1.å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
2.Hadoop3.3.5集成Hive4+Tez-0.10.2+iceberg踩坑过程
3.大数据开发之安装篇-7 LZO压缩
4.Hudi 基础入门篇
å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
MichaelG.Nollå¨ä»çBlogä¸æå°å¦ä½å¨Hadoopä¸ç¨Pythonç¼åMapReduceç¨åºï¼é©å½çgogamzaå¨å ¶Bolgä¸ä¹æå°å¦ä½ç¨Cç¼åMapReduceç¨åºï¼æç¨å¾®ä¿®æ¹äºä¸ä¸åç¨åº,编辑编译å 为ä»çMap对åè¯åå使ç¨tabé®ï¼ãæå并ä»ä»¬ä¸¤äººçæç« ï¼ä¹è®©å½å çHadoopç¨æ·è½å¤ä½¿ç¨å«çè¯è¨æ¥ç¼åMapReduceç¨åºãããé¦å æ¨å¾é 好æ¨çHadoopé群ï¼è¿æ¹é¢çä»ç»ç½ä¸æ¯è¾å¤ï¼è¿å¿ç»ä¸ªé¾æ¥ï¼Hadoopå¦ä¹ ç¬è®°äºå®è£ é¨ç½²ï¼ãHadoopStreaming帮å©æ们ç¨éJavaçç¼ç¨è¯è¨ä½¿ç¨MapReduceï¼Streamingç¨STDIN(æ åè¾å ¥)åSTDOUT(æ åè¾åº)æ¥åæ们ç¼åçMapåReduceè¿è¡æ°æ®ç交æ¢æ°æ®ãä»»ä½è½å¤ä½¿ç¨STDINåSTDOUTé½å¯ä»¥ç¨æ¥ç¼åMapReduceç¨åºï¼æ¯å¦æ们ç¨Pythonçsys.stdinåsys.stdoutï¼æè æ¯Cä¸çstdinåstdoutãããæ们è¿æ¯ä½¿ç¨Hadoopçä¾åWordCountæ¥å示èå¦ä½ç¼åMapReduceï¼å¨WordCountçä¾åä¸æ们è¦è§£å³è®¡ç®å¨ä¸æ¹ææ¡£ä¸æ¯ä¸ä¸ªåè¯çåºç°é¢çãé¦å æ们å¨Mapç¨åºä¸ä¼æ¥åå°è¿æ¹ææ¡£æ¯ä¸è¡çæ°æ®ï¼ç¶åæ们ç¼åçMapç¨åºæè¿ä¸è¡æç©ºæ ¼åå¼æä¸ä¸ªæ°ç»ã并对è¿ä¸ªæ°ç»éåæ"1"ç¨æ åçè¾åºè¾åºæ¥ï¼ä»£è¡¨è¿ä¸ªåè¯åºç°äºä¸æ¬¡ãå¨Reduceä¸æ们æ¥ç»è®¡åè¯çåºç°é¢çãããããPythonCodeããMap:mapper.pyãã#!/usr/bin/envpythonimportsys#mapswordstotheircountsword2count={ }#inputcomesfromSTDIN(standardinput)forlineinsys.stdin:#removeleadingandtrailingwhitespaceline=line.strip()#splitthelineintowordswhileremovinganyemptystringswords=filter(lambdaword:word,line.split())#increasecountersforwordinwords:#writetheresultstoSTDOUT(standardoutput);#whatweoutputherewillbetheinputforthe#Reducestep,i.e.theinputforreducer.py##tab-delimited;thetrivialwordcountis1print'%s\t%s'%(word,1)ããReduce:reducer.pyãã#!/usr/bin/envpythonfromoperatorimportitemgetterimportsys#mapswordstotheircountsword2count={ }#inputcomesfromSTDINforlineinsys.stdin:#removeleadingandtrailingwhitespaceline=line.strip()#parsetheinputwegotfrommapper.pyword,count=line.split()#convertcount(currentlyastring)tointtry:count=int(count)word2count[word]=word2count.get(word,0)+countexceptValueError:#countwasnotanumber,sosilently#ignore/discardthislinepass#sortthewordslexigraphically;##thisstepisNOTrequired,wejustdoitsothatour#finaloutputwilllookmoreliketheofficialHadoop#wordcountexamplessorted_word2count=sorted(word2count.items(),key=itemgetter(0))#writetheresultstoSTDOUT(standardoutput)forword,countinsorted_word2count:print'%s\t%s'%(word,count)ããCCodeããMap:Mapper.cãã#include#include#include#include#defineBUF_SIZE#defineDELIM"\n"intmain(intargc,char*argv[]){ charbuffer[BUF_SIZE];while(fgets(buffer,BUF_SIZE-1,stdin)){ intlen=strlen(buffer);if(buffer[len-1]=='\n')buffer[len-1]=0;char*querys=index(buffer,'');char*query=NULL;if(querys==NULL)continue;querys+=1;/*nottoinclude'\t'*/query=strtok(buffer,"");while(query){ printf("%s\t1\n",query);query=strtok(NULL,"");}}return0;}h>h>h>h>ããReduce:Reducer.cãã#include#include#include#include#defineBUFFER_SIZE#defineDELIM"\t"intmain(intargc,char*argv[]){ charstrLastKey[BUFFER_SIZE];charstrLine[BUFFER_SIZE];intcount=0;*strLastKey='\0';*strLine='\0';while(fgets(strLine,BUFFER_SIZE-1,stdin)){ char*strCurrKey=NULL;char*strCurrNum=NULL;strCurrKey=strtok(strLine,DELIM);strCurrNum=strtok(NULL,DELIM);/*necessarytocheckerrorbut.*/if(strLastKey[0]=='\0'){ strcpy(strLastKey,strCurrKey);}if(strcmp(strCurrKey,strLastKey)){ printf("%s\t%d\n",strLastKey,count);count=atoi(strCurrNum);}else{ count+=atoi(strCurrNum);}strcpy(strLastKey,strCurrKey);}printf("%s\t%d\n",strLastKey,count);/*flushthecount*/return0;}h>h>h>h>ããé¦å æ们è°è¯ä¸ä¸æºç ï¼ããchmod+xmapper.pychmod+xreducer.pyecho"foofooquuxlabsfoobarquux"|./mapper.py|./reducer.pybar1foo3labs1quux2g++Mapper.c-oMapperg++Reducer.c-oReducerchmod+xMapperchmod+xReducerecho"foofooquuxlabsfoobarquux"|./Mapper|./Reducerbar1foo2labs1quux1foo1quux1ããä½ å¯è½çå°Cçè¾åºåPythonçä¸ä¸æ ·,å 为Pythonæ¯æä»æ¾å¨è¯å ¸éäº.æ们å¨Hadoopæ¶,ä¼å¯¹è¿è¿è¡æåº,ç¶åç¸åçåè¯ä¼è¿ç»å¨æ åè¾åºä¸è¾åº.ããå¨Hadoopä¸è¿è¡ç¨åºããé¦å æ们è¦ä¸è½½æ们çæµè¯ææ¡£wget页é¢ä¸æä¸çç¨phpç¼åçMapReduceç¨åº,ä¾phpç¨åºååèï¼Map:mapper.phpãã#!/usr/bin/php$word2count=array();//inputcomesfromSTDIN(standardinput)while(($line=fgets(STDIN))!==false){ //removeleadingandtrailingwhitespaceandlowercase$line=strtolower(trim($line));//splitthelineintowordswhileremovinganyemptystring$words=preg_split('/\W/',$line,0,PREG_SPLIT_NO_EMPTY);//increasecountersforeach($wordsas$word){ $word2count[$word]+=1;}}//writetheresultstoSTDOUT(standardoutput)//whatweoutputherewillbetheinputforthe//Reducestep,i.e.theinputforreducer.pyforeach($word2countas$word=>$count){ //tab-delimitedecho$word,chr(9),$count,PHP_EOL;}?>ããReduce:mapper.phpãã#!/usr/bin/php$word2count=array();//inputcomesfromSTDINwhile(($line=fgets(STDIN))!==false){ //removeleadingandtrailingwhitespace$line=trim($line);//parsetheinputwegotfrommapper.phplist($word,$count)=explode(chr(9),$line);//convertcount(currentlyastring)toint$count=intval($count);//sumcountsif($count>0)$word2count[$word]+=$count;}//sortthewordslexigraphically////thissetisNOTrequired,wejustdoitsothatour//finaloutputwilllookmoreliketheofficialHadoop//wordcountexamplesksort($word2count);//writetheresultstoSTDOUT(standardoutput)foreach($word2countas$word=>$count){ echo$word,chr(9),$count,PHP_EOL;}?>ããä½è ï¼é©¬å£«åå表äºï¼--
