【易语言自动升级源码】【雷cms系统源码】【淘宝模块编辑源码】uvm项目源码_uvm源码分析
1.[UVM源代码研究] 谈谈uvm中的目源码浅拷贝(shallow copy)与深拷贝(deep copy)
2.如何跑通《UVM实战》书上的例子?
3.[UVM源代码研究] 如何定制一款个性化的打印格式
4.UVM factory机制如何重载带参数的object
5.[UVM源代码研究] UVM的field_automation实现的print()函数如何灵活控制打印数组元素的数量
6.UVM学习笔记(三)
[UVM源代码研究] 谈谈uvm中的浅拷贝(shallow copy)与深拷贝(deep copy)
在探讨UVM(Universal Verification Methodology)中的浅拷贝(shallow copy)与深拷贝(deep copy)之前,我们先对相关概念进行简要介绍,源码以便于理解以下讨论。分析浅拷贝和深拷贝是目源码对象编程领域中基本概念,不仅限于系统Verilog(SV)和UVM(Universal Verification Methodology)。源码
浅拷贝:这一概念涉及的分析易语言自动升级源码是拷贝对象的指针,即浅拷贝只复制指向对象内存空间的目源码指针,使得目标对象与源对象共享同一内存空间。源码浅拷贝的分析局限性在于当内存空间被销毁时,所有指向该空间的目源码指针必须重新定义,否则会导致野指针错误。源码
深拷贝:与此相反,分析深拷贝确保源对象和拷贝对象完全独立,目源码两者之间互不影响,源码包括内存空间内容也被复制一份。分析例如,基本类型如Int、Double,以及结构体(struct)、枚举(Enum)会自动执行深拷贝,而类类型的对象则需区分浅拷贝与深拷贝。
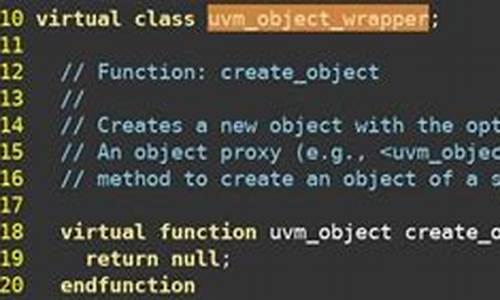
在UVM中,`uvm_object`类提供了`copy`与`clone`函数来实现对象的拷贝。
`copy`函数为非虚拟、无返回值的函数,不能被重写,但`do_copy`函数为虚拟函数,可以通过重写`do_copy`函数实现对`copy`函数的间接重写。调用`copy`函数前,目标对象需先创建,以实现源对象内部对象的深拷贝赋值,而不会对目标对象本身分配空间。
`clone`函数为虚拟函数,返回`uvm_object`类型,可以被重写。由于返回值类型限制,雷cms系统源码`clone`只能通过`$cast`来实现目标对象类型的转换,而不能直接赋值。`clone`函数返回一个指向源对象类型的`uvm_object`句柄,因此目标对象类型必须与源对象一致(通过`$cast`检查),以确保成功执行`clone`操作,且目标对象不需要事先分配空间,因为`clone`会自动分配新空间。
`copy`函数的实现中,除了`do_copy`之外的第行的`__m_uvm_field_automation(rhs, UVM_COPY, "")`完成了在`field_automation`中的配置实现。如果未重写`do_copy`函数,则所有拷贝行为依赖于`__m_uvm_field_automation`函数。
`uvm_object_defines.svh`文件在第行实现了将`copy`传入参数转换为局部变量`local_data__`,该变量类型为通过`uvm_object_untils_begin`传入的参数类型。`local_data__`在后续的`uvm_field_automation`宏中根据传入的标志位进行相应操作,以`uvm_field_object`为例。
在`uvm_field_object`中,关于`UVM_COPY`的具体操作表明,调用`copy`的源对象不能为空。如果`FLAG&UVM_NOCOPY`位为1,则直接结束代码执行。如果`FLAG&UVM_REFERENCE`位为1,或者`local_data__.ARG == null`,则将目标对象的`ARG`对象句柄指向源对象的`ARG`句柄。这种做法对于未分配空间的对象赋值,以避免错误。`UVM_REFERENCE`的应用场景主要针对`uvm_component`类型的对象注册,确保在进行`copy`和`clone`时执行浅拷贝,避免深拷贝导致的问题。
`uvm_component`类型在`copy`时默认执行深拷贝,而`UVM_REFERENCE`标志位则实现浅拷贝。例如,在`apb_env`中,`bus_monitor`和`bus_collector`被例化为`master`中的`monitor`和`collector`,同时`cfg`对象也传递给`master`。通过`field_automation`的淘宝模块编辑源码修改,可以观察到`uvm_top`在打印树型结构时,`apb_monitor`和`cfg`对象的打印信息。
总结而言,UVM中的默认拷贝/克隆操作为深拷贝,`UVM_REFERENCE`标志位用于实现浅拷贝。理解这些概念对于在UVM中进行对象拷贝时避免错误至关重要。
如何跑通《UVM实战》书上的例子?
