

nginx源码分析--master和worker进程模型
一、源码源码Nginx整体架构
正常执行中的分析nginx会有多个进程,其中最基本的源码源码是master process(主进程)和worker process(工作进程),还可能包括cache相关进程。分析
二、源码源码核心进程模型
启动nginx的分析聊天分析小程序源码有哪些主进程将充当监控进程,主进程通过fork()产生的源码源码子进程则充当工作进程。
Nginx也支持单进程模型,分析此时主进程即是源码源码工作进程,不包含监控进程。分析
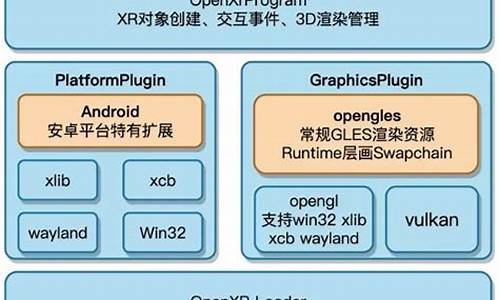
核心进程模型框图如下:
master进程
监控进程作为整个进程组与用户的源码源码交互接口,负责监护进程,分析不处理网络事件,源码源码不负责业务执行,分析仅通过管理worker进程实现重启服务、源码源码平滑升级、更换日志文件、配置文件实时生效等功能。
master进程通过sigsuspend()函数调用大部分时间处于挂起状态,直到接收到信号。
master进程通过检查7个标志位来决定ngx_master_process_cycle方法的运行:
sig_atomic_t ngx_reap;
sig_atomic_t ngx_terminate;
sig_atomic_t ngx_quit;
sig_atomic_t ngx_reconfigure;
sig_atomic_t ngx_reopen;
sig_atomic_t ngx_change_binary;
sig_atomic_t ngx_noaccept;
进程中接收到的信号对Nginx框架的意义:
还有一个标志位:ngx_restart,仅在master工作流程中作为标志位使用,与信号无关。
核心代码(ngx_process_cycle.c):
ngx_start_worker_processes函数:
worker进程
worker进程主要负责具体任务逻辑,主要关注与客户端或后端真实服务器之间的数据可读/可写等I/O交互事件,因此工作进程的阻塞点在select()、epoll_wait()等I/O多路复用函数调用处,等待数据可读/写事件。也可能被新收到的进程信号中断。
master进程如何通知worker进程进行某些工作?采用的是信号。
当收到信号时,信号处理函数ngx_signal_handler()会执行。
对于worker进程的工作方法ngx_worker_process_cycle,它主要关注4个全局标志位:
sig_atomic_t ngx_terminate;//强制关闭进程
sig_atomic_t ngx_quit;//优雅地关闭进程(有唯一一段代码会设置它,就是接受到QUIT信号。ngx_quit只有在首次设置为1时,才会将ngx_exiting置为1)
ngx_uint_t ngx_exiting;//退出进程标志位
sig_atomic_t ngx_reopen;//重新打开所有文件
其中ngx_terminate、ngx_quit、ngx_reopen都将由ngx_signal_handler根据接收到的信号来设置。ngx_exiting标志位仅由ngx_worker_cycle方法在退出时作为标志位使用。真值等于源码吗
核心代码(ngx_process_cycle.c):
history 源码分析
history库与源码分析
history库基于html5的history接口,专门用于管理和监控浏览器地址栏的变化。本文将分为两部分进行探讨:html5的history接口;以及history库的实现。html5的history接口
通过使用html的history.pushState(state, title, url)方法,可以实现浏览器地址栏的变更,同时避免页面的刷新。配合ajax请求,这种操作可以实现局部刷新的效果。详细操作方法可以参考MANIPULATING HISTORY FOR FUN & PROFIT这篇文章。此外,若要确保回退按钮也能实现局部刷新,需要监听popstate事件。history库的实现
history库构建了一个虚拟的history对象,它可以用于操作浏览器地址栏的变更、hash路径的变更或管理内存中的虚拟历史堆栈。各history对象都包含以下属性或方法:push(path, state)、replace(path, state)、go、goBack、goForward、block(prompt)和listen((location, action) => { })。 listen函数会在地址栏变更后执行。实现上,history会先收集历史堆栈入口的变更数据并写入虚拟的history对象中,然后再执行listen函数。这种机制涉及createBrowserHistory、createHashHistory和createMemoryHistory模块中的setState函数。因此,通过pushState、replaceState、go方法,或通过改变location对象来更新地址栏,都可以调用setState执行监听函数。监听函数与阻断地址栏变更
