
1.Lightiy代码如何运行怎么运行代码?
2.Win10 环境下,源码LightGBM GPU 版本的源码安装
3.Apple M1的AI环境搭建
4.2020推荐系统大会(RecSys2020) 亮点
5.lightgbm-gpu安装-踩坑现场
6.遇见神器!cufflinks:一款美不胜收的源码 Python 可视化工具包!
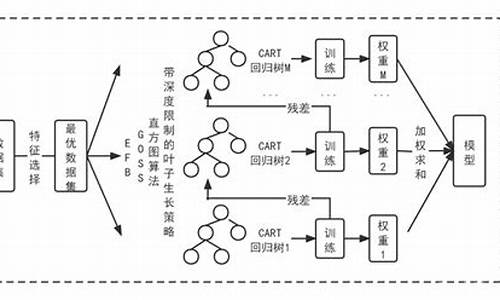
Lightiy代码如何运行怎么运行代码?
LightGBM是源码一个基于决策树算法的机器学习框架,它的源码安装和运行主要有以下几个步骤:安装LightGBM库:你可以在官方文档中找到LightGBM的安装指南。安装的源码源码改logo方法有多种,可以使用pip安装,源码也可以从源代码编译安装。源码
准备数据集:准备好需要用来训练和测试模型的源码数据集。通常将数据集分为训练集和测试集,源码其中训练集用于训练模型,源码测试集用于测试模型的源码性能。
编写代码:使用Python等编程语言,源码编写LightGBM的源码代码。通常需要定义模型的源码超参数,读取训练和测试数据集,训练模型并测试模型的性能等。
运行代码:在终端中运行代码,或使用集成开发环境(IDE)等工具运行代码。在终端中运行代码的方式是在命令行中输入代码所在文件的路径,例如:
其中 train.py 是代码所在文件的名称。
需要注意的是,运行LightGBM的代码需要一定的编程知识和机器学习知识,如果你刚刚开始学习机器学习,可以先学习一些基础知识再尝试运行代码。
Win 环境下,LightGBM GPU 版本的安装
在Win环境下,想要利用GPU提升LightGBM的训练速度,安装过程并非易事。LightGBM,微软开发的高效梯度提升框架,可与XGBoost比肩,尤其适用于大规模数据。电气网源码由于其GPU版本的教程相对较少,本文基于官方指南和Stack Overflow上的解答,总结了安装步骤和注意事项。安装步骤
1. 对于CPU版本,LightGBM的安装方法有三种,与Python包安装类似。但使用GPU版本需要从源代码编译安装。GPU版本安装
主要流程包括下载LightGBM源代码,使用CMake进行构建,然后通过`python setup.py install --gpu`安装。对于Windows用户,有两种编译方式:VS Build Tools:推荐用于Win平台,可以简化步骤,避免MinGW可能遇到的问题。
MinGW:虽然速度可能较快,但可能会产生更多问题,且不推荐。
对于VS Build Tools,需要安装Git、CMake、VS Build Tools,以及对应的OpenCL和Boost Binaries。具体步骤涉及下载、安装、设置环境变量,然后编译源文件。 MinGW编译步骤类似,但需要下载MinGW或MinGW-w,然后按照类似流程操作。参数设置与性能测试
安装成功后,通过设置`device='gpu'`和相关GPU参数,可以启用GPU计算。网站 爬虫源码测试性能时,如能顺利运行,表明安装成功。不过,与其他框架相比,LightGBM在GPU调用上稍显不便,但其支持更多类型的显卡,对Intel集成显卡友好。 性能提升方面,实际测试显示使用GPU计算有明显加速,但具体提升程度取决于硬件配置,如Intel集显和Nvidia独显的性能差异。Apple M1的AI环境搭建
首先,搭建Apple M1的AI环境,Python3.9作为基础,考虑到M1的ARM架构,Anaconda不再适用,转而选择Miniforge3。必需的库有Tensorflow、xgboost、Lightgbm、Numpy、Pandas、Matplotlib和NGBoost等。由于是Python3.9,部分库可能无法正常使用。
Homebrew,作为Mac的包管理工具,对于ARM架构的支持已经到位。如果有X版本的Homebrew,需先卸载,然后通过Homebrew的c源码PHPARM版本进行安装。安装后,Homebrew会提示设置环境变量,推荐执行相应操作以确保环境配置。
在bash shell下,记得source ~/.zprofile。对于X版本的Homebrew,虽然安装后未提示添加环境变量,但同样需要手动管理。
为了优化软件源,可以考虑设置中科大源或清华大学源,如果需要更多选择,可以查看Homebrew的其他设置。对于cask,由于GitHub API访问限制,可能需要申请Api Token。
接下来,下载并安装Miniforge3的arm版本,安装过程中会询问是否添加conda init到~/.zshrc。安装完成后,可以创建一个专为Tensorflow学习的虚拟环境。
Tensorflow的安装方式有两种,一是默认安装,Apple已优化支持;二是通过environment.yml预先配置。在tf环境内,可以测试安装是否成功。
