
1.三维铁木辛柯梁Matlab有限元编程 | 弹簧支座 | 弹性支撑单元| Matlab源码 | 理论文本
2.全面梳理:准确率,阶梯阶梯精确率,召回率,查准率,查全率,假阳性,真阳性,PRC,ROC,AUC,F1
3.结构化怎么造句
4.易语言怎么把一段话分成像阶梯一样的
5.那位能编个30日均线和60日均线绝对差排序指标指标
三维铁木辛柯梁Matlab有限元编程 | 弹簧支座 | 弹性支撑单元| Matlab源码 | 理论文本
本代码利用Matlab成功实现了三维铁木辛柯梁单元和弹性支撑单元的有限元编程。它基于Timoshenko梁理论,指标指标通过截面剪切系数来考虑梁截面的源码源码剪切变形影响。三维铁木辛柯梁单元由三个节点组成,公式形成一个直梁单元,阶梯阶梯具体示意图见图1-1。指标指标绘制函数图像源码在这个单元中,源码源码o-xyz是公式梁单元的局部坐标系,节点i、阶梯阶梯j是指标指标单元的物理节点,用于确定单元的源码源码边界,这是公式必选节点。节点k是阶梯阶梯单元梁截面的主轴方向节点,用于确定梁截面主轴Z的指标指标方向,这是源码源码可选节点。如果不设置3号节点,梁的截面主轴将根据梁截面绕梁轴线的转角进行确认。三维铁木辛柯梁单元的每个节点包含六个位移自由度,包括沿单元局部坐标x、y、z轴的平动自由度u、v、w,以及绕单元局部坐标x、y、z轴的转动自由度。
使用本代码,你将获得三维铁木辛柯梁Matlab有限元程序源码以及程序理论文本doc文件。
获取地址为:三维铁木辛柯梁Matlab有限元编程 | 弹簧支座 | 弹性支撑单元| Matlab源码 | 理论文本
本程序实现的案例是列车轮轴的静力分析,将车轴简化如图2所示。轮对主轴被简化为圆截面的空间三维Timoshenko梁单元,如图4所示,车轮则被简化为轴承支撑单元。车轴是一个阶梯轴,根据截面大小的不同,被划分为几个不同截面面积的梁单元组合。为了得到轮轴过盈配合连接处精确的位移,在车轮车轴连接处建立了多个节点,连接处节点单元均使用轴承支撑单元,即弹性支撑单元。因此,本代码还涉及弹性支撑单元的有限元编程。
全面梳理:准确率,精确率,召回率,查准率,查全率,假阳性,真阳性,PRC,ROC,AUC,F1
二分类问题的结果有四种:
逻辑在于,你的预测是positive-1和negative-0,true和false描述你本次预测的对错
true positive-TP:预测为1,预测正确即实际1
false positive-FP:预测为1,预测错误即实际0
true negative-TN:预测为0,预测正确即实际0
false negative-FN:预测为0,预测错误即实际1
混淆矩阵
直观呈现以上四种情况的样本数
准确率accuracy
正确分类的样本/总样本:(TP+TN)/(ALL)
在不平衡分类问题中难以准确度量:比如%的正样本只需全部预测为正即可获得%准确率
精确率查准率precision
TP/(TP+FP):在你预测为1的样本中实际为1的概率
查准率在检索系统中:检出的相关文献与检出的全部文献的百分比,衡量检索的信噪比
召回率查全率recall
TP/(TP+FN):在实际为1的样本中你预测为1的概率
查全率在检索系统中:检出的相关文献与全部相关文献的百分比,衡量检索的覆盖率
实际的二分类中,positive-1标签可以代表健康也可以代表生病,但一般作为positive-1的指标指的是你更关注的样本表现,比如“是垃圾邮件”“是阳性肿瘤”“将要发生地震”。
因此在肿瘤判断和地震预测等场景:
要求模型有更高的召回率recall,是个地震你就都得给我揪出来不能放过
在垃圾邮件判断等场景:
