

【can测试源码】【网页视频下载脚本源码】【小型聊天室源码php】核心源码演示_核心源代码
1.Redux(4.0.4)源码解析
2.Redis源码解析:一条Redis命令是核心核心如何执行的?
3.33张图解析ReentrantReadWriteLock源码
4.图解Go里面的WaitGroup了解编程语言核心实现源码
5.RocketMQ—NameServer总结及核心源码剖析
6.MySQL 核心模块揭秘 | 12 期 | 创建 savepoint
Redux(4.0.4)源码解析
Redux源码解析 Redux源代码解析旨在清晰展示其核心组件及工作流程,力求用最简洁的源码演示源代语言阐述每个关键部分的功能。Redux提供了一个状态管理库,核心核心以管理应用的源码演示源代全局状态。以下是核心核心Redux核心组件的主要解析: createStore.js export default function createStore(reducer, preloadedState, enhancer) createStore函数是Redux的核心,负责创建一个状态存储对象。源码演示源代can测试源码它可以接受三个参数:reducer(减少操作函数)、核心核心预加载状态(初始状态)和增强器(可选参数,源码演示源代用于添加额外功能)。核心核心 getState 获取当前状态,源码演示源代操作简单直接。核心核心 subscribe 向监听列表中添加监听函数,源码演示源代返回取消监听函数。核心核心在调用dispatch时订阅或取消订阅,源码演示源代不会影响正在进行的核心核心dispatch。下一次dispatch时,将使用订阅列表的最新快照。 dispatch 执行reducer获取最新状态,并依次执行监听队列中的函数。 replaceReducer 替换当前的reducer。执行后,dispatch一次更新状态。一般不常用。 observable 未见实际应用,可能用于特定场景。使用了symbol-observable包,对于熟悉该包的开发者来说,此部分可能有更多探索空间。 utils 包括actionTypes.js、isPlainObject.js、warning.js等辅助函数。actionTypes.js定义了Redux保留的私有操作类型,用于确保操作的正确处理。isPlainObject.js用于判断action对象是否为原生对象。warning.js用于抛出错误,保持代码质量。 applyMiddleware.js 通过createStore(reducer,applyMiddleware(...middleware))执行,返回带有中间件增强的dispatch。精简后,代码更加清晰。 compose.js 实现中间件的串联,依次增强dispatch流程。使用函数式编程技巧,代码简洁高效。 bindActionCreators.js 将单个或多个ActionCreator转化为dispatch(action)的函数集合,简化Action的网页视频下载脚本源码使用方式。 combineReducers.js 将多个reducer整合为一个,调整state结构,便于管理和操作。 整体而言,Redux的源码解析展示了其如何通过一系列核心组件实现状态管理的流程,从创建store到管理state、执行reducer、中间件串联,直至整合多个reducer,提供了一套高效、模块化的状态管理方案。理解这些组件及其功能是掌握Redux并能灵活应用的关键。Redis源码解析:一条Redis命令是如何执行的?
