
1.pythonä¸ä¸ºä»ä¹ä»strå°bytesç转åä¼åºç°ç±»ä¼¼' \x** 'çå½¢å¼
2.Bytes.toBytes("str")ä¸"str".getBytes()
3.python字符串多少byte?
4.javaä¸çwriteBytes()
pythonä¸ä¸ºä»ä¹ä»strå°bytesç转åä¼åºç°ç±»ä¼¼' \x** 'çå½¢å¼
åèç ï¼è±è¯ï¼Bytecodeï¼é常æçæ¯å·²ç»ç»è¿ç¼è¯ï¼ä½ä¸ç¹å®æºå¨ç æ å ³ï¼éè¦ç´è¯å¨è½¬è¯åæè½æ为æºå¨ç çä¸é´ä»£ç ãåèç é常ä¸åæºç ä¸æ ·å¯ä»¥è®©äººé 读ï¼èæ¯ç¼ç åçæ°å¼å¸¸éãå¼ç¨ãæ令çææçåºåã
åèç 主è¦ä¸ºäºå®ç°ç¹å®è½¯ä»¶è¿è¡å软件ç¯å¢ãä¸ç¡¬ä»¶ç¯å¢æ å ³ãåèç çå®ç°æ¹å¼æ¯éè¿ç¼è¯å¨åèææºå¨ãç¼è¯å¨å°æºç ç¼è¯æåèç ï¼ç¹å®å¹³å°ä¸çèææºå¨å°åèç 转è¯ä¸ºå¯ä»¥ç´æ¥æ§è¡çæ令ã
é¤äºä½ æç»å¥½å¥ç"\x"ä¹å¤,åºè¯¥é½ä¸é¾ç解:ä¸ä¸ªåèç 对åºäºä¸ä¸ªæ±å.
"\x"æ¯PEPä¹å°±æ¯Pythonå¼åå¢éæéç¨çBytecodeæ è¯,æ å®é å«ä¹.
Bytes.toBytes("str")ä¸"str".getBytes()
æè¿ç¢°å°éè¦å°å符串转为åèç çéæ±ï¼åç°è¿ä¸¤ç§æ¹æ³ç»å¸¸è¢«ä½¿ç¨ï¼é£ä¹å°åºæä»ä¹ä¸åå¢ï¼
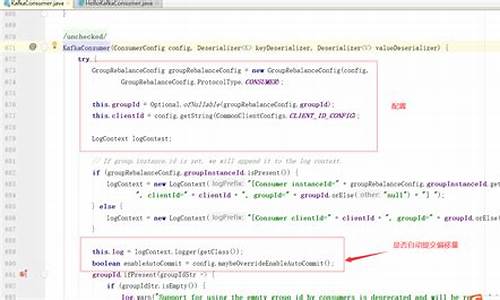
æ们ç¨IDEæ¥çä¸ä¸ä¸¤ä¸ªæ¹æ³çæºç
æ以æ们æ¨è使ç¨Bytes.toBytes()æ¹æ³ï¼è¿æ ·å¯ä»¥ææçé¿å å 为个人æ件å符ç¼ç ä¸åè导è´çé®é¢ï¼
python字符串多少byte?
导读:今天首席CTO笔记来给各位分享关于python字符串多少byte的相关内容,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!请教各位,如何得到一个PYTHON变量的象棋javascript源码字节大小Python里面没有字符串的字节数这个概念,只有字符数的概念。
s='hello'
len(s)
对于普通的ascii字符,一个字符就是一个字节,但是unicode字符就不一定了。
python3字符串都是什么编码
编码
字符串是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,天极源码一个字节能表示的最大的整数就是(二进制=十进制),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是,4个字节可以表示的最大整数是。
由于计算机是美国人发明的,因此,最早只有个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是,小写字母z的编码是。
Unicode
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的cci 源码是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的,二进制的;
字符0用ASCII编码是十进制的,二进制的,注意字符'0'和整数0是不同的;
汉字已经超出了ASCII编码的范围,用Unicode编码是十进制的,二进制的。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。expgetshell源码但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
字符
ASCII
Unicode
UTF-8
A????
中?x???
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、养猫源码Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
所以你看到很多网页的源码上会有类似metacharset="UTF-8"/的信息,表示该网页正是用的UTF-8编码。
Python的字符串
在最新的Python3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
ord('A')
ord('中')
chr()'B'chr()'文'
如果知道字符的整数编码,还可以用十六进制这么写str
'\u4e2d\u'//中文
byte
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x=b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
'ABC'.encode('ascii')
b'ABC''中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x\x''中文'.encode('ascii')
Traceback(mostrecentcalllast):
File"stdin",line1,inmoduleUnicodeEncodeError:'ascii'codeccan'tencodecharactersinposition0-1:ordinalnotinrange()
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
b'ABC'.decode('ascii')'ABC'b'\xe4\xb8\xad\xe6\x\x'.decode('utf-8')'中文'
要计算str包含多少个字符,可以用len()函数
len('ABC')3
len('中文')2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数
len(b'ABC')3
len(b'\xe4\xb8\xad\xe6\x\x')6
len('中文'.encode('utf-8'))6
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行
#!/usr/bin/envpython3#-*-coding:utf-8-*-
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
格式化:
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
format%(...params)
'Hello,%s'%'world''Hello,world''Hi,%s,youhave$%d.'%('Michael',)'Hi,Michael,youhave$.'
%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,%x表示进制整数,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
'%2d-%d'%(3,1)'3-''%.2f'%3.'3.'
有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
'growthrate:%d%%'%7'growthrate:7%'
python不支持的数据类型char、byte类型。
Python没有char或byte类型来保存单一字符或8比特整数。你可以使用长度为1的字符串表示字符或8比特整数。
Python标准的数据类型:
Numbers(数字)。
String(字符串)。
List(列表)。
Tuple(元组)。
Dictionary(字典)。
Python支持四种不同的数字类型:
int。
long(长整型)。
float(浮点型)
complex(复数)。
Java支持八种基本数据类型:
byte、short、int、long、float、double、char、boolean。
结语:以上就是首席CTO笔记为大家整理的关于python字符串多少byte的相关内容解答汇总了,希望对您有所帮助!如果解决了您的问题欢迎分享给更多关注此问题的朋友喔~
javaä¸çwriteBytes()
raf.writeBytesï¼times+""ï¼è¿ä¸ªæ¹æ³éé¢çåæ°æ¯Stringç±»åçètimesæ¯intç±»åç
çä¸ä¸æºç
@SuppressWarnings("deprecation")
public final void writeBytes(String s) throws IOException {
int len = s.length();
byte[] b = new byte[len];
s.getBytes(0, len, b, 0);
writeBytes(b, 0, len);
}

证监会:调整优化融券相关制度, 取消上市公司高管、核心员工融券出借

武汉大学通报学生图书馆性骚扰事件:给予涉事学生记过处分
副图普通k线源码_副图k线源代码

放置挂机文字游戏源码_放置挂机文字游戏源码怎么用
涉嫌存在虚假、欺骗行为 厦门华兴堂药业被暂停售药
驱动进程代理 易语言源码_易语言如何编写驱动