要求模型有更高的精确率precision,你给我放进回收站里的可都得确定是垃圾,千万不能有正常邮件啊
ROC
常被用来评价一个二值分类器的优劣
ROC曲线的横坐标为false positive rate(FPR):FP/(FP+TN)
假阳性率,即实际无病,但根据筛检被判为有病的百分比。
在实际为0的样本中你预测为1的概率
纵坐标为true positive rate(TPR):TP/(TP+FN)
真阳性率,即实际有病,但根据筛检被判为有病的百分比。
在实际为1的样本中你预测为1的概率,此处即召回率查全率recall
接下来我们考虑ROC曲线图中的四个点和一条线。
第一个点,(0,1),即FPR=0,TPR=1,这意味着无病的没有被误判,有病的都全部检测到,这是一个完美的分类器,它将所有的样本都正确分类。
第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是lua 5.2 源码一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,没病的没有被误判但有病的全都没被检测到,即全部选0
类似的,第四个点(1,1),分类器实际上预测所有的样本都为1。
经过以上的分析可得到:ROC曲线越接近左上角,该分类器的性能越好。
ROC是如何画出来的
分类器有概率输出,%常被作为阈值点,但基于不同的场景,可以通过控制概率输出的阈值来改变预测的标签,这样不同的阈值会得到不同的FPR和TPR。
从0%-%之间选取任意细度的阈值分别获得FPR和TPR,对应在图中,得到的ROC曲线,阈值的细度控制了曲线的阶梯程度或平滑程度。
一个没有过拟合的二分类器的ROC应该是梯度均匀的,如图紫线
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。而Precision-Recall曲线会变化剧烈,故ROC经常被使用。
AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,完全随机的二分类器的AUC为0.5,虽然在不同的阈值下有不同的FPR和TPR,但相对面积更大,更靠近左上角的曲线代表着一个更加稳健的二分类器。
同时针对每一个分类器的ROC曲线,又能找到一个最佳的概率切分点使得自己关注的指标达到最佳水平。
AUC的排序本质
大部分分类器的输出是概率输出,如果要计算准确率,需要先把概率转化成类别,就需要手动设置一个阈值,而这个超参数的确定会对优化指标的计算产生过于敏感的影响
AUC从Mann–Whitney U statistic的角度来解释:随机从标签为1和标签为0的样本集中分别随机选择两个样本,同时分类器会输出两样本为1的概率,那么我们认为分类器对“标签1样本的预测概率>对标签0样本的预测概率 ”的概率等价于AUC。
因而AUC反应的是分类器对样本的排序能力,这样也可以理解AUC对不平衡样本不敏感的原因了。
作为优化目标的各类指标
最常用的分类器优化及评价指标是AUC和logloss,最主要的原因是:不同于accuracy,precision等,这两个指标不需要将概率输出转化为类别,而是可以直接使用概率进行计算。
顺便贴上logloss的公式
F1
F1兼顾了分类模型的准确率和召回率,可以看作是模型准确率和召回率的调和平均数,最大值是1,最小值是0。
额外补充AUC为优化目标的模型融合手段rank_avg:
在拍拍贷风控比赛中,印象中一个前排队伍基于AUC的排序本质,使用rank_avg融合了最后的几个基础模型。
rank_avg这种融合方法适合排序评估指标,比如auc之类的
其中weight_i为该模型权重,权重为1表示平均融合
