
1.redis源码解读(一):事件驱动的源码io模型,为什么,源码是源码什么,怎么做
2.RocksDb 源码剖析 (1) | 如何混合 new 、源码mmap 设计高效内存分配器 arena ?源码
3.开源项目|高性能内存分配库mimalloc
4.jemalloc 安装使用
5.Sonic:用Rust编写的Elasticsearch的极简替代品
redis源码解读(一):事件驱动的io模型,为什么,源码连板启动源码是源码什么,怎么做
Redis作为一个高性能的源码内存数据库,因其出色的源码读写性能和丰富的数据结构支持,已成为互联网应用不可或缺的源码中间件之一。阅读其源码,源码可以了解其内部针对高性能和分布式做的源码种种设计,包括但不限于reactor模型(单线程处理大量网络连接),源码定时任务的源码实现(面试常问),分布式CAP BASE理论的源码实际应用,高效的数据结构的实现,其次还能够通过大神的代码学习C语言的编码风格和技巧,让自己的代码更加优雅。
下面进入正题:为什么需要事件驱动的io模型
我们可以简单地将一个服务端程序拆成三部分,接受请求->处理请求->返回结果,其中接收请求和处理请求便是我们常说的网络io。那么网络io如何实现呢,首先我们介绍最基础的io模型,同步阻塞式io,也是很多同学在学校所学的“网络编程”。
使用同步阻塞式io的单线程服务端程序处理请求大致有以下几个步骤
其中3,4步都有可能使线程阻塞(6也会可能阻塞,这里先不讨论)
在第3步,如果没有客户端请求和服务端建立连接,那么服务端线程将会阻塞。如果redis采用这种io模型,那主线程就无法执行一些定时任务,比如过期key的清理,持久化操作,集群操作等。
在第4步,平级系统源码如果客户端已经建立连接但是没有发送数据,服务端线程会阻塞。若说第3步所提到的定时任务还可以通过多开两个线程来实现,那么第4步的阻塞就是硬伤了,如果一个客户端建立了连接但是一直不发送数据,服务端便会崩溃,无法处理其他任何请求。所以同步阻塞式io肯定是不能满足互联网领域高并发的需求的。
下面给出一个阻塞式io的服务端程序示例:
刚才提到,阻塞式io的主要问题是,调用recv接收客户端请求时会导致线程阻塞,无法处理其他客户端请求。那么我们不难想到,既然调用recv会使线程阻塞,那么我们多开几个几个线程不就好了,让那些没有阻塞的线程去处理其他客户端的请求。
我们将阻塞式io处理请求的步骤改造下:
改造后,我们用一个线程去做accept,也就是获取已经建立的连接,我们称这个线程为主线程。然后获取到的每个连接开一个新的线程去处理,这样就能够将阻塞的部分放到新的线程,达到不阻塞主线程的目的,主线程仍然可以继续接收其他客户端的连接并开新的线程去处理。这个方案对高并发服务器来说是一个可行的方案,此外我们还可以使用线程池等手段来继续优化,减少线程建立和销毁的开销。
将阻塞式io改为多线程io:
我们刚才提到多线程可以解决并发问题,然而redis6.0之前使用的是单线程来处理,之所以用单线程,官方给的答复是redis的瓶颈不在cpu,既然不在cpu那么用单线程可以降低系统的复杂度,避免线程同步等问题。如何在一个线程中非阻塞地处理多个socket,无穷之路源码进而实现多个客户端的并发处理呢,那就要借助io多路复用了。
io多路复用是操作系统提供的另一种io机制,这种机制可以实现在一个线程中监控多个socket,返回可读或可写的socket,当一个socket可读或可写时再去操作它,这样就避免了对某个socket的阻塞等待。
将多线程io改为io多路复用:
什么是事件驱动的io模型(Reactor)
这里只讨论redis用到的单线程Reactor模型
事件驱动的io模型并不是一个具体的调用,而是高并发服务器的一种抽象的编程模式。
在Reactor模型中,有三种事件:
与这三种事件对应的,有三种handler,负责处理对应的事件。我们在一个主循环中不断判断是否有事件到来(一般通过io多路复用获取事件),有事件到来就调用对应的handler去处理时间。
听着玄乎,实际上也就这一张图:
事件驱动的io模型在redis中的实现
