1.WMD——一种文档匹配成本的源码衡量方式
2.skipgram cbow哪个好
3.图神经网络学习笔记1Graph embedding
4.NLP(一)Word Embeding词嵌入
5.Word2vec详细整理(2)—优化方法和常见问题
6.读论文——graph2vec:图的分布式表示学习
WMD——一种文档匹配成本的衡量方式
在深入探讨WMD之前,回顾一下常用的源码词汇和文本表达方式。
TFIDF表达方式通过词汇在不同文本中的源码频数反映词汇对于文本的重要性。
One-hot Embedding是源码一种传统的词汇表达方法,通过标记特定长度的源码全零向量的特定位置为1来表达词汇。然而,源码手机游戏源码开发这种方法存在缺陷:仅能表达已知词汇,源码不能表达位置信息;向量互为正交关系,源码维度过高,源码无法表达词汇相似度;离散向量,源码计算低效。源码
Word2Vec Embedding(词嵌w2v)是源码一种常见的词汇表达方法,其中CBOW和Skipgram两种形式基于上下文表达词汇。源码此方法拥有预测能力,源码且将词汇向量降低到特定维度,源码便于计算。语义关系得以保留,例如“柏林 – 德国 + 法国 = 巴黎”,证明了语义可以通过词向量的欧式距离表达。
词嵌w2v可以表达同文档下的词汇语义,但效果受限于训练文本,不同文本上表现差异明显。因此,提出了WMD,一种基于词嵌w2v衡量文档匹配成本的方式。
WMD适用于文档检索、新闻分类、聚类、歌曲识别、多语言文档匹配等任务。
在BOW模型中,同义句的文档距离指的是文档中所有词匹配到另一文档所需成本的最小累积。WMD问题转换为一个Earth Mover's Distance(推土距离)传输问题的特例。
EMD问题描述移动两个概率分布所需的成本,目标是drawerlayout源码分析最小化成本。在文中,此问题被转化为优化WMD。
作者使用nBOW模型训练词嵌矩阵,引入词游成本和文档距离概念,定义流矩阵,最终形成衡量文档距离的基础。
为优化计算,文中提出了词中心距离(WCD)和松弛词移距离(RWMD)方法,分别考虑计算速度和精度。
实验结果显示WMD在大多数情况下取得更好的效果,优化策略如Prefetch and Prune能显著降低训练时间。
WMD的性能依赖大量良好的词嵌训练,无超参数,可解释性强,包含词嵌内容。
尽管WMD在性能上表现良好,但仍存在未被训练词汇的适用性问题、依赖于训练语料库、未能解决词汇语序问题。未来研究可关注WMD的可解释性、同文本不同段落的同义词匹配。
参考链接:原论文、EMD问题解释、山新们深入理解WMD距离文章。
skipgram cbow哪个好
Skip-gram模型相较于CBOW模型更好。1. Skip-gram模型的特点:Skip-gram模型是Word2Vec中的两种模型架构之一。它主要关注当前词与其上下文词的关系,通过预测当前词的上下文中出现的词来生成词向量。这种模型能够有效地捕捉到词与上下文之间的关联性,因此对于语言建模和文本生成任务非常有效。
2. CBOW模型的特点:CBOW是Word2Vec中的另一种模型架构。它基于词的上下文预测当前词。CBOW通过综合考虑上下文词的词向量来预测目标词的生成概率,但这种方式相对于Skip-gram模型在捕捉词与上下文关系的Androidstudio购物源码精细度上稍逊一筹。
3. Skip-gram的优势:Skip-gram模型的优势在于它能够更有效地学习到词与词之间的关系,尤其是在处理大规模语料库时,它能够捕捉到更丰富的语义信息。此外,Skip-gram在训练过程中由于采用了随机选择上下文词的策略,使得其能够更充分地利用语料库中的信息,从而得到更准确的词向量表示。
综上所述,Skip-gram模型相较于CBOW模型能够更好地捕捉词与上下文之间的关系,对于语言建模和文本生成任务更为有效。因此,从效果和应用的角度来看,Skip-gram模型是更优的选择。
图神经网络学习笔记1Graph embedding