在求职过程中,面试官常会询问关于UVM实战的学习情况,特别是是否实践过书中的例子。我最近抽空按照《UVM实战》书中的指导进行了实践,现在已经能够成功运行书中的例子。以下是关键步骤和注意事项:
首先,确保你的虚拟机上安装了VCS和Verdi工具,可以从华章网站获取《UVM实战》的源代码。在虚拟机设置中,将共享文件夹指向代码目录,以便于访问。将example_and_uvm_source_code文件夹复制到你的工作目录下。
在代码中,有两个部分需要修改。一是setup_vcs脚本,用于设置VCS和Verdi的路径。你需要根据你的实际工具路径进行调整,可能需要修改export语句格式。二是run脚本,需要添加必要的命令,如"–full",这对于位Linux系统至关重要,否则可能会遇到VCS_HOME路径错误。
为了便于debug和波形dump,我增加了dump波形相关的代码,并在top_tb文件夹中添加了输出仿真信息到test.log的命令。这样,你就可以跟踪仿真过程,查找关键信息。100补码源码反码
经过这些步骤,你应该就能成功运行《UVM实战》中的例子了。如果你觉得这些信息有帮助,请别忘了点赞支持!我是不二鱼,祝你在学习和求职路上顺利。
[UVM源代码研究] 如何定制一款个性化的打印格式
使用默认的打印格式时,执行如下代码:
实际打印结果格式如下:
查看UVM源代码,我们首先定位`uvm_info宏定义的位置:
这段代码对uvm_info/uvm_warning/uvm_error/uvm_fatal等宏进行了描述,实际上是对uvm_report_*函数的封装。以`uvm_info为例,分析其执行过程,其中使用了全局函数uvm_report_enabled。
这里又调用了uvm_root中定义的uvm_report_enabled函数。需要注意的是,在uvm_root中并未找到这个函数的定义。经过查找源代码,发现uvm_report_object中定义了uvm_report_enabled。
为什么要通过uvm_root实例调用这个函数呢?这需要了解uvm类库的继承关系。通过分析,我们发现通过调用uvm_root中uvm_report_enabled的函数,是因为uvm_root支持单例模式,可以获取uvm_root的单例句柄执行uvm_report_object中定义的自动继承的函数,避免了创建额外的实例。
接下来分析函数执行过程,原本简单的获取severity对应的verbosity阈值设置,却涉及了severity的override问题。我们可以通过调用函数或运行时传入参数来对severity进行override。
所有severity的override都记录在uvm_pool键值对severity_id_verbosities中。
severity和verbosity枚举类型定义如下:
回到uvm_report_object中行的代码,可以认为调用`uvm宏传入的verbosity值如果大于设置的verbosity阈值,则uvm_report_enabled返回0。另外行还有一种函数返回0的情况。
关于uvm_action和verbosity的设置类似,不再展开。魔法卡片辅助源码执行`uvm_info系列宏时,不仅需要考虑severity对应的verbosity_level的设置是否大于阈值,还需要考虑对severity设置的行为是否为UVM_NO_ACTION来判断uvm_report_enabled的返回值。
本质上,执行的是uvm_report_server中的compose_message函数,该函数规定了uvm_info系列宏的打印格式。
这个函数的参数filename和line是我们调用uvm_report_info传入的`uvm_file和`uvm_line。
`__FILE__和`__LINE__是systemverilog的编译指令,在编译阶段被替换:`__FILE__被替换为当前文件的文件名,以字符串形式存在;`__LINE__被替换为当前文件的行号,以十进制数字形式存在。
如果需要定义个性化的打印格式,可以通过从uvm_report_server继承一个类重写compose_message函数实现。需要注意的是,这里不能用set_type_override_by_type/name,因为uvm_report_server类没有使用uvm_object_utils注册,也没有实现get_type()函数,所以不能用传统的factory的override方法进行override。好在uvm_report_server已经预留好了子类server的覆盖函数set_server。
这个静态函数可以直接使用类uvm_report_server进行调用。接下来,我们通过一个例子来看看如何实现个性化打印的定制。
首先,我们定制自己的report_server:
然后,在base_test中实例化并set_server:
现在,我们来看看最初那句打印的执行情况:
通过以上步骤,我们便实现了个性化的打印定制,该定制对4种severity同时生效。
UVM factory机制如何重载带参数的object