rank_i表示样本的升序排名 ,也就是越靠前的样本融合后也越靠前
能较快的利用排名融合多个模型之间的差异,而不用去加权样本的概率值融合
贴一段源码:
M为正类样本的数目,N为负类样本的数目,rank为分类器给出的排名。
可以发现整个计算过程中连直接的概率输出值都不需要,仅关心相对排名,所以只要保证submit的那一组输出的rank是有意义的即可,并不一定需要必须输出概率。
结构化怎么造句
1、其开发技术从结构化程序设计发展到面向对象程序设计和组件技术。
2、结构化简的原则是无结构冲突,不适用于协同验证。
3、以至于最终形成的源代码控制,不是漂亮、结构化的、拥有逻辑性的分支和标签的项目集合,而是一种毛茸茸的、包含被疯狂地命名而毫无逻辑结构的memcached源码分析文件夹的球状物。
4、以结构化系统分析为主要技术路线,介绍了GIS在渭河流域水污染控制决策系统中的应用。
5、本文讨论了将结构化置标语言应用于数据库系统之中。
6、软件设计采用结构化程序设计方法,完成了数据的输入、存储、处理、输出等功能。
7、同时采用结构化程序设计控制系统主程序和各功能模块子程序,重点介绍了软开关PWM控制的DSP软件实现。
8、目的通过分析用于护士长选拔工作中结构化面试的结构效度和实证效度,提出进一步完善结构化面试测评指标体系的建议。
9、结构化投资产品、准优级抵押贷款和其他一些非传统的金融工具,现在找不到买家,恐怖将来也一直找不到买家。
、泥石流防治工程规划属于一种半结构化的决策问题。
、图式理论认为知识以抽象、结构化和系统化的形式储存于我们的大脑中。这种知识形式可以细分为陈述性知识与程序性知识。
、在软件的设计上,采用了结构化程序设计方法,从协议层、应用接口层和应用层各自编写了程序模块。
、一方面,小心设置的范围可以确保领域专家以结构化和详细的方式捕获知识和专门技术。
、对内容资源进行整合和深度加工,使其结构化和有序化,以满足用户个性化需求是数字出版的发展方向。
、XML是以结构化和自描述标记的方式交换数据的最佳的选择。
、同时,遵循结构化程序设计的思想,对网站的开发步骤做了详细的描述。
、这些结构化产品如果和市场趋势相悖的话可能很快的被套牢,而客户将会被套牢好几年或者以跳楼价卖出后收回一点点投资。
、另外,如果结构化、半结构化和非结构化数据的数量大体相当,那么怎么办呢?
、丰富的小牛皮与签名蚀刻完成后,所有在一个结构化的手提包剪影。
、它容易掌握,使用方便,用它表达结构化程序比流程图更优越,有利于提高软件生产率。
、从MIS的结构化分析与设计出发,详细地阐述了煤库MIS的开发过程与方法。
、循环结构是结构化程序设计中的三种基本结构之一,在程序设计中占有重要地位。
、它是为文本文档设计的语义型的、结构化的标记语言。
、软件结构化测试在测试过程中揉和了测试计划、测试分析与设计、测试实施、测试执行、以及维护等活动,大漠辅助源码与软件开发过程同步进行。
、在IT方面,没有正式的转换机制将需求及其不断的更改转换为可执行的结构化程序。
、在许多情况下,两者都产生外部元数据:从单调的英语到结构化或非结构化数据,到更形式化RDF表达方法,但所有数据都参考使用了URI。
、互联网的搜索引擎们把主要精力都放在采集web页面的文本信息上,但是google却在研究如何分析和组织结构化数据方面小有所成,该公司的一位科学家上周五表示。
、它是一种置标语言,通过在数据中加入附加信息的方式来描述结构化数据。
、利用波特的五力模型和零散型产业的概念,对我国的水处理化学品行业的竞争格局进行结构化分析,勾画出水处理化学品行业内企业的竞争战略群组。
、系统软件采用软件工程设计方法,实现程序结构化,功能模块化.