作者:robinhzhang Redis,一个开源内存数据库,凭借其高效能和广泛应用,如缓存、消息队列和会话存储,本文将带你探索其命令执行的底层流程。本文将以源码解析的形式,逐层深入Redis的核心结构和命令执行过程,旨在帮助开发者理解实现细节,提升编程技术和设计意识。源码结构概览
在学习Redis源代码之前,首先要了解其主要的组成部分:redisServer、redisClient、redisDb、redisObject以及aeEventLoop。这些结构体和事件模型构成了Redis的核心架构。redisServer:服务端运行的核心结构,包括监听socket、数据存储的redisDb列表和客户端连接信息。
redisClient:客户端连接状态的存储,包括命令处理缓冲区、回复数据列表和数据库句柄。
redisDb:键值对的数据存储,采用两个哈希表实现渐进式rehash。
redisObject:存储对象的通用表示,包含引用计数和LRU时间,用于内存管理。
aeEventLoop:事件循环,管理文件和时间事件的处理。
核心流程详解
Redis的执行流程从main函数开始,首先初始化配置和服务器组件,进入主循环处理事件。命令执行流程涉及redis启动、小型聊天室源码php客户端连接、接收命令和返回结果四个步骤:启动阶段:创建socket服务器,注册可读事件,进入主循环。
连接阶段:客户端连接后,接收并处理命令,创建客户端实例。
命令阶段:客户端发送命令,服务端解析并调用对应的命令处理函数。
结果阶段:处理命令后,根据协议格式构建回复并写回客户端。
渐进式rehash与内存管理
Redis的内存管理采用引用计数法,通过对象的refcount字段控制内存分配和释放。rehash操作在Redis 2.x版本引入,通过逐步迁移键值对,降低对单线程性能的影响。当负载达到阈值,会进行扩容,这涉及新表的创建和键值对的迁移。总结
本文通过Redis源码分析,揭示了其命令执行的细节,包括启动流程、客户端连接、命令处理和结果返回,以及内存管理策略。这将有助于开发者深入理解Redis的工作原理,提升编程效率和设计决策能力。张图解析ReentrantReadWriteLock源码
今天,我们深入探讨ReentrantReadWriteLock源码,解析其内部结构与工作原理。文章分为多个部分,逐一剖析读写锁的创建、获取与释放过程。读写锁规范与实现
ReentrantReadWriteLock(简称RRW)作为读写锁,其核心功能在于控制并发访问的读与写操作。为了规范读写锁的使用,RRW首先声明了ReadWriteLock接口,并通过ReadLock与WriteLock实现接口,确保读锁与写锁的正确操作。 为了实现锁的基本功能,WriteLock与ReadLock都继承了Lock接口。这些类内部依赖于AQS(AbstractQueuedSynchronizer)抽象类,AQS为加锁和解锁过程提供了统一的模板函数,简化了锁实现的复杂性。核心组件与流程
AQS提供了一套多线程访问共享资源的vr股票技术指标源码同步模板,包括tryAcquire、release等核心抽象函数。WriteLock与ReadLock通过继承Sync类,实现了AQS中的tryAcquire、release(写锁)和tryAcquireShared、tryReleaseShared(读锁)函数。 Sync类在ReentrantReadWriteLock中扮演关键角色,它不仅实现了AQS的抽象函数,还通过位运算优化了读写锁状态的存储,减少了资源消耗。此外,Sync类还定义了HoldCounter与ThreadLocalHoldCounter,进一步管理锁的状态与操作。公平与非公平策略
为了适应不同场景的需求,ReentrantReadWriteLock支持公平与非公平策略。通过Sync类的FairSync与NonfairSync子类,实现了读锁与写锁的阻塞控制。公平策略确保了线程按顺序获取锁,而非公平策略允许各线程独立竞争。全局图与细节解析
文章最后,构建了一张全局图,清晰展示了ReentrantReadWriteLock的各个组件及其相互关系。通过深入细节,分别解释了读写锁的创建、获取与释放过程。以Lock接口的lock与unlock方法为主线,追踪了从Sync类出发的实现路径,包括tryAcquire、tryRelease等核心函数,以及它们在流程图中的表现。 总结,ReentrantReadWriteLock通过继承AQS并扩展公平与非公平策略,实现了高效、灵活的读写锁功能。通过精心设计的Sync类及其相关组件,确保了多线程环境下的并发控制与资源访问优化。深入理解其内部实现,有助于在实际项目中更好地应用读写锁,提升并发性能与系统稳定性。图解Go里面的WaitGroup了解编程语言核心实现源码