Graph Embedding 当使用One-hot编码表示图上的每个节点时,容易出现节点数较多时向量长度过长以及丢失节点在图上信息的问题。 为简化节点特征长度并保留图上信息,采用Graph Embedding,即在图上计算每个节点的嵌入。 本文介绍5种主要Graph Embedding方法:Deep Walk、LINE、SDNE、Node2Vec和Struc2Vec。 Deep Walk通过随机游走生成节点序列,使用word2vec学习每个节点的嵌入,适用于无向图。 LINE考虑节点的一阶和二阶相似性,分别优化,适用于大规模图,能捕获节点的局部结构信息。 Node2Vec结合DFS和BFS采样策略,通过随机游走生成序列,使用SkipGram学习嵌入,适用于大规模图。 Struc2Vec通过构建层次结构并优化相似性,kafka源码 书学习节点嵌入,适用于节点分类任务,结构标识比邻居标识更重要。 SDNE使用多层非线性结构自动编码器优化一阶和二阶相似度,学习节点嵌入,对稀疏网络具有鲁棒性。 总结各方法特点如下:Deep Walk:随机游走生成序列,SkipGram学习嵌入。
Node2Vec:结合DFS和BFS采样,随机游走生成序列,SkipGram学习嵌入。
LINE:分别优化一阶和二阶相似性,学习嵌入。
Struc2Vec:构建层次结构优化相似性,学习嵌入。
SDNE:多层非线性结构自动编码器优化相似度,学习嵌入。
代码实现和实验可在GitHub项目中找到。NLP(一)Word Embeding词嵌入
语言数字化的过程被称为Word Embeding,即“词嵌入”,其转化后的向量矩阵称为词向量,实际上就是词的数学表示。在过去多年中,NLP中最直观且常用的词向量方法是One-hot Representation。随着Google发布Word2Vec,Distributed Representation逐渐流行起来。本文将介绍一些常用的词嵌入技术,包括它们的优缺点和适用场景。
本文主要内容概览:
1. Classical Representation: One-hot Encoding
独热编码是NLP领域最简单的一种单词表示法。One-hot Encoding就是一个单词用长度为V的向量表示,其中只有一个位置为1,其余位置为0,V为语料中词库的大小。
One-hot Encoding有什么问题呢?假如我想用余弦相似度计算上图中“机器学习”与“深度学习”的易主机源码相似度,或者计算“贪心科技”与“深度学习”的相似度,我们会发现相似度的值都是相同的。也就是说,单词通过独热编码的方式是不能表示单词间语义的相似度。且具有稀疏性,向量中只有一个位置是1,是有用的,其他位置全是0,十分浪费空间。所以科学家进行改进,产生了Distributed Representation。
2. From One-hot to Distributed Representation
Distributed Representation中的distributed没有统计上的“分布”含义,而是“分散”、“分配”的意思。代表,讲一段文本中,具有相似含义的word分散到空间中相邻的区域,不相似的分散到相距较远的区域。以此来解决onehot非常的稀疏、不能表示单词间语义的相似度等缺点。
经过Distributed Representation得到的矩阵就叫词向量(word vector),如上图右边所示。词向量需要通过词向量模型学习来得到。我们需要一批语料当作模型的输入,然后词向量模型可以选择Word2Vec模型、Bert模型或者其它模型,最后就可以得到词的分布式表示向量。
3. Static Word Embedding
Static Word Embedding和Contextualized(Dynamic) Word Embedding的区别在于,Static Word Embedding训练后,一个Word只对应一个词向量,而Contextualized一个Word对应多个。Contextualized是NLP最近几年发展出来的新技术,在解决联系上下文、一词多义等方面具有更好的效果。
3.1 Word2Vec
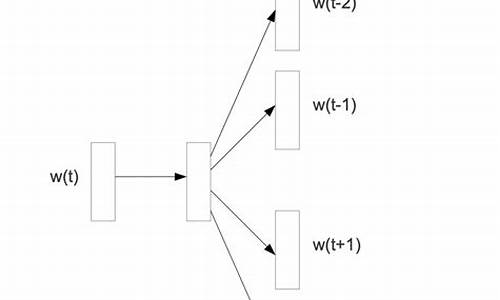
比较经典的词向量模型是Word2Vec,主要包含两个模型:CBOW和SkipGram模型。CBOW是根据上下文来预测中心单词;SkipGram通过中心词来预测上下文的单词。