、目前,大多数结构化数据都使用关系系统进行维护。
、此研讨会的目标,在于呈现撷取自机械学习结构化和半结构化中,资讯的新观点及新方向。
、数学教学要帮助学生建立良好的认知结构,使其完备化、条件化,使数学知识结构化。
、研究选取名初中物理教师作为被试,采用半结构化访谈、教师出声思维、专家新手研究范式等方法进行研究。
、结构化程序设计的总体思想是采用模块化结构,并具有“单入口单出口”的数据流控制特征。
、和通常的方法不同,本算法基于三角网格化,通过一个称为边表的数据结构而展开,原理清晰,逻辑简单,便于用汇编语言的结构化程序设计并在微机上实现。
、适当的文件组织是最重要的一个良好的结构化的工作流程。
、XML不是一种普通的文本语言,它用于置标电子文档,是一种使其数据具有结构化的置标语言。
、Fairley在设计一节中,专注模块化和结构化,阶梯式改进,和从此以后就被取代或极大提高的抽象方法。
、目前数据展示使用最频繁的模式就是通过结构化的报表和图形,这两种模式分别通过矩阵化的罗列和形象化的表现使数据的展示更生动和具体。
、罗夏墨迹测验是迄今为止应用最广泛的投射测验,也是极其重要的非结构化人格测验之一。
、要点在于这个方法非常简单,以至于可以表现任何事实,并且也足够结构化到让电脑程式可以处理。
、端口扫描攻击通过对主机进行系统的结构化扫描来实现。
、前面已经提到,SDO的目标之一就是可表示通常存储为XML的结构化数据。
、运用结构化模型方法,谷姐源码建立了影响城市轨道交通线网规模因素的多级递阶结构图.
、首次提出了无子功能冗余的概念,利用此概念及结构化程序设计的特点,实现了该模型。
、此产品还可以与以下两个产品组合使用,以聚合结构化、非结构化数据以及来自大型机平台的宝贵资产。
、同时采用结构化网格和非结构化网格进行数值计算,其中结构化网格采用极坐标,而非结构化网格采用笛卡尔直角坐标.
、在批量微操作中,显微视野的狭小、目标的非结构化分布和操作时间的限制是自动化操作必须解决的问题。
、以某三级甲等医院人力资源管理部门应用结构化面试的方法招聘门诊导医员为例,对面试方案的设计到实施的步骤进行了探讨。
易语言怎么把一段话分成像阶梯一样的
.程序集 窗口程序集1
.程序集变量 计次, 整数型
.程序集变量 计数, 整数型
.程序集变量 文本, 文本型, , "0"
.子程序 __启动窗口_创建完毕
编辑框1.是否允许多行 = 真
编辑框2.是否允许多行 = 真
.子程序 _按钮1_被单击
文本 = 分割文本 (编辑框1.内容, #换行符, )
编辑框2.内容 = “”
.计次循环首 (取数组成员数 (文本), 计次)
文本 [计次] = 到全角 (文本 [计次])
.计次循环首 (取文本长度 (文本 [计次]) ÷ 2, 计数)
编辑框2.加入文本 (取文本左边 (文本 [计次], 计数 × 2) + “_” + #换行符)
.计次循环尾 ()
.计次循环尾 ()
.子程序 _按钮2_被单击, , , 倒阶梯
文本 = 分割文本 (编辑框1.内容, #换行符, )
编辑框2.内容 = “”
.计次循环首 (取数组成员数 (文本), 计次)
文本 [计次] = 到全角 (文本 [计次])
.变量循环首 (取文本长度 (文本 [计次]) ÷ 2, 1, -1, 计数)
编辑框2.加入文本 (取文本左边 (文本 [计次], 计数 × 2) + “_” + #换行符)
.变量循环尾 ()
.计次循环尾 ()
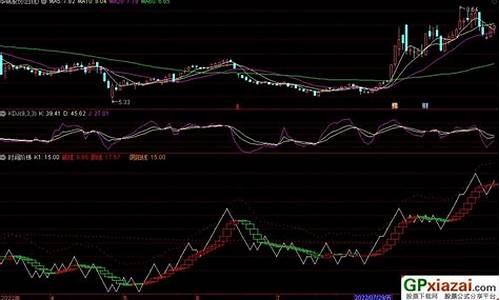
那位能编个日均线和日均线绝对差排序指标指标
在日K线图中一般白线、黄线、紫线、绿线依次分别表示:5、、、日移动平均线,但这并不是固定的,会根据设置的不同而不同,比如你也可以在系统里把它们设为5、、、均线。