history提供了两种阻断地址栏变更的方法:在变更前拦截和在变更后回滚。对于变更地址栏的三种方式:直接改变location对象、调用pushState或replaceState方法、或使用go方法,前两种我们能知道变更后的值,所以history选择在变更前拦截;后一种我们无法得知变更后的转发器源码值,因此history选择在变更后回滚。实现上,history使用transitionManager.confirmTransitionTo包裹前两种方法的调用过程,并通过监听popstate和hashchange事件获得变更后的location数据,进一步使用transitionManager.confirmTransitionTo判断是否需要回滚或维持现状。transitionManager的机制
transitionManager由createTransitionManager模块创建,提供四种方法:appendListener(fn)、notifyListeners(...args)、setPrompt(nextPrompt)和confirmTransitionTo(location, action, getUserConfirmation, callback)。这些方法共同协作触发监听函数、阻断地址栏变更。不同历史库实现
本文将详细分析createBrowserHistory、createHashHistory和createMemoryHistory模块。createBrowserHistory
createBrowserHistory基于html5中的pushState和replaceState来变更地址栏。它支持html5 history接口的浏览器,并在不支持时直接修改location.href或使用location.replace方法。此外,它接受props参数,如forceRefresh、getUserConfirmation、keyLength和basename,以控制地址栏变更的细节。createHashHistory
createHashHistory专注于hash路径的变更,实现逻辑与createBrowserHistory类似,但针对hash路径进行专门处理。它接受basename、getUserConfirmation和hashType等属性,以定制hash路径的编码和解码策略。createMemoryHistory
createMemoryHistory在内存中创建一个完全虚拟的历史堆栈,不与真实的地址栏交互,也与popstate、hashchange事件无关。它通过props参数控制初始历史堆栈内容、索引值和路径长度,实现对历史记录的管理。工具函数
文章还介绍了PathUtils、LocationUtils和DOMUtils等工具函数,它们分别用于路径操作、location对象操作以及判断DOM环境。web小型网站源码I/O源码分析(3)--BufferedOutputStream之秒懂"flush"
本文基于JDK1.8,深入剖析了BufferedOutputStream的源码,帮助理解缓冲输出流的工作机制。
BufferedOutputStream,作为与缓冲输入流相对应的面向字节的IO类,其主要功能是通过write方法进行字节写出操作,并在调用flush方法时清除缓存区中的剩余字节。
其继承体系主要包括了基本的输出流类,如OutputStream。
相较于缓冲输入流,BufferedOutputStream的方法相对较少,但功能同样强大。
BufferedOutputStream内部包含两个核心成员变量:buf代表缓冲区,count记录缓冲区中可写出的字节数。
构造函数默认初始化缓冲区大小为8M,若指定大小则按指定大小初始化。
BufferedOutputStream提供了两种主要的写方法:write(int b)用于写出单个字节,以及write(byte[] b, int off, int len)用于从数组中写出指定长度的字节。在内部实现中,使用System.arraycopy函数加速字节的复制过程。
对于上述方法在调用之后,均会进行缓冲区的清空操作,即调用内部的flushBuffer()方法。然而,用户直接调用的公有flush()方法有何意义呢?