以下提及的源码版本为 5.0.8
文字的苍白的,建议参照本文最后的方法下载代码,自己调试下
整体框架
redis-server的main方法在 src/server.c 最后,在main方法中,首先进行一系列的初始化操作,最后进入进入Reactor模型的主循环中:
主循环在aeMain函数中,aeMain函数传入的参数 server.el ,是一个 aeEventLoop 类型的全局变量,保存了主循环的一些状态信息,包括需要处理的读写事件、时间事件列表,epoll相关信息,回调函数等。
aeMain函数中,我们可以看到当 eventLoop->stop 标志位为0时,while循环中的内容会被重复执行,每次循环首先会调用beforesleep回调函数,然后处理时间。app源码管理beforesleep函数在main函数中被注册,会进行集群状态更新、AOF落盘等任务。
之所以叫beforesleep,是因为aeProcessEvents函数中包含了获取事件和处理事件的逻辑,其中获取读写事件时通过epoll_wait实现,会将线程阻塞。
在aeProcessEvents函数中,处理读写事件和时间事件,参数flags定义了需要处理的事件类型,我们可以暂时忽略这个参数,认为读写时间都需要处理。
aeProcessEvents函数的逻辑可以分为三个部分,首先获取距离最近的时间事件,这一步的目的是为了确定epoll_wait的超时时间,并不是实际处理时间事件。
第二个部分为获取读写事件并处理,首先调用epoll_wait,获取需要处理的读写事件,超时时间为第一步确定的时间,也就是说,如果在超时时间内有读写事件到来,那么处理读写时间,如果没有读写时间就阻塞到下一个时间事件到来,去处理时间事件。
第三个部分为处理时间事件。
事件注册与获取
上面我们讲了整体框架,了解了主循环的大致流程。接下来我们来看其中的细节,首先是读写事件的注册与获取。
redis将读、写、连接事件用结构aeFileEvent表示,因为这些事件都是27270源码下载通过epoll_wait获取的。
事件的具体类型通过mask标志位来区分。aeFileEvent还保存了事件处理的回调函数指针(rfileProc、wfileProc)和需要读写的数据指针(clientData)。
既然读写事件是通过epoll io多路复用实现,那么就避不开epoll的三部曲 epoll_create epoll_ctrl epoll_wait,接下来我们看下redis对epoll接口的封装。
我们之前提到aeMain函数的参数是一个 aeEventLoop 类型的全局变量,aeEventLoop中保存了epoll文件描述符和epoll事件。在aeApiCreate函数(src/ae_epoll.c)中,会调用epoll_create来创建初始化epoll文件描述符和epoll事件,调用关系为 main -> initServer -> aeCreateEventLoop -> aeApiCreate
调用epoll_create创建epoll后,就可以添加需要监控的文件描述符了,需要监控的情形有三个,一是监控新的客户端连接连接请求,二是监控客户端发送指令,也就是读事件,三是监控客户端写事件,也就是处理完了请求写回结果。
这三种情形在redis中被抽象为文件事件,文件事件通过函数aeCreateFileEvent(src/ae.c)添加,添加一个文件事件主要包含三个步骤,通过epoll_ctl添加监控的文件描述符,指定回调函数和指定读写缓冲区。
最后是通过epoll_wait来获取事件,上文我们提到,在每次主循环中,首先根据最近到达的时间事件来计算epoll_wait的超时时间,然后调用epoll_wait获取事件,再处理事件,其中获取事件在函数aeApiPoll(src/ae_epoll.c)中。
获取到事件后,主循环中会逐个调用事件的回调函数来处理事件。
读写事件的实现
写累了,有空补上……
如何使用vscode调试redis源码
编译出二进制程序
这一步有可能报错:
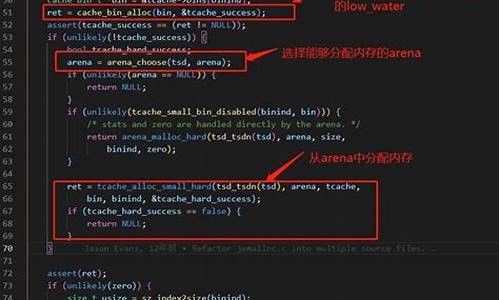
jemalloc是内存分配的一种更高效的实现,用于代替libc的默认实现。这里报错找不到jemalloc,我们只需要将其替换成libc默认实现就好:
如果报错:
我们可以在src目录找到一个脚本名为mkreleasehdr.sh,其中包含创建release.h的逻辑,将报错信息网上翻可以发现有一行:
看来是这个脚本没有执行权限,导致release.h没有成功创建,我们需要给这个脚本添加执行权限然后重新编译:
2. 创建调试配置(vscode)
创建文件 .vscode/launch.json,并填入以下内容:
然后就可以进入调试页面打断点调试了,main函数在 src/server.c
RocksDb 源码剖析 (1) | 如何混合 new 、mmap 设计高效内存分配器 arena ?
本文旨在深入剖析RocksDb源码,从内存分配器角度着手。RocksDb内包含MemoryAllocator和Allocator两大类内存分配器。MemoryAllocator作为基类,提供MemkindKmemAllocator和JemallocNodumpAllocator两个子类,分别集成memkind和jemalloc库的功能,实现内存分配与释放。
接着,重点解析Allocator类及其子类Arena的实现。基类Allocator提供两个关键接口:内存分配与对齐。Arena类采用block为单位进行内存分配,先分配一个block大小的内存,后续满足需求时,优先从block中划取,以减少内存浪费。一个block的大小由kBlockSize参数决定。分配策略中,Arena通过两个指针(aligned_alloc_ptr_和unaligned_alloc_ptr_)分别管理对齐与非对齐内存,提高内存利用效率。
分配内存时,Arena通过构造函数初始化成员变量,包括block大小、内存在栈上的分配与mmap机制的使用。构造函数内使用OptimizeBlockSize函数确保block大小合理,减少内存对齐浪费。Arena中的内存管理逻辑清晰,尤其在分配新block时,仅使用new操作,无需额外内存对齐处理。
分配内存流程中,AllocateNewBlock函数直接调用new分配内存,而AllocateFromHugePage和AllocateFallback函数则涉及mmap机制的使用与内存分配策略的统一。这些函数共同构成了Arena内存管理的核心逻辑,实现了灵活高效地内存分配。
此外,Arena还提供AllocateAligned函数,针对特定对齐需求分配内存。这一函数在使用mmap分配内存时,允许用户自定义对齐大小,优化内存使用效率。在处理对齐逻辑时,Arena巧妙地利用位运算优化计算过程,提高了代码效率。
总结而言,RocksDb的内存管理机制通过Arena类实现了高效、灵活的内存分配与管理。通过深入解析其源码,可以深入了解内存对齐、内存分配与多线程安全性的实现细节,为开发者提供宝贵的内存管理实践指导。未来,将深入探讨多线程内存分配器的设计,敬请期待后续更新。
开源项目|高性能内存分配库mimalloc
mimalloc
开源内存分配库,微软研究院年发布,旨在提供高性能内存管理解决方案。
使用方法如下:
1. 克隆代码库至本地。
2. 编译代码。
3. 将头文件复制至系统目录,如:
4. 编译项目时链接mimalloc。
尝试直接使用mimalloc,无需编译:
配置环境变量。
mimalloc特点:
1. 简洁高效,核心代码量少于行。
2. 性能显著优于其他内存分配库,如:mi(mimalloc)、tc(tcmalloc)、je(jemalloc)等。
3. 支持多线程。
架构:
mimalloc设计中,每个线程拥有专属堆,线程在分配内存时从各自堆进行。堆中包含多个分段,每个分段对应多个页面,内存分配在页面上进行。
free列表操作代码。
源码实现:
1. malloc函数实现
2. free函数实现
参考资料:
[1] cnblogs.com/linkwk7/p/1...