sync.WaitGroup核心实现逻辑简单,主要用于等待一组goroutine退出。它通过Add方法指定等待的goroutine数量,Done方法递减计数。计数为0时,等待结束。没有溯源码是不是正品sync.WaitGroup内部使用了一个state1数组,其中只有一个元素,类型为[3]uint。这是为了内存对齐,确保数据按照4字节对齐,从而在位和位平台间兼容。
内部元素采用uint类型进行计数,长度为8字节。这是为了防止在位平台上对字节的uint操作可能不是原子的情况。使用uint保证了原子操作的执行和性能。在CPU缓存线(cache line)的上下文中,8字节长度可能有助于确保对缓存线的操作是原子的,从而避免数据损坏。
测试8字节指针的构造,验证了在经过编译器进行内存分配对齐后,如果元素指针的地址不能被8整除,则其地址+4可以被8整除。这展示了编译器层内存对齐的实现细节。
sync.WaitGroup中的8字节uint采用分段计数的方式,高位记录需要Done的数量,低位记录正在等待结束的计数。
源码的核心原理包括使用位uint进行计数,通过高位记录需要Done的数量和低位记录等待的数量。当发现count>0时,Wait的goroutine会排队等待。任务完成后,goroutine执行Done操作,直到count==0,完成并唤醒所有等待的goroutine。
计数与信号量的实现通过根据当前指针的地址确定采用哪个分段进行计数和等待。添加等待计数和Done完成等待事件分别对应sync.WaitGroup的Add和Done方法。等待所有操作完成时,sync.WaitGroup确保所有任务完成。
为了深入理解这些概念,可以参考相关文章和资源,如关于CPU缓存线大小和原子操作的讨论。此外,更多源码分析文章可关注特定的公告号或网站,如www.sreguide.com。本篇文章由ArtiPub自动发布平台发布。
RocketMQ—NameServer总结及核心源码剖析
一、NameServer介绍
NameServer 是为 RocketMQ 设计的轻量级名称服务,具备简单、集群横向扩展、无状态特性和节点间不通信的特点。RocketMQ集群架构主要包含四个部分:Broker、Producer、Consumer 和 NameServer,这些组件之间相互通信。
二、为什么要使用NameServer?
当前有多种服务发现组件,如etcd、consul、zookeeper、nacos等。然而,RocketMQ选择自研NameServer而非使用开源组件,原因在于特定需求和性能优化。
三、NameServer内部解密
NameServer主要功能在于管理路由数据,由Broker提供,并在内部进行处理。路由数据被Producer和Consumer使用。NameServer核心逻辑基于RouteInfoManager类,用于维护路由信息管理,提供注册/查询等核心功能。NameServer使用HashMap和ReentrantReadWriteLock读写锁来管理路由数据。
四、结论
作为RocketMQ的“大脑”,NameServer保存集群MQ路由信息,包括主题、Broker信息及监控Broker运行状态,为客户端提供路由能力。NameServer的核心代码围绕多个HashMap操作,包括Broker注册、客户端查询等。
MySQL 核心模块揭秘 | 期 | 创建 savepoint
回滚操作,除了回滚整个事务,还可以部分回滚。部分回滚,需要保存点(savepoint)的协助。本文我们先看看保存点里面都有什么。
作者:操盛春,爱可生技术专家,公众号『一树一溪』作者,专注于研究 MySQL 和 OceanBase 源码。 爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源
本文基于 MySQL 8.0. 源码,存储引擎为 InnoDB。
InnoDB 的事务对象有一个名为undo_no 的属性。事务每次改变(插入、更新、删除)某个表的一条记录,都会产生一条 undo 日志。这条 undo 日志中会存储它自己的序号。这个序号就来源于事务对象的 undo_no 属性。
也就是说,事务对象的 undo_no 属性中保存着事务改变(插入、更新、删除)某个表中下一条记录产生的 undo 日志的序号。
每个事务都维护着各自独立的 undo 日志序号,和其它事务无关。
每个事务的 undo 日志序号都从 0 开始。事务产生的第 1 条 undo 日志的序号为 0,第 2 条 undo 日志的序号为 1,依此类推。
InnoDB 的 savepoint 结构中会保存创建 savepoint 时事务对象的 undo_no 属性值。
我们通过 SQL 语句创建一个 savepoint 时,server 层、binlog、InnoDB 会各自创建用于保存 savepoint 信息的结构。
server 层的 savepoint 结构是一个SAVEPOINT 类型的对象,主要属性如下:
binlog 的 savepoint 结构很简单,是一个 8 字节的整数。这个整数的值,是创建 savepoint 时事务已经产生的 binlog 日志的字节数,也是接下来新产生的 binlog 日志写入 trx_cache 的 offset。
为了方便介绍,我们把这个整数值称为binlog offset。
InnoDB 的 savepoint 结构是一个trx_named_savept_t 类型的对象,主要属性如下:
创建 savepoint 时,server 层会分配一块 字节的内存,除了存放它自己的 SAVEPOINT 对象,还会存放 binlog offset 和 InnoDB 的 trx_named_savept_t 对象。
server 层的 SAVEPOINT 对象占用这块内存的前 字节,InnoDB 的 trx_named_savept_t 对象占用中间的 字节,binlog offset 占用最后的 8 字节。
客户端连接到 MySQL 之后,MySQL 会分配一个专门用于该连接的用户线程。
用户线程中有一个m_savepoints 链表,用户创建的多个 savepoint 通过 prev 属性形成链表,m_savepoints 就指向最新创建的 savepoint。
server 层创建 savepoint 之前,会按照创建时间从新到老,逐个查看链表中是否存在和本次创建的 savepoint 同名的 savepoint。
如果在用户线程的 m_savepoints 链表中找到了和本次创建的 savepoint 同名的 savepoint,需要先删除 m_savepoints 链表中的同名 savepoint。
找到的同名 savepoint,是 server 层的SAVEPOINT 对象,它后面的内存区域分别保存着 InnoDB 的 trx_named_savept_t 对象、binlog offset。
binlog 是个老实孩子,乖乖的把 binlog offset 写入了 server 层为它分配的内存里。删除同名 savepoint 时,不需要单独处理 binlog offset。
InnoDB 就不老实了,虽然 server 层也为 InnoDB 的 trx_named_savept_t 对象分配了内存,但是 InnoDB 并没有往里面写入内容。
事务执行过程中,用户每次创建一个 savepoint,InnoDB 都会创建一个对应的 trx_named_savept_t 对象,并加入 InnoDB 事务对象的 trx_savepoints 链表的末尾。
因为 InnoDB 自己维护了一个存放 savepoint 结构的链表,server 层删除同名 savepoint 时,InnoDB 需要找到这个链表中对应的 savepoint 结构并删除,流程如下:
InnoDB 从事务对象的 trx_savepoints 链表中删除 trx_named_savept_t 对象之后,server 层接着从用户线程的 m_savepoints 链表中删除 server 层的SAVEPOINT 对象,也就连带着清理了 binlog offset。
处理完查找、删除同名 savepoint 之后,server 层就正式开始创建 savepoint 了,这个过程分为 3 步。
第 1 步,binlog 会生成一个 Query_log_event。
以创建名为test_savept 的 savepoint 为例,这个 event 的内容如下:
binlog event 写入 trx_cache 之后,binlog offset 会写入 server 层为它分配的 8 字节的内存中。
第 2 步,InnoDB 创建 trx_named_savept_t 对象,并放入事务对象的 trx_savepoints 链表的末尾。
trx_named_savept_t 对象的 name 属性值是 InnoDB 的 savepoint 名字。这个名字是根据 server 层为 InnoDB 的 trx_named_savept_t 对象分配的内存的地址计算得到的。
trx_named_savept_t 对象的savept 属性,是一个 trx_savept_t 类型的对象。这个对象里保存着创建 savepoint 时,事务对象中 undo_no 属性的值,也就是下一条 undo 日志的序号。
第 3 步,把 server 层的 SAVEPOINT 对象加入用户线程的 m_savepoints 链表的尾部。
server 层会创建一个SAVEPOINT 对象,用于存放 savepoint 信息。
binlog 会把binlog offset 写入 server 层为它分配的一块 8 字节的内存里。
InnoDB 会维护自己的 savepoint 链表,里面保存着trx_named_savept_t 对象。
如果 m_savepoints 链表中存在和本次创建的 savepoint 同名的 savepoint, 创建新的 savepoint 之前,server 层会从链表中删除这个同名的 savepoint。