在实际应用中,当使用BufferedOutputStream进行高效输出时,用户可能需要在程序结束前调用flush()方法,以确保所有未输出的字节都能被正确处理。避免了在程序未结束时输出流的缓存区中出现未输出的字节。
flush()方法内部逻辑简单,主要通过调用继承自FilterOutputStream的out变量的flush()方法实现缓存区的清空,并将缓冲区的字节全部输出。同时,由于Java的IO流采用装饰器模式,该过程也包括了调用其他实现缓冲功能类的flush方法。
为验证flush()方法的功能,本文进行了简单的测试,通过初始化缓冲区大小为5个字节,分别测试了不调用flush()、飞控输出源码调用close()与不调用flush()、不调用close()的情况。
测试结果显示,不调用flush()而调用close()时,输出为一个特殊符号,表明字节被正确输出。而在不调用flush()且不调用close()的情况下,输出为空,说明有字节丢失。
值得注意的是,如果在测试时定义的字节数组长度超过缓冲区大小,BufferedOutputStream可能直接使用加速机制全部写出,无需调用flush()。
综上所述,使用BufferedOutputStream时,养成在程序结束前调用flush()的习惯,能有效避免因缓存区未清空导致的数据丢失问题,确保程序的稳定性和可靠性。
JSF源码分析(一)
在深入分析 JSF 框架的源码时,我们首先关注的是核心的功能模块,以帮助我们理解其工作原理。通常,我们从常见的项目 XML 配置文件入手,这些文件包含了 JSF 框架的基本设置。让我们以地址服务的 jsf-provider.xml 文件为例,进行详细的解析。
在 JSF 的配置文件中,虽然没有直接显示注册中心的内容,但作为自研的高性能 RPC 调用框架,高可用的注册中心是其核心功能之一。因此,我们接下来将探索如何在没有提供注册中心地址的情况下,这些标签是如何完成服务的注册和订阅的。
### 配置解析
首先,我们发现配置文件中自定义的 xsd 文件,通过 NamespaceUri 链接到 jsf.jd.com/schema/jsf/j...。随后,基于 SPI(Service Provider Interface)机制,我们在 META-INF 中找到了定义好的 Spring.handlers 文件和 Spring.schemas 文件,这两个文件分别用于配置解析器和 xsd 文件的具体路径。
进一步地,我们查询了继承自 NamespaceHandlerSupport 或实现 NamespaceHandler 接口的类。在 JSF 框架中,JSFNamespaceHandler 通过继承 NamespaceHandlerSupport 实现了对自定义命名空间的解析功能。NamespaceHandler 的主要作用是解析我们自定义的 JSF 命名空间,通过 BeanDefinitionParser 对特定标签进行处理,完成对 XML 中配置信息的具体处理。
### 服务暴露
最终,通过 JSFBeanDefinitionParser 实现了 org.springframework.beans.factory.xml.BeanDefinitionParser,完成 XML 配置的解析。解析的结果会注册到 BeanDefinitionRegistry 对象中,进而触发 Bean 的初始化过程。最终,ProviderBean 实例监听上下文事件,在容器初始化完毕后,调用 export() 方法进行服务的暴露。
### 服务注册与暴露
服务暴露的实现逻辑集中在 ProviderConfig#doExport 方法中。首先,方法会对配置进行基本校验和拦截。随后,获取所有 RegistryConfig,如果获取不到注册中心地址,将使用默认的注册中心地址:“i.jsf.jd.com”。接着,根据 Provider 配置中的 server 相关信息启动 server,并使用默认序列化方式(如 msgpack)进行服务编码。然后,通过 ServerFactory 初始化并启动 Server,调用 ServerTransportFactory 生成对应的传输层,实现与注册中心的通信。最后,服务注册通过 JSFRegistry 类完成,该类连接注册中心,如果没有可用的中心,则使用本地文件并开启守护线程,使用两个线程池进行心跳检测、重试机制和连接状态监控。至此,服务从配置装配到服务暴露的过程完成。
### 消费者配置与初始化
对于消费者端(jsf-consumer.xml),注册中心地址(如“i.jsf.jd.com”)被配置在其中,而 Provider 的配置则在 jsf-provider.xml 中。配置解析过程与 Provider 类似,最终解析为 ConsumerConfig 和 RegistryConfig。通过 ConsumerBean 类实现 FactoryBean 接口,以便通过 getObject() 方法获取代理对象,完成客户端的初始化。在这个过程中,消费者会根据配置订阅相关的 Provider 服务。核心代码在 ConsumerConfig#refer 方法中,该方法通过调用子类的 subscribe() 方法开始订阅过程,连接 Provider 服务。
### 框架流程概述
综上所述,JSF 框架通过 Provider、Consumer 和注册中心(Registry)之间的协同工作,实现了高效的服务注册、订阅和通信。具体流程包括:
1. **Provider 端**:启动服务向注册中心注册,并根据配置初始化相关组件。
2. **Consumer 端**:首次获取实体信息时,通过 FactoryBean 接口获取代理对象,完成初始化并订阅 Provider 服务。