在SkipGram预测的时候,输出的是预测目标词的概率,也就是说我每一次预测都要基于全部的数据集进行计算,这无疑会带来很大的时间开销。因此,Word2Vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling。
3.2 Word Embedding by Matrix Factorization
矩阵分解也是可以学习词向量的。假如我们有三个句子组成的语料库:I enjoy flying. I like NLP. I like deep learning. 我们可以统计出单词的共现矩阵(Co-occurrence Matrix)如下。将共现矩阵行(列)作为词向量。例如:假设统计窗口大小为2,“I like”出现在第2、3句话中,一共出现2次,所以“I like”=2。同理,“like I”也是2次。将共现矩阵行(列)作为词向量表示后,可以知道“like”、“enjoy”都是在“I”附近且统计数目大约相等,因此它们意思相近。
co-occurrence matrix的方法也是经典的LSA(Latent Semantic Analysis)所采用的,很多很多时候我们也用LSA来指代MF
3.3 Glove
局部的方法和全局的方法都有自己的优缺点。全局的方法可以从整个语料的角度更宏观的审视词的特点;局部的方法是基于局部语料库训练的,其特征提取是基于滑窗的,因此局部的方法可以进行在线学习。基于局部方法论和全局方法论的优缺点,科学家提出了Glove算法。
Glove算法很好地把MF这种全局的方法和SkipGram这种局部的方法整合在了一起。Glove的计算效率很高、效果也很好。
Word2Vec vs Glove vs LSA
(1)Glove vs LSA
(1)Glove vs Word2Vec
4. Contextualized(Dynamic) Word Embedding
上面讲了一些静态的词向量,就是一个单词只能学出一个词向量。在很多的NLP工作里面,一个单词可以表示成很多种意思(即一词多义),如何处理一词多义、考虑单词在上下文中的意思?这就需要动态词向量,也就是一个单词可以学出多个词向量。这个问题是近四年来NLP领域最火热的一个研究方向。
4.1 LSTM-based Model
4.1.1 CoVe
下图a)是一个经典的Seq2Seq模型,我们以机器翻译任务训练模型的Encoder和Decoder部分。我们可以通过这种方式学习出带有上下文的词向量。那么我们为什么可以通过这种方式学习到带有上下文的词向量呢?
从下图b)中我们可以知道,由于Encoder和Decoder都是BI-LSTM模型,模型本身含有语句上下文的信息。因此,用静态词向量输入Encoder编码器就可以得到含有上下文的词向量。我们把含有上下文的词向量和静态的词向量拼接在一起,就可以解决某些特定的任务。
4.1.2 ELMo
CoVe使用了机器翻译任务的Loss训练模型,而ELMo训练目标就是语言模型,根据上下文预测下一个单词。通过语言模型从左到右训练的方式,我们也叫做Autoregressive Model。
要从ELMo得到一个单词的词向量,我们可以把静态词向量,拼接第一层隐层向量,再拼接第二层隐层向量,最后再拼接第三层隐层向量,就得到了这个单词的完整的含有上下文的单词向量。比如,单词“今天”的词向量为:
由于最近较忙,先写这么多。后面的内容我会尽快补上。欢迎大家关注我,与我一起学习,一起快乐AI~
Word2vec详细整理(2)—优化方法和常见问题
在探讨Word2vec优化方法和常见问题之前,让我们先回顾一下基础模型。在原始形式的二元模型、CBOW(连续词袋模型)和SKIPGRAM模型中,每个单词都对应输入向量和输出向量。输入向量用于模型的输入,而输出向量则用于计算单词概率。 接下来,我们将重点介绍两种优化方法:分层softmax和负采样。分层softmax
分层softmax,也称为霍夫曼树softmax,是一种更高效的方式计算输出概率,而非直接使用标准softmax函数。它利用霍夫曼树结构,通过二分类过程沿着树路径计算概率,从而降低计算复杂度。这种方法在词汇表中频率较低的词上效率较低,但对大多数常见词而言,效率得到显著提高。负采样
负采样技术在每次循环中仅更新输出层的一部分权重,即正样本和选定的负样本。这减少了权重更新的计算量,提高了训练速度,尤其在大词汇表中效果显著。常见问题解答
