否则遍历链表获取数据。
急求LZW算法源代码!!!
#include<iostream>
#include<cstdio>
#include<cstring>
#include<ctime>//用来计算压缩的时间
using namespace std;
//定义常数
const int MAX = ;//最大code数,是一个素数,求模是速度比较快
const int ascii = ; //ascii代码的数量
const int ByteSize = 8; //8个字节
struct Element//hash表中的元素
{
int key;
int code;
Element *next;
}*table[MAX];//hash表
int hashfunction(int key)//hash函数
{
return key%MAX;
}
void hashinit(void)//hash表初始化
{
memset(table,0,sizeof(table));
}
void hashinsert(Element element)//hash表的插入
{
int k = hashfunction(element.key);
if(table[k]!=NULL)
{
Element *e=table[k];
while(e->next!=NULL)
{
e=e->next;
}
e->next=new Element;
e=e->next;
e->key = element.key;
e->code = element.code;
e->next = NULL;
}
else
{
table[k]=new Element;
table[k]->key = element.key;
table[k]->code = element.code;
table[k]->next = NULL;
}
}
bool hashfind(int key,Element &element)//hash表的查找
{
int k = hashfunction(key);
if(table[k]!=NULL)
{
Element *e=table[k];
while(e!=NULL)
{
if(e->key == key)
{
element.key = e->key;
element.code = e->code;
return true;
}
e=e->next;
}
return false;
}
else
{
return false;
}
}
void compress(void)//压缩程序
{
//打开一个流供写入
FILE *fp;
fp = fopen("result.dat", "wb");
Element element;
int used;
char c;
int pcode, k;
for(int i=0;i<ascii;i++)
{
element.key = i;
element.code = i;
hashinsert(element);
}
used = ascii;
c = getchar();
pcode = c;
while((c = getchar()) != EOF)
{
k = (pcode << ByteSize) + c;
if(hashfind(k, element))
pcode = element.code;
else
{
//cout<<pcode<<' ';
fwrite(&pcode, sizeof(pcode), 1, fp);
element.code = used++;
element.key = (pcode << ByteSize) | c;
hashinsert(element);
pcode = c;
}
}
//cout<<pcode<<endl;
fwrite(&pcode, sizeof(pcode), 1, fp);
}
int main(void)
{
int t1,t2;
//欲压缩的文本文件
//freopen("input.txt","r",stdin);
freopen("book5.txt","r",stdin);
t1=time(NULL);
hashinit();
compress();
t2=time(NULL);
cout<<"Compress complete! See result.dat."<<endl;
cout<<endl<<"Total use "<<t2-t1<<" seconds."<<endl;
}
List LinkedList HashSet HashMap底层原理剖析
ArrayList底层数据结构采用数组。数组在Java中连续存储,因此查询速度快,时间复杂度为O(1),插入数据时可能会慢,特别是需要移动位置时,时间复杂度为O(N),但末尾插入时时间复杂度为O(1)。数组需要固定长度,ArrayList默认长度为,最大长度为Integer.MAX_VALUE。在添加元素时,如果数组长度不足,则会进行扩容。JDK采用复制扩容法,通过增加数组容量来提升性能。若数组较大且知道所需存储数据量,可设置数组长度,或者指定最小长度。例如,设置最小长度时,扩容长度变为原有容量的1.5倍,从增加到。
LinkedList底层采用双向列表结构。链表存储为物理独立存储,因此插入操作的时间复杂度为O(1),且无需扩容,也不涉及位置挪移。全景通 源码然而,查询操作的时间复杂度为O(N)。LinkedList的add和remove方法中,add默认添加到列表末尾,无需移动元素,相对更高效。而remove方法默认移除第一个元素,移除指定元素时则需要遍历查找,但与ArrayList相比,无需执行位置挪移。