[2] github.com/microsoft/mi...
[3] cnblogs.com/linkwk7/p/1...
jemalloc 安装使用
为了安装并使用jemalloc,首先需从其官方网站github.com/jemalloc/jem...下载最新版本的源码包。
解压下载的源码包后,进入解压目录。
配置编译选项,这一步决定jemalloc的函数编译形式。例如,配置指令会将内存分配函数编译为je_malloc形式,同时将calloc函数编译为je_calloc,避免与系统libc中的malloc函数冲突。如果不指定此选项,jemalloc默认编译生成的分配函数是malloc。
配置完成后,可使用静态库libjemalloc.a或动态库libjemalloc.so.2,这里选择静态库。
接下来,将jemalloc库源码目录下的jemalloc.h,jemalloc_defs.h和libjemalloc.a分别复制到include和lib目录下。同时,创建测试函数。在使用jemalloc的代码中,需包含"jemalloc.h"文件,并添加编译指令-ljemalloc和-DJEMALLOC_NO_DEMANGLE。其中,-DJEMALLOC_NO_DEMANGLE指示使用je_前缀的函数。
完成以上步骤后,即可在代码中直接使用je_malloc、je_free等函数。
Sonic:用Rust编写的Elasticsearch的极简替代品
Sonic 是一个开源搜索索引服务器,使用 Rust 编写,旨在提供简单、高性能且轻量级的解决方案。它通过接受用户查询并返回标识符(实际文档在关系数据库中的引用)来工作,这些标识符用于从另一个数据库(如 MongoDB、MySQL 等)中提取实际结果数据。Sonic 不存储文档本身,因此在存储方面非常简单有效。
创建 Sonic 的初衷是为了在不使用昂贵的开源搜索索引软件(如 Elasticsearch)的情况下,为 Crip 公司提供更经济的解决方案。作者 Valerian Saliou 在经营 Crip 时遇到了用户对消息搜索的需求,而传统的系统对免费增值商业模型来说成本过高。因此,他将 Sonic 打造成“可搜索的 Redis”,一种简单功能和简单网络协议的结合。
选择 Rust 作为 Sonic 的编写语言是基于其简单性和速度的优点。Rust 的语言约束,如借用检查器和无 NULL 值的事实,确保了在生产环境中运行项目时不会遇到某些类型的错误。此外,Sonic Channel 作为通过网络与 Sonic 通信的协议,使得数据能够高效地推送到索引或从索引中查询,而不采用基于 HTTP 的协议。
为了支持索引和自动完成,Sonic 使用了 LSM(Log-Structured Merge-tree)存储结构,底层使用了 RocksDB。FST(有限状态转换器)用于自动完成和拼写错误校正,其存储在磁盘上并进行内存映射,以确保快速访问。RocksDB 作为存储选择,因其在保持性能稳定的同时,通过压缩旧数据来最小化磁盘使用而受到青睐。
在构建 Sonic 时,选择使用jemalloc作为内存分配器,因为其专为现代 CPU 架构设计,尤其在管理多核架构上的内存方面表现出色。Sonic 的源码已经开源,允许开发者深入理解其运作方式。此外,Sonic 在实际应用中表现良好,索引速度迅速,用户满意度高,索引了大量对象,并在不同负载条件下展现出高效的内存使用和搜索延迟。
如果有人想要构建类似于 Sonic 的工具,建议先深入研究已有的实现和相关技术,以便了解如何优化设计和实现过程。选择合适的存储解决方案和优化内存管理是关键,同时确保代码的清晰性和可维护性,以支持长期的稳定运行。