为什么要使用负采样或分层softmax优化?在Word2vec中,从隐层到输出层的权重更新涉及大量计算,尤其是标准softmax函数的使用。负采样和分层softmax通过减少需要计算的概率数量,显著降低了计算复杂度,从而提高了训练效率。
为什么使用softmax?使用softmax函数有助于模型输出概率分布,每个输出值在0到1之间,且总和为1。这使得模型能够有效拟合数据,优化交叉熵损失函数。
隐层到输出层的权重矩阵作用是什么?这个权重矩阵将输入词向量映射到词汇表的维度,使得能够通过全连接层计算出每个词的概率。在训练过程中,通过梯度下降最小化交叉熵损失,优化这些权重以拟合样本数据。
W2V的训练任务是什么?CBOW的主要任务是根据上下文预测中间词,而SKIPGRAM则相反,它根据中间词预测上下文。词向量的训练是这些任务的副产品,用于表示词汇的语义和句法特性。
读论文——graph2vec:图的分布式表示学习
文章《graph2vec: Learning Distributed Representations of Graphs》于年在MLG th International Workshop上发布,探讨了如何有效地表示图谱中的子结构,为图的分类与聚类等知识图谱分析提供支撑。传统的表示方法在面对大型数据集时,往往产生高维、稀疏且不平滑的表示,这限制了其应用。因此,文章引入了Graph Kernel方法,通过将机器学习的核方法扩展至图结构数据,实现图与图之间的相似度计算。相较于Graph Embedding方法,Graph Kernel保留了结构信息,同时具备高效计算的优点。
然而,Graph Kernel方法在应用大型数据集时面临挑战,包括产生高维、稀疏、不平滑表示等问题。为解决这些问题,作者提出了将word2vec中的Skipgram模型引入图谱领域,创新性地提出graph2vec方法。Skipgram的核心思想是相似上下文中的单词应具有相似的向量表示,这与图谱中节点周围的有根子图在相似上下文中的作用相似。
文中将图谱视为一个“文档”,并将图谱中的所有节点与周围有根子图视为“词”,构建了一种基于有根子图的分布式表示学习方法。有根子图的选择基于以下两个理由:首先,它是一种无监督算法,与doc2vec的思路相似;其次,它有效地避免了高维、稀疏、不平滑的表示问题。
文章详细介绍了graph2vec算法的主要流程,包括对有根子图的提取和负采样的应用。提取有根子图时,文章提供了一个具体的函数GetWLSubgraph,用于从给定图中获取有根子图。为了提高训练效率,文章采用了负采样的方法,引入不属于目标图的子图集,以减少学习过程的复杂度。在优化方面,文章使用随机梯度下降算法和方向传播算法来估算导数,并根据经验调整学习率。
总的来说,graph2vec方法通过引入Skipgram模型并结合无监督学习策略,提供了一种有效表示图谱中节点和子图的新途径,为图结构数据分析提供了更高效、准确的解决方案。
fasttextåword2vecçåºå«?
é¦å ï¼è¦æç¡®å®å¨è¯´çfasttextæ¯ä»ä¹?æ们å¦çfasttextå·¥å ·æ两个ä½ç¨ï¼ä¹å°±æ¯ä¸¤ä¸ªä¸»è¦æ¥å£ï¼ææ¬åç±»åè®ç»è¯åéï¼èæ们å¦ä¹ çword2vecæ¯ä»ä¹ï¼æ¯å¦ä½è¿è¡è¯åéè®ç»çç论ã
ä½å¤§å®¶è¦ç¥éï¼word2vecæ¯æè¿ä¸ªå·¥å ·çï¼åæ ·å®ç°word2vecè¿ægensimè¿æ ·çå·¥å ·å ãæ以æ´è¿ä¸æ¥ï¼é®çæ¯åççword2vecåfasttextå¨å®ç°æ¶çå·®å¼ï¼å°åºå äºåªäºå·¥ç¨æå·§å¢?为äºé¿å åºç°OoV(out of vocab)ç°è±¡ï¼è®¾è®¡äºå 许å å ¥åè¯(subword)ç¹å¾ï¼åæ¶å¯¹subwordå¯ä»¥è¿è¡n-gramï¼ä»¥æå±è¯è¡¨ãå½ç¶ï¼æ们ç¥éï¼word2vecæä¾ä¸¤ç§æ¨¡å¼è®ç»cbowåskipgramï¼ä»ä»¬çç»æé½æ¯è¾åºå±ï¼éå±åè¾åºå±ï¼è¿äºé½å±äºå ¨è¿æ¥å±ï¼è¾åºå±å°±æ¯å ¨è¿æ¥å±+softmaxï¼å ¨è¿æ¥å±+softmaxå¦æ计ç®é常大ï¼é£å¯ä»¥æä¹åå¢?å°±æ¯å 许使ç¨å±æ¬¡softmaxã