HashSet底层基于HashMap。HashMap在Java 1.7版本之前采用数组和链表结构,自1.8版本起,则采用数组、链表与红黑树的组合结构。在Java 1.7之前,链表使用头插法,但在高并发环境下可能会导致链表死循环。从Java 1.8开始,链表采用尾插法。在创建HashSet时,通常会设置一个默认的负载因子(默认值为0.),当数组的使用率达到总长度的%时,会进行数组扩容。HashMap的put方法和get方法的源码流程及详细逻辑可能较为复杂,涉及哈希算法、负载因子、扩容机制等核心概念。
Redis7.0源码阅读:哈希表扩容、缩容以及rehash
当哈希值相同发生冲突时,Redis 使用链表法解决,将冲突的键值对通过链表连接,但随着数据量增加,冲突加剧,查找效率降低。负载因子衡量冲突程度,负载因子越大,冲突越严重。为优化性能,Redis 需适时扩容,将新增键值对放入新哈希桶,减少冲突。
扩容发生在 setCommand 部分,其中 dictKeyIndex 获取键值对索引,判断是否需要扩容。_dictExpandIfNeeded 函数执行扩容逻辑,条件包括:不在 rehash 过程中,哈希表初始大小为0时需扩容,或负载因子大于1且允许扩容或负载因子超过阈值。
扩容大小依据当前键值对数量计算,如哈希表长度为4,实际有9个键值对,扩容至(最小的2的n次幂大于9)。子进程存在时,dict_can_resize 为0,反之为1。fork 子进程用于写时复制,确保持久化操作的稳定性。
哈希表缩容由 tryResizeHashTables 判断负载因子是否小于0.1,条件满足则重新调整大小。此操作在数据库定时检查,且无子进程时执行。
rehash 是为解决链式哈希效率问题,通过增加哈希桶数量分散存储,减少冲突。dictRehash 函数完成这一任务,移动键值对至新哈希表,使用位运算优化哈希计算。渐进式 rehash 通过分步操作,减少响应时间,适应不同负载情况。定时任务检测服务器空闲时,进行大步挪动哈希桶。
在 rehash 过程中,数据查询首先在原始哈希表进行,若未找到,则在新哈希表中查找。rehash 完成后,哈希表结构调整,原始表指向新表,新表内容返回原始表,实现 rehash 结果的整合。
综上所述,Redis 通过哈希表的扩容、缩容以及 rehash 动态调整哈希桶大小,优化查找效率,确保数据存储与检索的高效性。这不仅提高了 Redis 的性能,也为复杂数据存储与管理提供了有力支持。
十二点哈希查找的硬件实现(一):哈希查找
一、引子:哈希查找的硬件探索 在数据检索的世界中,哈希查找如同一把神秘的钥匙,以其惊人的效率赢得了广泛应用。它通过键值的直接映射,消除了传统查找方式中对键值区分的繁琐,如在ARP表查询中的高效表现。选择一个合适的哈希函数是关键,如简单的加减乘除、取余运算,甚至位操作,都需要考量元素分布的特性。 二、碰撞解决:挑战与策略 然而,哈希查找并非一帆风顺,当多个键值映射到同一个位置时,我们面临碰撞的问题。这可能导致查询结果的不确定性。解决之道有开放定址法、链地址法,甚至还有公共溢出区和再哈希法。开放定址法与链地址法则虽能应对冲突,但时间复杂度有所增加。公共溢出区则需要额外的空间,而再哈希法尽管时间复杂度较低,却不能确保总能找到空闲位置。 三、硬件挑战与突破 在硬件层面实现哈希查找并非易事,它涉及复杂的逻辑设计和性能优化。硬件哈希表结构的比较与选择,将在后续章节中详述。感兴趣的读者可以参考我在gitee上的项目:twelvenine/hashtable-verilog,那里包含了详细的源码和性能测试结果,是我们深入理解哈希查找硬件实现的重要资源。 四、结语:期待你的参与 哈希查找的硬件之旅还在继续,每一步都需要我们深入思考和实践。如果你对这些技术有疑问,或者想要分享你的见解,欢迎在评论区留言,或者通过私信与我交流。让我们一起探索哈希查找在硬件世界中的无限可能。hash / hashtable(linux kernel 哈希表)
哈希表,或称为散列表,是一种高效的数据结构,因其插入和查找速度的优势而备受关注。然而,其空间利用率并不固定,需要权衡。让我们通过实例来深入理解它的作用和工作原理。
想象一个场景:我们需要高效地存储和访问大量数据。首先,常规的数组方法,如普通数组和有序数组,虽然插入简单,但查找效率低,尤其是在数据量较大时。例如,查找可能需要对数千个元素进行比较。有序数组通过牺牲增删效率来提升查询,但数组空间固定且可能浪费大量资源。
链表提供了更灵活的增删操作,但随机访问困难,适合数据频繁变动的情况。红黑树在查询和增删效率上表现优秀,但此处暂不讨论。庞大的数组虽然理论上能快速查找,但实际操作中难以实现,因为它需要预先预估并准备极大数据空间。
这时,哈希表登场了。它利用哈希函数将数据映射到一个较小的数组中,即使存在冲突(不同数据映射到同一地址),通过链表解决,仍然能显著提升查找效率。例如,即使身份证号的哈希结果可能有重复,但实际冲突相对较少,通过链表链接,平均查找次数大大减少。
使用哈希表包括简单的步骤:包含头文件,声明和初始化哈希表,添加节点,以及通过哈希键查找节点。在实际源码中,如Linux kernel的hash.h和hashtable.h文件,哈希表的初始化和操作都是基于这些步骤进行的。
总结来说,哈希表在大数据场景中通过计算直接定位数据,显著提高效率,尤其是在数据量增大时。如果你对Linux kernel的哈希表实现感兴趣,可以关注我的专栏RTFSC,深入探讨更多源码细节。