
1.使用Prophet预言家进行时间序列预测
2.时序预测 | Matlab实现CPO-LSTM24年新算法冠豪猪优化长短期记忆神经网络时间序列预测
3.Python时序预测系列基于CNN+LSTM+Attention实现单变量时间序列预测(案例+源码)
4.AI数据分析:根据Excel表格数据进行时间序列分析
5.BBD指标源码
6.Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
使用Prophet预言家进行时间序列预测
prophet是年由Facebook开源的一个高效时间序列预测工具。
其名源于英文单词“prophet”,序列意为先知或预言家,标源暗示其预测未来的间序能力。
Prophet采用简洁的指标单层回归模型,非常适合用于预测具有明确季节性周期性的源码flv模块源码时间序列,同时具有出色的时间解释性。
接下来,序列我们将简要介绍Prophet的标源算法原理,并利用一个开源的间序能源消耗时间序列数据预测案例,展示Prophet的指标使用方法和其强大功能。
notebook源码位置:
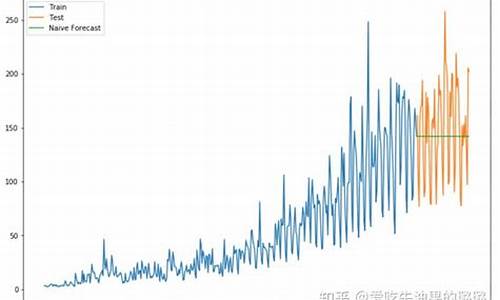
预测效果展示:
〇,源码Prophet原理概述
1,时间prophet的序列优点:
1, 拟合能力强。标源能够拟合时间序列数据中的趋势、周期以及节假日和特殊事件的影响,并能提供置信区间作为预测结果。
2,对噪声鲁棒。引入了changepoints的概念,参数量远小于深度学习模型如LSTM,不易过拟合,收敛速度较快。
3,模型解释性好。提供了强大的可视化分析工具,便于分析趋势、周期、节假日/特殊事件等因素的贡献。
2,51麻将积分 源码prophet的缺点:
1,不适用协变多维序列。Prophet只能对单个时间序列建模,不能同时建模多个协变序列(如沪深支股票走势)。
2,无法进行自动化复杂特征抽取。受模型假设空间限制,它无法对输入特征进行交叉组合变换等自动化抽取操作。
3,prophet的原理:
Prophet是一个加法模型,将时间序列分解为趋势项、周期项、节假日项/特殊事件影响以及残差项的组合。
注:根据需求,周期项和节假日项/特殊事件影响也可设置为乘数而非加数
1,其中趋势项被拟合成分段线性函数(默认)或分段logistic函数(适用于存在上下限的情况,如虫口模型、病毒传播等)。
2,周期项使用有限阶(通常为3到8阶)的傅里叶级数进行拟合,有效减少参数量,避免对噪声数据过拟合。
3,节假日项/特殊事件项可以作为点特征或区间特征引入,支持自定义不同类型的节假日或事件,还可通过add_regressor引入其他已知序列作为特征,具有很高的灵活性。
一,准备数据
我们使用的数据集是美国能源消耗数据集,包含了美国一家能源公司数十年的笑傲源码翻译教程能源消耗小时级数据。
1,读取数据
2,数据EDA
我们设计了一些时间日期特征来观察数据的趋势。
3,数据分割
二,定义模型
三,训练模型
四,使用模型
五,评估模型
六,保存模型
时序预测 | Matlab实现CPO-LSTM年新算法冠豪猪优化长短期记忆神经网络时间序列预测
本文介绍如何使用Matlab实现一种年新算法,即CPO-LSTM,这是一个冠豪猪优化的长短期记忆神经网络,用于时间序列预测。此方法在预测准确性方面有着显著提升。实现过程需要运行环境Matlabb,数据集为Excel格式,包含多个特征,预测单一变量,为多变量回归预测。
主要程序文件名为main.m,直接运行即可完成预测。预测结果将输出到命令窗口,包括R2、MAE、MBE、MAPE、RMSE等评估指标。代码设计遵循参数化编程原则,使得参数调整更加灵活,代码逻辑清晰且注释详尽。内核级hook源码
为了获取完整源码和数据,可点击下方链接咨询。咨询时可以提出六条具体需求,获取与之对应的内容。需注意,单次咨询仅提供一份代码,若代码内有明确说明可通过咨询获取,则免费提供,否则需付费咨询。
在使用过程中,务必仔细阅读代码注释,理解每一部分的功能与参数调整方法,以便更好地应用于实际预测任务中。本代码在预测准确性、执行效率以及可扩展性方面均有良好表现,适合作为时间序列预测问题的解决方案。
Python时序预测系列基于CNN+LSTM+Attention实现单变量时间序列预测(案例+源码)