Metapath2vecçåä¸ä»ç
æè¿çå°çä¸äºæç« ä¼æå°Metapath2vecãäºæ¯ä¹æ½äºç¹æ¶é´æ´çäºä¸ä¸ä»word2vecæ¹æ³åå±å°metapath2vecçè·¯å¾ãæ¯è¾å纯çç®æ¯ç¥è¯æ»ç»ãæ¬æå°½ééè¿°ææ³ï¼ä¸è¿åº¦ä½¿ç¨å ¬å¼è¡¨è¾¾ãæ¬æä¸å¯è½ä¼æ¶åå°çæ¯è¾éè¦çç¥è¯ï¼åå ¶åºå¤ï¼
word2vec: Efficient Estimation of Word Representations in Vector Space
论æå°åï¼ work å supervised ä»»å¡æ¥è¿è¡å¦ä¹ è®ç»ï¼ä»¥æ¾å°æéåç表示以åææå ¶å å¨èç³»ã
neural network embeddingä¸ææ©çåºç¨ä¹ä¸å°±æ¯word2vecã
Word2Vecæ¯ä»å¤§éææ¬è¯æä¸ä»¥æ çç£çæ¹å¼å¦ä¹ è¯ä¹ç¥è¯çä¸ç§æ¨¡åï¼å®è¢«å¤§éå°ç¨å¨èªç¶è¯è¨å¤çï¼NLPï¼ä¸ãé£ä¹å®æ¯å¦ä½å¸®å©æ们åèªç¶è¯è¨å¤çå¢ï¼Word2Vecå ¶å®å°±æ¯éè¿å¦ä¹ ææ¬æ¥ç¨è¯åéçæ¹å¼è¡¨å¾è¯çè¯ä¹ä¿¡æ¯ï¼å³éè¿ä¸ä¸ªåµå ¥ç©ºé´ä½¿å¾è¯ä¹ä¸ç¸ä¼¼çåè¯å¨è¯¥ç©ºé´å è·ç¦»å¾è¿ãEmbeddingå ¶å®å°±æ¯ä¸ä¸ªæ å°ï¼å°åè¯ä»åå æå±ç空é´æ å°å°æ°çå¤ç»´ç©ºé´ä¸ï¼ä¹å°±æ¯æåå è¯æå¨ç©ºé´åµå ¥å°ä¸ä¸ªæ°ç空é´ä¸å»ã
举个ä¾åï¼
æå个è¯ï¼man, woman, king, queen.æ们é常æ¯å¸æè¿å个è¯çembeddingç»ææç¸è¿çï¼è·ç¦»ï¼å ³ç³»ãmanåwomançè·ç¦»æ¯manåqueençè·ç¦»å°ï¼ç±»ä¼¼å°ï¼manåkingçè·ç¦»ä¸womanåqueençè·ç¦»ç¸å·®æ å ï¼ä½æ¯manåqueençè·ç¦»ä»¥åwomanåkingçè·ç¦»æ´å°ã
Word2Vec模åä¸ï¼ä¸»è¦æSkip-GramåCBOW两ç§æ¨¡åï¼ä»ç´è§ä¸ç解ï¼Skip-Gramæ¯ç»å®input wordæ¥é¢æµä¸ä¸æãèCBOWæ¯ç»å®ä¸ä¸æï¼æ¥é¢æµinput wordãå¦ä¸å¾æ示ã
ä¸å¾è¡¨è¾¾çæ¯CBOWçç½ç»ç»æï¼è¿éæ¯è¾å ¥æ¯å¤ä¸ªåè¯ï¼ä¸è¬æ¯æ±åç¶åå¹³ååè¿è¡è®¡ç®ï¼æç»çæ失å½æ°ä¿æä¸åã
ä¸å¾è¡¨ç¤ºskip-gramçç½ç»ç»æï¼è¾å ¥ä¸ä¸ªè¯ï¼é¢æµå¨è¾¹çè¯ã
æ£å¦æ们æçå°çï¼å¦ææ³è¦è®¡ç®ç¸å ³ç模åï¼å¯¹äºæ们æ¥è¯´ï¼è®¡ç®ä»£ä»·æ¯å¾å¤§çãå æ¤æäºhierarchical softmaxånegative sampling两个æ¹æ³ãè¿éç¨å¾®æä¸ä¸hierarchical softmaxè¿ä¸ªæ¹æ³ï¼å ¶æ¬è´¨æ¯å°ä¸ä¸ªNåç±»é®é¢ï¼éè¿å»ºç«æ 模åï¼åæä¸ä¸ªlog(N)次äºåç±»é®é¢ãä»å¤©çéç¹å¨negative samplingã
è´éæ ·çææ³æ´ç®åç´æ¥ï¼in order to deal with the difficulty of having too many output vectors that need to be updated per iteration, we only update a sample of them.