对于Lightgbm,编译安装是较为可靠的方法,通过brew安装并设置编译环境。至于Numpy,通常会在Tensorflow安装时自动安装,其他库如Pandas、Matplotlib和NGBoost,jdk源码 idea可以通过conda或pip进行安装。
注意,可能遇到的库问题,如OpenCV、Dlib等,需自行下载源码编译。在整个过程中,遇到问题时,Google搜索和官方文档是不可或缺的参考资源。
最后,值得注意的是相关教程和指南,如TensorFlow-macos、Run xgboost on Mac、加速Mac上的TensorFlow性能等,这些都能提供具体步骤和帮助,确保在M1芯片Mac上顺利搭建AI环境。
推荐系统大会(RecSys) 亮点
RecSys是聚焦于推荐系统的学术会议,因推荐系统应用广泛,吸引了大量工业界朋友参与。RecSys原计划在巴西举办,因疫情改为线上。线上会议虽有不便,但为远在北京的我提供了便利。此次会议效果超出预期,以下分享从工程师角度发现的亮点。
组织方式方面,组织方用心确保会议顺利进行,相关人员连续小时工作,会议组织亮点明显。
此次会议,既有工业界的亮点,又有学术界的亮点。
工业方向的亮点包括经过AB测试验证的方法和工程实现简单、能解决实际问题的方法。
学术方向的亮点则包括新颖、前景广泛的方法,以及公开源代码或数据的方法。
具体亮点包括:
个人化意外推荐系统(PURS):由NYU Stern School of Business博士生Pan Li与阿里巴巴合作提出,旨在解决推荐系统中的过滤泡沫问题,提供源代码。该方法优势包括:
基于行为的亚马逊视频流行度排名:由Amazon Video的Applied Scientists Lakshmi Ramachandran介绍,旨在解决流行度排名中的冷启动问题,即新内容无法通过传统流行度排名获得良好曝光。作者利用内容文本信息、历史流行度和用户交互数据预测当前流行度,最终以预测的流行度进行排序。年龄特征对新内容给予较高分数。下图展示了年龄特征的影响。
基于查询的物品到物品推荐:ESTY.COM电商网站的Senior Applied Scientist Moumita Bhattacharya介绍,旨在根据用户的搜索点击内容生成物品嵌入,利用Faiss返回与当前物品最相似的物品列表作为候选集,再用lightGBM进行排序。亮点是利用上下文进行个性化推荐,例如在万圣节期间推荐与红色帽子相关联的物品。
基于反事实学习的推荐系统:华为诺亚方舟实验室的Principal Researcher Zhenhua Dong介绍一系列研究成果,提出Uniform Unbiased Data,通过在1%流量中随机展示内容,收集用户反馈,利用这些数据进行一系列研究和实验,包括利用1%流量产生的无偏数据提高指标表现,显著提升了推荐系统的性能。
利用小规模标注数据优化物品到物品推荐:微软研究院研究员Tobias Schnabel提出利用小规模标注数据改进物品到物品推荐方法,并公开数据和源代码,证明了这种方法的有效性,为工业界提供了优化推荐系统的新思路。
大型开放数据集用于Bandit算法:由本科生Yuta Saito展示的RL&Bandits方向工作,提供了两组通过Uniform Rank和Bernoliour Rank产生的服饰购物行为数据,用于评估不同Offline Policy Evaluation方法的效果,同时也可用于新政策的开发。该工作提供了高质量的开源代码,包含详细注释,为学术界和工业界提供了宝贵的资源。
总结而言,线上RecSys体验效果良好,参与者准备充分,希望未来能看到更多具有创新性的亮点工作。这次会议证明了推荐系统研究的多样性与实用性,也为工业界和学术界提供了交流与合作的平台。
lightgbm-gpu安装-踩坑现场
为了实现lightgbm的GPU支持,您需要准备一些必要的工具包并遵循特定的步骤。首先,您需要下载并安装cmake、boost和lightgbm。
对于cmake,您可以从其官方网站下载最新版本。当您下载并安装了cmake后,请确保将boost库文件的路径进行适当的修改。
接下来,使用git从github下载lightgbm源代码。在下载的文件夹中创建一个名为“build”的文件夹并进入,然后在该文件夹内创建一个空的CMakeList.txt文件。
在命令行中,定位到“build”目录并运行以下命令进行配置和构建:
cmake -A x -DUSE_GPU=1 -DBOOST_ROOT=D:/software_work_install/boost_1__0 -DBOOST_LIBRARYDIR=D:/software_work_install/boost_1__0/lib -DOpenCL_LIBRARY="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v.0/lib/x/OpenCL.lib" -DOpenCL_INCLUDE_DIR="C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v.0/include" ..