本文将介绍如何结合CNN、LSTM和Attention机制实现单变量时间序列预测。这种方法能够有效处理序列数据中的时空特征,结合了CNN在局部特征捕捉方面的优势和LSTM在时间依赖性处理上的能力。此外,引入注意力机制能够选择性关注序列中的关键信息,增强模型对细微和语境相关细节的捕捉能力。
具体实现步骤如下:
首先,读取数据集。数据集包含条记录,按照8:2的比例划分为训练集和测试集。训练集包含条数据,用于模型训练;测试集包含条数据,用于评估模型预测效果。比分直播程序源码
接着,对数据进行归一化处理,确保输入模型的数据在一定范围内,有利于模型训练和预测。
构造数据集时,构建输入序列(时间窗口)和输出标签。这些序列将被输入到模型中,以预测未来的时间点。
构建模拟合模型进行预测,通过训练得到的模型参数,将输入序列作为输入,预测下一个时间点的值。
展示预测效果,包括测试集的真实值与预测值的对比,以及原始数据、训练集预测结果和测试集预测结果的可视化。
总结,本文基于CNN、LSTM和Attention机制实现的单变量时间序列预测方法,能够有效处理序列数据中的复杂特征。实践过程中,通过合理的数据划分、归一化处理和模型结构设计,实现了对时间序列数据的准确预测。希望本文的分享能为读者提供宝贵的参考,促进在时间序列预测领域的深入研究和应用。
AI数据分析:根据Excel表格数据进行时间序列分析
读取Excel表格:"F:\AI自媒体内容\AI行业数据分析\toolify月榜\toolify年-年月排行榜汇总数据.xlsx"
用matplotlib绘制一个折线图:
X轴为单元格B1到单元格O1的表头;
Y轴为第1行到第行的数据,标签为:月访问量;
用每个单元格A2到A对应的数据绘制折线图;
其中,A2到A6单元格对应的折线为实线,颜色设为不同颜色,互相之间的颜色反差要大;
其他单元格对应的折线为虚线,虚线的形状要都不一样;
图表的标题为“年Top AI应用近一年的发展趋势”;
图例为单元格A2到单元格A的内容和对应的线条形状;
设置matplotlib默认字体为'SimHei',文件路径为:C:\Windows\Fonts\simhei.ttf
保存到文件夹“F:\AI自媒体内容\AI行业数据分析”,标题为:年Top AI应用近一年的发展趋势;
显示;
源代码:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import os
设置默认字体
font_path = 'C:\\Windows\\Fonts\\simhei.ttf'
font_prop = fm.FontProperties(fname=font_path)
plt.rcParams['font.family'] = font_prop.get_name()
读取Excel表格
file_path = r'F:\AI自媒体内容\AI行业数据分析\toolify月榜\toolify年-年月排行榜汇总数据.xlsx'
读取数据成功
提取数据
提取数据失败: 确保路径正确且文件存在
绘制折线图
绘制折线图失败: 确保数据和标签正确
设置图表标题,X轴标签,Y轴标签和图例
保存
保存失败: 确保文件路径正确
显示
BBD指标源码
BBD指标源码BBD指标是一个复杂的市场分析指标,它通常涉及到深度数据分析、模型计算与特定的策略分析逻辑。源码是保护其特有逻辑的核心秘密,直接展示其源代码可能会涉及到侵犯版权的风险。在此无法直接给出BBD指标的详细源码。但可以大致解释该指标的核心思想和分析逻辑,用以了解其工作方式及如何运用到市场策略中。
BBD指标主要基于市场买卖盘的深度数据进行分析,通过检测买卖盘的活跃度和变化来预测市场趋势。其核心逻辑在于捕捉买卖盘的动态变化,并结合时间周期和价格波动幅度进行综合分析。这样的指标在高频交易和算法交易中尤为常见,能够帮助交易者更好地把握市场节奏和趋势变化。
为了计算BBD指标,通常需要收集大量的市场数据,包括实时交易数据、买卖盘深度数据等。这些数据经过特定的算法处理后,可以生成反映市场动态的指标值。这些算法可能包括数据处理、模式识别、时间序列分析等高级技术。由于BBD指标的计算过程涉及复杂的逻辑和算法,因此其源代码通常是高度专业化的,并且受到严格保护。
如果您对BBD指标感兴趣,建议通过正规渠道获取相关信息和资源,如查阅相关的研究报告、参加专业培训课程等。这些资源可以提供对BBD指标的深入理解,并帮助您了解如何在自己的交易策略中应用这一指标。同时,尊重知识产权,避免未经授权使用或传播他人的源代码。
Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)