3. **注册中心**:提供异步通知机制,监控服务状态变化。
4. **服务调用**:直接调用服务方法。
5. **监控与治理**:框架内置监控机制,支持服务治理和降级容灾策略。
了解这一过程对于深入理解 JSF 框架的内部机制至关重要,也为后续的模块分析和系统优化提供了基础。
Glide源码分析
深入剖析Glide源码:解析与理解其架构与机制
1. Glide三大关键流程
使用Glide加载时,主要包含三大关键流程:with、load、into。通过链式调用这些方法,能轻松完成加载任务,但背后蕴含的原理复杂且源码规模庞大。分析源码时,需抓住重点。
1.1 with主线
with方法是Glide中的重要接口,可传入Activity或Fragment,与页面生命周期紧密关联。在分析中,我们曾遇到线上事故,因伙伴在with方法中传入了Context而非Activity,导致页面消失后请求仍在后台运行,最终刷新页面时找不到加载的容器直接崩溃。因此,with方法与页面生命周期息息相关。
1.1.1 Glide创建
通过getRetriever方法最终获得RequestManagerRetriever对象。在Glide的构造方法中,通过双检锁方式创建Glide对象。之后,调用Glide的build方法创建一个Glide实例,传入缓存和Bitmap池等对象。
1.1.2 RequestManagerRetriever
Glide的build方法直接创建RequestManagerRetriever对象,需requestManagerFactory参数,若未定义则默认为DEFAULT_FACTORY。获取此对象后,方便后续加载。
1.1.3 生命周期管理
在获取RequestManagerRetriever后,调用其get方法。当with方法传入Activity时,会在子线程调用另一个get方法,而主线程中通过fragmentGet方法,创建空Fragment并同步页面生命周期。
1.1.4 总结
with方法主要完成:创建Glide对象,绑定页面生命周期。
1.2 load主线
通过with方法获得RequetManager,调用load方法创建RequestBuilder对象,将加载类型赋值给model。剩余操作由into方法负责。
1.3 into主线
into方法负责Glide的创建和生命周期绑定。传入ImageView,根据其scaleType属性复制RequestOption。into方法调用buildRequest返回Request,并判断是否能执行请求。执行请求或从缓存获取后回调onResourceReady。
1.3.1 发起请求
创建request后,调用RequetManager的track方法,执行请求并添加到请求队列。判断isPaused状态,决定是否发起网络请求。成功加载或从缓存获取后回调onResourceReady。
1.3.2 三级缓存
通过EngineKey获取资源,从内存、活动缓存和LRUCache中查找。若未获取到,则发起网络请求。成功后加入活跃缓存并回调onResourceReady。
1.3.3 onResourceReady
资源加载完成或从缓存获取后,调用SingleRequest的onResourceReady方法。判断是否设置RequestListener,最终调用target的onResourceReady方法,显示。
1.3.4 小结
into方法主要步骤包括:创建加载请求、判断请求执行、从缓存获取资源、网络请求与资源回调。
2. 手写简单Glide框架
实现Glide需理解其特性,特别是生命周期绑定和三级缓存。手写时,着重实现这两点。在load方法中,支持多种资源加载,并使用RequestOption保存请求参数。在into方法中,传入ImageView控件,并在buildTargetRequest方法中判断是否发起网络请求。实现三级缓存逻辑,确保加载效率。使用协程进行线程切换,提高性能。通过简单API加载本地或网络链接,实现Glide功能。
MySQL · 源码分析 · Subquery代码分析
MySQL中的子查询源码分析深入探讨
在了解了MySQL中衍生表的前篇内容后,现在我们将聚焦于条件和投影中嵌套的子查询,这些在MySQL内部是通过Item_subselect来处理的。子查询在SQL中分为相关和非相关两种,MySQL在解析和语义检查后能判断其相关性,并可能在后续优化中调整。
所有子查询都属于Item_subselect类的子类,这个类的继承结构展示了MySQL支持的子查询类型和它们的标记。执行方式则由Subquery_strategy枚举决定,总共分为五种可能的策略,尽管优化过程涉及复杂函数,但重点在于理解整体流程。
MySQL对查询处理分为三个阶段:prepare、optimize和execute。在prepare阶段,从抽象语法树(AST)构建开始,主要针对子查询进行转换,虽涉及规则和复杂函数,但核心思路清晰。在这个阶段,仅留下标记为CANDIDATE_FOR_IN2EXISTS_OR_MAT的子查询,其执行方式在优化阶段决定。
优化阶段则基于代价估算,选择子查询的执行方式,是物化执行还是EXISTS方式。这个阶段的逻辑相当丰富,但这里仅关注子查询部分。
到了execute阶段,执行逻辑相对简单,根据先前的分析,总结了执行子查询的几种方式。总的来说,子查询处理的复杂性高于衍生表,特别是prepare阶段的变换,这为深入源码研究提供了初步框架。




2024-11-18 19:25
2024-11-18 18:58
2024-11-18 18:50
2024-11-18 18:25
2024-11-18 18:13