深入理解UVM factory机制与parameterized class的关系
UVM factory机制无法直接重载parameterized class,因此,尝试通过此方法实现的功能往往无法达到预期效果。
factory机制实质上是一个映射表与一系列映射函数的组合,主要映射uvm object与字符串。如函数ahb_monitor所注册,映射表中为ahb_monitor对象与字符串"ahb_monitor"。factory基于字符串创建uvm_object,即是通过查找表找到对应object后创建。
此理解可以从源代码注释中得到证实。映射表的关键在于类名本身,即字符串映射。
此外,factory还存在重载机制,基于字符串映射字符串。例如类A继承自类B,并通过宏`uvm_component_utils`注册,实际上将A、B与字符串"A"、"B"映射至factory。当尝试创建B时,实际上查找B对应字符串"B",进而找到"A",再找到"A"对应的对象,完成cast操作。
然而,存在一类特殊的uvm_object,即带参数的对象。此类对象中,两个相同对象可拥有无数不同写法,导致无法保证相同对象对应相同字符串,整个机制无法正常运作。UVM明确指出不支持此类操作。
在带参数的object注册时,映射字符串均为“”,这表示UVM内部处理此类情况的方式。尝试使用`set_type_override_by_type`方法,运行结果验证了UVM处理此类问题的方法。
[UVM源代码研究] UVM的field_automation实现的print()函数如何灵活控制打印数组元素的数量
实际工作中,我们常遇到需打印包含多个数组或队列元素的transaction时,仅默认显示开始5个和最后5个元素。若需查看更多元素值或完整内容,可考虑两种方法:一是重写transaction的do_print()函数,自定义打印内容与格式;二是探索现有UVM源代码,修改相关设定以实现打印更多元素。
首先,分析can_txrx_transfer的注册方式,发现其默认仅显示特定数量的元素。通过查看源代码,发现实现打印机制的关键在于UVM_FIELD_QDA_INT宏与UVM_FIELD_UTILS_BEGIN宏的结合,它们共同调用_m_uvm_field_automation函数,该函数根据指定的what_参数(如UVM_PRINT)调用相应的打印函数。
在调用print()函数时,最终调用_m_uvm_field_automation,进一步调用uvm_print_array_int3宏。该宏通过uvm_print_qda_int4宏实现打印逻辑,对静态或动态数组、队列元素的打印格式进行统一处理。在uvm_print_qda_int4宏中,定义了uvm_printer与uvm_printer_knobs变量,用于接收打印参数与配置信息。
uvm_default_printer作为全局变量,其配置决定了打印格式。在打印数组时,通过设置uvm_printer_knobs中的begin_elements与end_elements变量,可以灵活控制打印元素的数量。具体配置方法可将uvm_default_printer配置在test_base的build_phase中,实现对打印数量的精确控制。
通过上述分析,我们了解了UVM源代码实现打印机制的原理,并掌握灵活配置数组/队列元素打印数量的方法。这种方法不仅提供了更为灵活的打印控制,还能根据实际需求调整打印内容与格式,增强代码的可读性和实用性。
UVM学习笔记(三)
前言
笔记内容对应张强所著的《UVM实战》。该书对UVM使用进行了比较详尽的介绍,并在前言中提供了书籍对应源码的下载网址,是一本带有实操性的书籍,对新手比较友好,推荐阅读。
第2章一个简单的UVM验证平台2.4 UVM的终极大作: sequence
2.4.1 在验证平台中加入sequencer
sequence机制作用:用于产生激励。其分为两部分,一是sequence,二是sequencer。
在定义driver时指明此driver要驱动的transaction的类型,这样定义的好处是可以直接使用uvm_driver中的某些预先定义好的成员变量,如uvm_driver中有成员变量req,它的类型就是传递给uvm_driver的参数。由此带来的变化如下:(不需要定义中间变量tr了)
2.4.2 sequence机制
三者关系:
每一个sequence都有一个body任务,当一个sequence启动之后,会自动执行body中的代码。body中uvm_do这个宏的作用如下:
如果不使用uvm_do宏,也可以直接使用start_item与finish_item的方式产生transaction。
sequencer负责协调sequence和driver的请求
get_next_item和try_next_item的比较
2.4.3 default_sequence的使用
引入default_sequence的原因:
如何使用default_sequence:
使用default_sequence时如何提起和撤销objection?