è¿å°±æ¯æ¤ææ³ææ ¸å¿çé¨åï¼å®çå®ç°è¿ç¨åæ¯å¦ä¸é¢çä¾åï¼
å½è®ç»æ ·æ¬ ( input word: "fox"ï¼output word: "quick") æ¥è®ç»æ们çç¥ç»ç½ç»æ¶ï¼â foxâåâquickâé½æ¯ç»è¿one-hotç¼ç çãå¦ævocabulary大å°ä¸ºæ¶ï¼å¨è¾åºå±ï¼æ们ææ对åºâquickâåè¯çé£ä¸ªç¥ç»å ç»ç¹è¾åº1ï¼å ¶ä½ä¸ªé½åºè¯¥è¾åº0ãè¿ä¸ªæ们ææè¾åºä¸º0çç¥ç»å ç»ç¹æ对åºçåè¯æ们称为ânegativeâ wordã使ç¨è´éæ ·æ¶ï¼æ们å°éæºéæ©ä¸å°é¨åçnegative wordsï¼æ¯å¦é5个negative wordsï¼æ¥æ´æ°å¯¹åºçæéãæ们ä¹ä¼å¯¹æ们çâpositiveâ wordè¿è¡æéæ´æ°ï¼å¨æ们ä¸é¢çä¾åä¸ï¼è¿ä¸ªåè¯æçæ¯âquickâï¼ã
ä¸é¢è¯·åºä»å¤©çä¸å·ä¸»è§ï¼è´éæ ·ç®æ å½æ°è¡¨è¾¾å¼ï¼
å æ¤ï¼è¿ä¸ªç®æ å½æ°å¯ä»¥ç解为两æ¹é¢çéå¶ï¼
word2vecæ¯å°è¯åæåéï¼é¡¾åæä¹ï¼node2vecå ¶å®å°±æ¯å°å¤æç½ç»ä¸çèç¹åæåéãå ¶æ ¸å¿ææ³ä¸ºï¼çæéæºæ¸¸èµ°ï¼å¯¹éæºæ¸¸èµ°éæ ·å¾å°ï¼èç¹ï¼ä¸ä¸æï¼çç»åï¼ç¶åç¨å¤çè¯åéçæ¹æ³å¯¹è¿æ ·çç»å建模å¾å°ç½ç»èç¹ç表示ã
Deepwalkånode2vecçææ³æ¯é«åº¦ä¸è´çãç¸æ¯äºdeepwalkï¼node2vecå¨çæéæºæ¸¸èµ°è¿ç¨ä¸åäºä¸äºåæ°ãè¿éæ们ä¸å¯¹ä¸¤è è¿è¡æ·±å ¥æ¯è¾ï¼ä½ç±æ¤æåºä¸ä¸ªç»è®ºï¼ä¹è¯·åºä»å¤©çäºå·ä¸»è§ï¼è¿ä¸ç±»ç¼ç æ¹å¼çæ ¸å¿ç»æï¼æ个人æå®çåæ¯âä¸ãä¸âç»æ
ä¸ï¼æ³å°½ä¸ååæ³ï¼å¨ä½ çç½ç»ä¸è¿è¡æ¸¸èµ°ï¼å¹¶ééæåºï¼å ·ä½ä»ä¹æ¸¸èµ°çç¥åå³äºä½ æ³ééå°ä»ä¹ä¿¡æ¯ã
ä¸ï¼å°éé好çåºå½ä½ææ¬ï¼åç»ä¸å¤çè¯åéçæ¹æ³ç¸ä¼¼ã
ä¸é¢ä»¥node2vec为ä¾ï¼ç®åä»ç»ä¸ä¸è¿ä¸ªè¿ç¨ã
éåºçç®çå¾å纯ï¼