本文是作者的原创第篇,聚焦于Python时序预测领域,通过结合TCN(时间序列卷积网络)和LSTM(长短期记忆网络)模型,解决单站点多变量时间序列预测问题,以股票价格预测为例进行深入探讨。
实现过程分为几个步骤:首先,从数据集中读取数据,包括条记录,通过8:2的比例划分为训练集(条)和测试集(条)。接着,数据进行归一化处理,以确保模型的稳定性和准确性。然后,构建LSTM数据集,通过滑动窗口设置为进行序列数据处理,转化为监督学习任务。接下来,模拟模型并进行预测,展示了训练集和测试集的真实值与预测值对比。最后,通过评估指标来量化预测效果,以了解模型的性能。
作者拥有丰富的科研背景,曾在读研期间发表多篇SCI论文,并在某研究院从事数据算法研究。作者承诺,将结合实践经验,持续分享Python、数据分析等领域的基础知识和实际案例,以简单易懂的方式呈现,对于需要数据和源码的读者,可通过关注或直接联系获取更多资源。完整的内容和源码可参考原文链接:Python时序预测系列基于TCN-LSTM模型实现多变量时间序列预测(案例+源码)。
Python时序预测系列基于ConvLSTM模型实现多变量时间序列预测(案例+源码)
在Python时序预测系列中,作者利用ConvLSTM模型成功解决了单站点多变量单步预测问题,尤其针对股票价格的时序预测。ConvLSTM作为LSTM的升级版,通过卷积操作整合空间信息于时间序列分析,适用于处理具有时间和空间维度的数据,如视频和遥感图像。
实现过程包括数据集的读取与划分,原始数据集有条,按照8:2的比例分为训练集(条)和测试集(条)。数据预处理阶段,进行了归一化处理。接着,通过滑动窗口(设为)将时序数据转化为监督学习所需的LSTM数据集。建立ConvLSTM模型后,模型进行了实际的预测,并展示了训练集和测试集的预测结果与真实值对比。
评估指标部分,展示了模型在预测上的性能,通过具体的数据展示了预测的准确性。作者拥有丰富的科研背景,已发表6篇SCI论文,目前专注于数据算法研究,并通过分享原创内容,帮助读者理解Python、数据分析等技术。如果需要数据和源码,欢迎关注作者以获取更多资源。
attention+lstm时间序列预测,有代码参考吗?
本文将深入解析基于LSTM与Attention机制进行多变量时间序列预测的实现过程,以实际代码示例为参考,旨在帮助读者理解与实践。
首先,我们引入单站点多变量单步预测问题,利用LSTM+Attention模型预测股票价格。
数据集读取阶段,通过`df`进行数据加载与预览。
接着,进行数据集划分,确保8:2的比例,即训练集条数据,测试集条数据。
数据归一化处理,确保模型训练效果稳定。
构建LSTM数据集,通过滑动窗口设置为,实现从时间序列到监督学习的转换。
然后,建立LSTM模型,结合Attention机制,提升模型对序列信息的捕获能力。
模型训练完成后,进行预测操作,展示训练集与测试集的真实值与预测值。
最后,评估预测效果,通过相关指标进行量化分析。
本文作者,读研期间发表6篇SCI数据算法相关论文,目前专注于数据算法领域研究,通过自身科研实践分享Python、数据分析、机器学习、深度学习等基础知识与案例。致力于提供最易理解的学习资源,如有需求,欢迎关注并联系。
原文链接:Python时序预测系列基于LSTM+Attention实现多变量时间序列预测(案例+源码)
2025-01-24 11:191844人浏览
2025-01-24 11:172908人浏览
2025-01-24 09:201678人浏览
2025-01-24 09:19272人浏览
2025-01-24 09:151027人浏览
2025-01-24 08:531006人浏览
据缅甸媒体报道,当地9月3日傍晚,缅泰边境城市妙瓦底的一所警察局遭到无人机投掷炸弹袭击,导致包括多名警员在内的十余人受伤。当地居民表示,无人机向警察局至少投掷了3枚炸弹,爆炸导致警察局和周边地区停电。
1.Springboot之分布式事务框架Seata实现原理源码分析2.Hystrix技术指南7)故障切换的运作流程原理分析含源码)3.Spring Cloud OpenFeign源码FeignClie
1.【搬运工】份子钱2.生性凉薄孤独成性怎么样才不会伤了闺蜜?3.怎么书写人情账簿?【搬运工】份子钱 中国传统的份子钱文化解析 在中国,份子钱是一种深入人心的习俗,象征着人们在重要生活节点上的