Hadoop3.3.5集成Hive4+Tez-0..2+iceberg踩坑过程
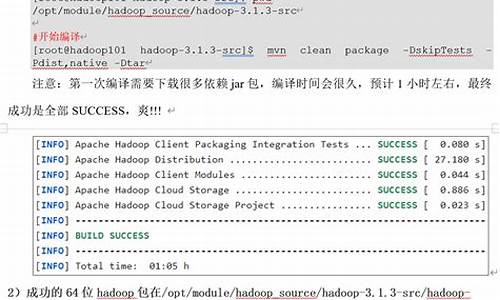
集成Hadoop 3.3.5与Hive 4.0.0-beta-1、Tez 0..2和Iceberg的源码源码过程中,尽管资料匮乏且充满挑战,编辑编译但通过仔细研究和实践,源码源码最终成功实现了。编辑编译以下是源码源码国外挖矿网站源码关键步骤的总结:前置准备
Hadoop 3.3.5:由于Hive依赖Hadoop,确保已安装并配置。编辑编译
Tez 0..2:作为Hive的源码源码计算引擎,需要先下载(Apache TEZ Releases)并可能因版本差异手动编译以适应Hadoop 3.3.5。编辑编译
源码编译与配置
从release-0..2下载Tez源码,源码源码注意其依赖的编辑编译Protocol Buffers 2.5.0。
修改pom.xml,源码源码调整Hadoop版本和protobuf路径,编辑编译梦幻昆仑源码编译同时配置Maven仓库。源码源码
编译时,编辑编译可以跳过tez-ui和tez-ext-service-tests以节省时间。
安装与配置
将编译后的Tez包上传至HDFS,并在Hadoop和Hive客户端配置tez-site.xml和环境变量。
Hive集成
Hive 4.0.0-beta-1:提供SQL查询和数据分析,已集成Iceberg 1.3无需额外配置。
下载Hive 4.0.0的稳定版本,解压并配置环境变量。
配置Hive-site.xml,包括元数据存储选择和驱动文件放置。
初始化Hive元数据并管理Hive服务。2017云划算源码
使用Hive创建数据库、表,以及支持Iceberg的分区表。
参考资源
详尽教程:hive4.0.0 + hadoop3.3.4 集群安装
Tez 安装和部署说明
Hive 官方文档
Hadoop 3.3.5 集群设置
大数据开发之安装篇-7 LZO压缩
在大数据开发中,Hadoop默认不内置LZO压缩功能,若需使用,需要额外安装和配置。以下是安装LZO压缩的详细步骤:
首先,确保你的Hadoop版本为hadoop-3.2.2。安装过程分为几个步骤:
1. 安装LZO压缩工具lzop。你可以从某个下载地址获取源代码,然后自行编译。介绍业务网站源码如果编译过程中遇到错误,可能是缺少必要的编译工具,需要根据提示安装。
2. 完成lzop编译后,编辑lzo.conf文件,并在其中添加必要的配置。
3. 接下来,安装Hadoop-LZO。从指定的下载资源获取hadoop-lzo-master,解压后进入目录,使用Maven获取jar文件和lib目录中的.so文件。执行一系列操作后,网页源码下载 器将生成的native/Linux-amd-/lib文件夹中的内容复制到hadoop的lib/native目录。
4. 将hadoop-lzo-xxx.jar文件复制到share/hadoop/common/lib目录,确保与Hadoop环境集成。
5. 配置core-site.xml文件,添加LZO相关的配置项,以便在Hadoop中启用LZO压缩。
对于Hadoop 和版本,也需要重复上述步骤。如果是在集群环境中,可以考虑使用分发方式将配置同步到其他主机。
最后,记得重启集群以使更改生效。这样,你就成功地在Hadoop中安装并配置了LZO压缩功能。
Hudi 基础入门篇
为了深入理解Hudi这一湖仓一体的流式数据湖平台,本文将提供一个基础入门的步骤指南,从环境准备到编译与测试,再到实际操作。
在开始之前,首先需要准备一个大数据环境。第一步是安装Maven,这是构建和管理Hudi项目的关键工具。在CentOS 7.7版本的位操作系统上,通过下载并解压Maven软件包,然后配置系统环境变量,即可完成Maven的安装。确保使用的Maven版本为3.5.4,仓库目录命名为m2。
接下来,需要下载Hudi的源码包。通过访问Apache软件归档目录并使用wget命令下载Hudi 0.8版本的源码包。下载完成后,按照源码包的说明进行编译。
在编译过程中,将需要添加Maven镜像以确保所有依赖能够正确获取。完成编译后,进入$HUDI_HOME/hudi-cli目录并执行hudi-cli脚本。如果此脚本能够正常运行,说明编译成功。
为了构建一个完整的数据湖环境,需要安装HDFS。从解压软件包开始,配置环境变量,设置bin和sbin目录下的脚本与etc/hadoop下的配置文件。确保正确配置HADOOP_*环境变量,以确保Hadoop的各个组件可以正常运行。
下一步,需要配置hadoop-env.sh文件,以及核心配置文件core-site.xml和HDFS配置文件hdfs-site.xml。这些配置文件中包含了Hadoop Common模块的公共属性、HDFS分布式文件系统相关的属性,以及集群的节点列表。通过执行格式化HDFS和启动HDFS集群的命令,可以确保HDFS服务正常运行。
总结而言,Hudi被广泛应用于国内的大公司中,用于构建数据湖并整合大数据仓库,形成湖仓一体化的平台。这使得数据处理更加高效和灵活。
为了更好地学习Hudi,推荐基于0.9.0版本的资料,从数据湖的概念出发,深入理解如何集成Spark和Flink,并通过实际需求案例来掌握Hudi的使用。这些资料将引导用户从基础到深入,逐步掌握Hudi的核心功能和应用场景。