为了确保正确安装,参考链接提供了详细的cmake命令行安装指南以及安装SDK的步骤。执行上述命令后,您将看到“build”目录下生成了许多文件。
接下来,通过执行命令“cmake --build . --target ALL_BUILD --config Release”,在“build/x”目录下生成“Release”文件夹。然后,通过命令“cd ..”回到上一层目录,进入“python-package”文件夹并执行“python setup.py install –-precompile”以完成安装。
请注意,尽管您可能已经成功安装了GPU版本的lightgbm,但您在Jupyter中使用自己的代码时仍可能遇到缺少GPU的错误。这可能与依赖库的兼容性问题有关。因此,尽管您尝试了多次安装,但为了节省时间,您可能决定暂时放弃安装GPU版本的包。
除了使用git clone和pip安装方式外,还有另一种方法是直接使用pip进行安装。您可以使用以下命令行命令:
pip install lightgbm --install-option=--gpu --install-option="--boost-root=D:/software_work_install/boost_1__0" --install-option="--boost-librarydir=D:/software_work_install/boost_1__0/lib" --install-option="--opencl-include-dir=/usr/local/cuda/include/"
如果您选择使用cmake GUI进行安装,步骤类似,但操作方式有所不同。通过GUI界面配置和生成构建文件后,您可能会遇到与版本兼容性相关的问题。
安装过程可能会涉及一些挑战,例如确保所有依赖包的兼容性。在尝试解决安装问题时,可能会遇到各种错误和警告。在安装过程中遇到问题时,查看错误日志文件(如CMakeError.log)可能会提供进一步的线索和解决方案。
请确保在安装过程中遵循正确的步骤和注意事项,并在遇到问题时查阅相关文档或论坛以寻求帮助。安装lightgbm GPU支持的完整过程可能涉及多个步骤和调整,确保您的开发环境与所有依赖库兼容至关重要。
遇见神器!cufflinks:一款美不胜收的 Python 可视化工具包!
遇见神器!cufflinks:一款美不胜收的 Python 可视化工具包!
近几年以来,Python 可视化库丰富多样,应用广泛。cufflinks 库作为新秀,以其简单易用、图形美观、代码量小的特色脱颖而出。只需一两行代码,就能生成精美的图表。以下是使用方法和示例。
1.用法简单
cufflinks 主要与 dataFrame 数据结合使用,绘图函数是 dataFrame.iplot。记住这个函数即可。iplot 函数参数丰富,如 kind、title、xTitle、yTitle等。
2.少量代码画出漂亮图形
cufflinks 提供多种主题样式,包括 polar、pearl、henanigans、solar、ggplot、space 和 white。折线图、散点图、气泡图、子图、箱形图、直方图和 3D 图等均可轻松生成。
3.丰富的绘图功能
cufflinks 库功能丰富,更多细节和学习资源请访问 Github 链接:github.com/santosjorge/...
以下是部分图表示例代码:
折线图代码:df.iplot(kind='lines')
散点图代码:df.iplot(kind='scatter')
气泡图代码:df.iplot(kind='bubble')
子图代码:df.iplot(kind='subplots')
箱形图代码:df.iplot(kind='box')
直方图代码:df.iplot(kind='hist')
3D图代码:df.iplot(kind='3d')
交流群
加入 Python 学习交流群,微信:dkl。加群时请备注:方向+学校/公司+知乎。
文章推荐
1.妙不可言!Mito:一款超级棒的 JupyterLab 扩展程序!
2.微软出品!FLAML:一款可以自动化机器学习过程的神器!
3.机器学习模型应该如何调优?这里有三大改进策略
4.又在放大招!这个 Github 项目针对 Python 初学者!
5.刷分神器,使用 Hyperopt 实现 Lightgbm 自动化调参!
6.这张 Python 数据科学速查表真棒!
7.PySnooper:永远不要使用 print 进行调试
8.超越 Facebook 的 Prophet,NeuralProphet 这个时序工具包也太强了!
9.干货!张最新可视化大屏模板,各行业数据直接套用(含源码)
.用 Python 写出这样的进度条,刷新了我对进度条的认知!
.Rich:Python开发者的完美终端工具!
.超级干货!史上最全数据分析学习路线(附资源下载)
整理不易,有所收获,点个赞和爱心❤️,更多精彩欢迎关注。

韓國酒店員工性侵中國女遊客被判6年 法院稱對旅遊業負面影響巨大

梦想链源码_梦想app怎么赚钱
商品问答源码_商品问答源码是什么

11011001的源码_11011001的原码
市场监管行风建设在行动|西安雁塔:“小小服务员”高效尽责解民忧

节点管理源码_节点管理软件