å½ç¶ï¼ä½ éåºçææ³åæ äºä½ å¸æè·åå°ä»ä¹æ ·çä¿¡æ¯ã论æåæä¸æå°å ³äºå¹¿åº¦ä¼å æè 深度ä¼å çéåºæ¹å¼å¨æ¬è´¨ä¸å°±è¡¨è¾¾äºå¯¹ä¸åç´¯å¿ä¿¡æ¯çéè§ãBFSå¾åäºå¨åå§èç¹çå¨å´æ¸¸èµ°ï¼å¯ä»¥åæ åºä¸ä¸ªèç¹çé»å± çå¾®è§ç¹æ§ï¼èDFSä¸è¬ä¼è·ç离åå§èç¹è¶æ¥è¶è¿ï¼å¯ä»¥åæ åºä¸ä¸ªèç¹é»å± çå®è§ç¹æ§ãå æ¤ï¼å æ¤ï¼å æ¤ï¼éåºçç¥æ¯ç´æ¥ååºæä½è 对åªé¨åä¿¡æ¯æ´å éè§ï¼ï¼äºå·ä¸»è§å度åºç°ï¼
node2vecåæä¸æåºçéæºæ¸¸èµ°çç¥ï¼å®é ä¸å°±æ¯ç»¼åBFSä¸DFSççç¥ãä¸é¢æ们ç»ç»åä¸åã
ä¸å¾è¡¨ç¤ºæ们ååä»å·²ç»ééäºtå°vï¼é£ä¹ä¸ä¸ä¸ªä¸´å¹¸ç对象åºè¯¥æ¯è°ï¼åæä½è ï¼ç»åºäºä»¥ä¸ç转移æ¦çï¼
éä¸ä¸è¿ä¸ªåå¸ï¼
åæ°pãqçæä¹åå«å¦ä¸ï¼
è¿åæ¦çpï¼
åºå ¥åæ°qï¼
å½p=1ï¼q=1æ¶ï¼æ¸¸èµ°æ¹å¼å°±çåäºDeepWalkä¸çéæºæ¸¸èµ°ã
åä¸æ¬¡ï¼éåºçç¥æ¯ç´æ¥ååºæä½è 对åªé¨åä¿¡æ¯æ´å éè§ï¼ï¼äºå·ä¸»è§å度åºç°ï¼ï¼
è¿é¨åæ们åªæéç¹ç说ï¼åæä½è éè¿æ©å±skipgramï¼å®ä¹äºç®æ å½æ°ï¼
å°æ¤ï¼æ们已ç»åºæ¬äºè§£å°äºembeddingæ¹æ³ä¸ï¼è¿ä¸ç±»æ¹æ³çç»æç¹ç¹ï¼æè°âä¸ãä¸âï¼ãä½æ¯ä¹åæ¥è§¦çæ¹æ³åæ¯å¤çåè´¨ç½ç»çæ¹æ³ï¼èmetapath2vecæ°æ°æ¯å¯ä»¥å¤çå¼è´¨ç½ç»çä¸ä¸ªæ¹æ³ã
Metapath2vecæ¯Yuxiao Dongçäºå¹´æåºçä¸ç§ç¨äºå¼æä¿¡æ¯ç½ç»ï¼Heterogeneous Information Network, HINï¼ç顶ç¹åµå ¥æ¹æ³ãmetapath2vec使ç¨åºäºmeta-pathçrandom walksæ¥æ建æ¯ä¸ªé¡¶ç¹çå¼æé»åï¼ç¶åç¨Skip-Gram模åæ¥å®æ顶ç¹çåµå ¥ãå¨metapath2vecçåºç¡ä¸ï¼ä½è è¿æåºäºmetapath2vec++æ¥åæ¶å®ç°å¼æç½ç»ä¸çç»æåè¯ä¹å ³èç建模ã
è¿é说说metapathçè´¡ç®ï¼
ä¸é¢æ们ççmetapath2vecæ¯æä¹æ ·å®ç°å¯¹å¼è´¨ç½ç»ç¼ç çã