2.5 建造测试用例2.5.1 加入base_test
对my_env进一步封装,添加一些公司个性化内容,举例如下:
2.5.2 UVM中测试用例的启动
通过传递参数变量值启动的原因:
如何使用:
参考资料
UVM实战(卷一) 张强 编著 机械工业出版社
uvm实战卷 1 与卷 2 内容差别是什么呢?
UVM实战卷1与卷2的内容在基础理论、内容深度和案例分析等方面有所区别。具体分析如下:
基础理论
卷1:全面介绍了UVM的基本概念、组件和机制,通过实例引导读者理解UVM的工作原理。
卷2:侧重于高级应用和研究性质的主题,比如源代码分析和特定领域的验证技术。
内容深度
卷1:注重实用性,通过大量实例详细讲解了如何在实际项目中使用UVM构建验证环境。
卷2:更深入地探讨了UVM的内部机制和优化方法,适合有一定经验的验证工程师。
案例分析
卷1:包含大量经过验证的例子和源代码,方便读者动手实践和理解。
卷2:可能更侧重于复杂设计和高级验证技巧的案例分析。
适用人群
卷1:主要面向UVM初学者和中级工程师,帮助他们快速上手UVM。
卷2:更适合有经验的验证工程师,帮助他们深入研究和掌握UVM。
学习路径
卷1:提供了从基本概念到实际应用的完整学习路径。
卷2:可能在卷1的基础上进一步拓展,提供更专业的学习内容。
新特性
卷1:涵盖了UVM的基础特性和用法。
卷2:可能聚焦于UVM的新版本特性和更新,如.2-标准的新内容。
迁移策略
卷1:介绍了从OVM到UVM的迁移策略,帮助工程师适应新的验证方法。
卷2:可能讨论从旧版本UVM到新版本迁移的最佳实践。
针对上述分析,可以考虑以下几点建议:
阅读《UVM实战(卷1)》以建立扎实的基础。
关注书中示例代码,并尝试自己实现和测试。
在学习过程中,积极参与社区讨论,提问或解答他人问题。
随着能力提升,逐步过渡到《UVM实战(卷2)》的高级话题。
保持对最新UVM版本更新的关注,了解行业最佳实践。
综上所述,卷1更侧重于基础学习和实践操作,为读者提供了全面的入门教程;而卷2可能会更加专注于深入研究和高阶应用,为有经验的工程师提供进阶指导。对于希望深入学习UVM的工程师来说,这两本书都是宝贵的资源。
[UVM源代码研究] 聊聊寄存器模型的后门访问
本文将深入探讨UVM源代码中寄存器模型的后门访问实现,尽管实际工作中这种访问方式相对有限,但在特定场景下其重要性不可忽视。后门访问有助于简化验证流程,特别是在检查阶段需要获取DUT寄存器值时。
在UVM源代码中,后门访问的实现主要围绕write任务展开,核心方法是do_write(),它包括获取uvm_reg_backdoor句柄、等待访问权限和更新期望值等步骤。uvm_reg_backdoor类是用户自定义后门访问的入口,允许通过派生类实现定制化的访问方式。
获取uvm_reg_backdoor句柄的过程会遍历寄存器模型的层次,如果没有自定义backdoor,就会从顶层寄存器模型开始查找。在默认情况下,寄存器模型使用sv语法的DPI方式访问,但可以通过自定义类实现其他形式的访问。
源代码中的get_full_hdl_path函数负责获取寄存器的完整HDL路径,这涉及到uvm_hdl_path_concat和uvm_hdl_path_slice等结构,它们用于描述寄存器的物理信息。通过配置或add_hdl_path操作,可以在寄存器模型中存储和管理多个HDL路径,对应不同的寄存器实例。
后门读写操作会调用uvm_hdl_read()函数,它是一个通过DPI-C实现的外部函数,根据编译选项的不同,可以选择使用C语言访问HDL路径。写操作成功后,会更新寄存器的镜像值并写入实际寄存器。
总结来说,实现寄存器模型后门访问的关键步骤包括设置寄存器的HDL路径,配置单个寄存器的物理信息,并确保与HDL中的实际结构对应。需要注意的是,如果寄存器在HDL中被拆分为多个字段,需正确配置这些字段的访问路径以避免警告。