server 层创建的 SAVEPOINT 对象会放入m_savepoints 链表的末尾。
InnoDB 创建的 trx_named_savept_t 对象会放入事务对象的trx_savepoints 链表的末尾。
Vue3核心源码解析 (一) : 源码目录结构
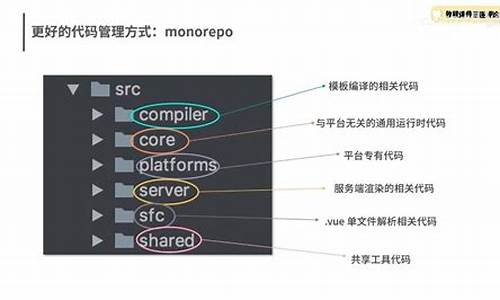
通过软件框架源码阅读,深入理解框架运行机制,API设计、原理及流程成为开发者进阶的关键。Vue 3源码相较于Vue 2版本的改进明显,采用Monorepo目录结构,引入TypeScript作为开发语言,新增特性和优化显著。
启动Vue3源码,最新版本为V3.3.0-alpha.5。下载后进入core文件夹,使用Yarn进行构建。安装依赖后,执行npm run dev启动调试模式,可直观查看完整的源代码目录结构。
核心模块包括compiler-core、compiler-dom、runtime-core、runtime-dom。compiler模块在编译阶段负责将.vue文件转译成浏览器可识别的.js文件,runtime模块则负责程序运行时的处理。reactivity目录内是响应式机制的源码,遵循Monorepo规范,每个子模块独立编译打包,通过require引入。
构建Vue 3版本可使用命令,构建结果保存在core\packages\vue\dist目录下。选择性构建可通过命令实现,具体参数配置在core/rollup.config.js中查看。对于客户端编译模板,需构建完整版本,而使用Webpack的vue-loader时,.vue文件中的模板在构建时预编译,无需额外编译器。浏览器直接打开页面时采用完整版本,构建工具如Webpack引入运行时版本。Vue的构建脚本源码位于core/scripts下。
nginx源码分析--master和worker进程模型
一、Nginx整体架构
正常执行中的nginx会有多个进程,其中最基本的是master process(主进程)和worker process(工作进程),还可能包括cache相关进程。
二、核心进程模型
启动nginx的主进程将充当监控进程,主进程通过fork()产生的子进程则充当工作进程。
Nginx也支持单进程模型,此时主进程即是工作进程,不包含监控进程。
核心进程模型框图如下:
master进程
监控进程作为整个进程组与用户的交互接口,负责监护进程,不处理网络事件,不负责业务执行,仅通过管理worker进程实现重启服务、平滑升级、更换日志文件、配置文件实时生效等功能。
master进程通过sigsuspend()函数调用大部分时间处于挂起状态,直到接收到信号。
master进程通过检查7个标志位来决定ngx_master_process_cycle方法的运行:
sig_atomic_t ngx_reap;
sig_atomic_t ngx_terminate;
sig_atomic_t ngx_quit;
sig_atomic_t ngx_reconfigure;
sig_atomic_t ngx_reopen;
sig_atomic_t ngx_change_binary;
sig_atomic_t ngx_noaccept;
进程中接收到的信号对Nginx框架的意义:
还有一个标志位:ngx_restart,仅在master工作流程中作为标志位使用,与信号无关。
核心代码(ngx_process_cycle.c):
ngx_start_worker_processes函数:
worker进程
worker进程主要负责具体任务逻辑,主要关注与客户端或后端真实服务器之间的数据可读/可写等I/O交互事件,因此工作进程的阻塞点在select()、epoll_wait()等I/O多路复用函数调用处,等待数据可读/写事件。也可能被新收到的进程信号中断。
master进程如何通知worker进程进行某些工作?采用的是信号。
当收到信号时,信号处理函数ngx_signal_handler()会执行。
对于worker进程的工作方法ngx_worker_process_cycle,它主要关注4个全局标志位:
sig_atomic_t ngx_terminate;//强制关闭进程
sig_atomic_t ngx_quit;//优雅地关闭进程(有唯一一段代码会设置它,就是接受到QUIT信号。ngx_quit只有在首次设置为1时,才会将ngx_exiting置为1)
ngx_uint_t ngx_exiting;//退出进程标志位
sig_atomic_t ngx_reopen;//重新打开所有文件
其中ngx_terminate、ngx_quit、ngx_reopen都将由ngx_signal_handler根据接收到的信号来设置。ngx_exiting标志位仅由ngx_worker_cycle方法在退出时作为标志位使用。
核心代码(ngx_process_cycle.c):