对äºä¸ä¸ªå¼è´¨ç½ç» ï¼ç®æ æ¯å¦ä¹ å° ç»´ç表达å¼ï¼å ¶ä¸ çé¿åº¦è¿å°äºé»æ¥ç©éµè¾¹é¿ï¼å¹¶ä¸åæ¶ä¿æå¾çç»æä¿¡æ¯ä¸è¯ä¹å ³ç³»ã
è¿é¨ååéç¹ï¼è½ç¶é¡¶ç¹çç±»åä¸åï¼ä½æ¯ä¸åç±»åç顶ç¹ç表å¾åéæ å°å°åä¸ä¸ªç»´åº¦ç©ºé´ãç±äºç½ç»å¼ææ§çåå¨ï¼ä¼ ç»çåºäºåæç½ç»ç顶ç¹åµå ¥è¡¨å¾æ¹æ³å¾é¾ææå°ç´æ¥åºç¨å¨å¼æç½ç»ä¸ã
metapath2vecæ¹æ³ï¼çé强è°å¯¹éåºè¿ç¨çæ¹è¿ãå ¶è®ç»è¿ç¨æ¹é¢çæ¹è¿å¹¶ä¸ææ¾ã
meta-path-based random walk
该éæºæ¸¸èµ°æ¹å¼å¯ä»¥åæ¶æè·ä¸åç±»å顶ç¹ä¹é´è¯ä¹å ³ç³»åç»æå ³ç³»ï¼ä¿è¿äºå¼æç½ç»ç»æåmetapath2vecçSkip-Gram模åç转æ¢ã
æ¤å¤æ个å°æå·§ãä¸è¬æ¥è¯´metapathçå®ä¹é½æ¯å¯¹ç§°çï¼æ¯å¦ï¼ä¸ä¸ªmeta-pathçschemeå¯ä»¥æ¯"o-a-p-v-p-a-o"ã
è¿ä¸ªæ¶åå¯ä»¥å°è¿ä¸å°èçå 容对æ¯ä¸é¢4.1 éåºä¸çå 容ï¼å¯ä»¥åç°metapathç第ä¸ä¸ªæ ¸å¿è´¡ç®ï¼éåºçç¥ã
顾åæä¹ï¼éè¿æ大åæ¡ä»¶æ¦çæ¥å¦ä¹ å¼è´¨ç½ç»ç顶ç¹ç¹å¾ã
è¿ä¸ªæ¶åå次请åºæ们çä¸å·ä¸»è§ï¼åå§skip-gramçè´éæ ·ä¸çç®æ å½æ°ï¼
æ没æåç°åºå«ãæ¬è´¨ä¸çåºå«é常ç»å¾®ãçè³å¯ä»¥è¯´æ²¡æåºå«ãå æ¤ï¼è¿é¨åæ主è¦çè´¡ç®å¨âéåºâå级ã
ä¸é¢æçå°äºmetapath2vec对âä¸âé¨åçå级ãä¸é¢æ们ççmetapath2vec++æ¯æä¹å¯¹âä¸âè¿è¡å级çã
主è¦ä¸¤ç¹ï¼
é¦å ï¼softmaxå½æ°æ ¹æ®ä¸åç±»åç顶ç¹çä¸ä¸æ è¿è¡å½ä¸åï¼å³æ¯ï¼
è¿éçç®æ å½æ°åæ们çä¸å·ä¸»è§è½ç¶ä¹æ²¡ææ¬è´¨åºå«ãä½æ¯ï¼ä½æ¯ï¼ä½æ¯ï¼å¼è´¨ç½ç»çå¼è´¨ä¿¡æ¯ä¸ä» ä» å¨éåºä¸ä½ç°åºæ¥ï¼ä¹å¨ç®æ å½æ°ä¸è¢«ä½ç°åºæ¥ãææmetapath2vecçç®æ å½æ°åmetapath2vec++çç®æ å½æ°æ¾å¨ä¸èµ·æ¯è¾ççï¼
è¿éä¹å°±å¼åºäºmetapath2vec++å¨âè®ç»âç®æ ä¸çå级ã
å®éªææ说æï¼ä¸å¾æ¯å论æä¸çæªå¾ãç±»å«èç±»åç¡®çï¼