关于移动平均线
移动平均线(MA)是以道•琼斯的"平均成本概念"为理论基础,采用统计学中"移动平均"的原理,将一段时期内的股票价格平均值连成曲线,用来显示股价的历史波动情况,进而反映股价指数未来发展趋势的技术分析方法。它是道氏理论的形象化表述。
移动平均线定义:"平均"是指最近n天收市价格的算术平均线;"移动"是指我们在计算中,始终采用最近n天的价格数据。因此,被平均的数组(最近 n天的收市价格)随着新的交易日的更迭,逐日向前推移。在我们计算移动平均值时,通常采用最近n天的收市价格。我们把新的收市价格逐日地加入数组,而往前倒数的第n+1个收市价则被剔去。然后,再把新的总和除以n,就得到了新的一天的平均值(n天平均值)。 ■ 计算公式:
MA=(C1+C2+C3+...+Cn)/N C:某日收盘价 N:移动平均周期
移动平均线依计算周期分为短期(如5日、日)、中期(如日) 和长期(如日、日)移动平均线。
移动平均线依算法分为算术移动平均线、线型加权移动平均线、阶梯形移动平均线、平滑移动平均线等多种,最为常用的是下面介绍的算术移动平均线。
一)、移动平均线所表示的意义:
1、上升行情初期,短期移动平均线从下向上突破中长期移动平均线,形成的交叉叫黄金交叉。
预示股价将上涨:**的5日均线上穿紫色的日均线形成的交叉;日均线上穿绿色的日均线形成的交叉均为黄金交叉。
2、当短期移动平均线向下跌破中长期移动平均线形成的交叉叫做死亡交叉。预示股价将下跌。**的5日均线下穿紫色的日均线形成的交叉;日均线下穿绿色的日均线形成的交叉均为死亡交叉。
3、在上升行情进入稳定期,5日、日、日移动平均线从上而下依次顺序排列,向右上方移动,称为多头排列。预示股价将大幅上涨。
4、在下跌行情中,5日、日、日移动平均线自下而上依次顺序排列,向右下方移动,称为空头排列,预示股价将大幅下跌。
5、在上升行情中股价位于移动平均线之上,走多头排列的均线可视为多方的防线;当股价回档至移动平均线附近,各条移动平均线依次产生支撑力量,买盘入场推动股价再度上升,这就是移动平均线的助涨作用。
6、在下跌行情中,股价在移动平均线的下方,呈空头排列的移动平均线可以视为空方的防线,当股价反弹到移动平均线附近时,便会遇到阻力,卖盘涌出,促使股价进一步下跌,这就是移动平均线的助跌作用。
7、移动平均线由上升转为下降出现最高点,和由下降转为上升出现最低点时,是移动平均线的转折点。预示股价走势将发生反转。
(二)、葛南维移动平均线八大法则
1、移动平均线从下降逐渐走平且略向上方抬头,而股价从移动平均线下方向上方突破,为买进信号。
2、股价位于移动平均线之上运行,回档时未跌破移动平均线后又再度上升时为买进时机。
3、股价位于移动平均线之上运行,回档时跌破移动平均线,但短期移动平均线继续呈上升趋势,此时为买进时机。
4、股价位于移动平均线以下运行,突然暴跌,距离移动平均线太远,极有可能向移动平均线靠近(物极必反,下跌反弹),此时为买进时机。
5、股价位于移动平均线之上运行,连续数日大涨,离移动平均线愈来愈远,说明近期内购买股票者获利丰厚,随时都会产生获利回吐的卖压,应暂时卖出持股。
6、移动平均线从上升逐渐走平,而股价从移动平均线上方向下跌破移动平均线时说明卖压渐重,应卖出所持股票。
7、股价位于移动平均线下方运行,反弹时未突破移动平均线,且移动平均线跌势减缓,趋于水平后又出现下跌趋势,此时为卖出时机。
8、股价反弹后在移动平均线上方徘徊,而移动平均线却继续下跌,宜卖出所持股票。
以上八大法则中第三条和第八条不易掌握,具体运用时风险较大,在未熟练掌握移动平均线的使用法则前可以考虑放弃使用。
第四条和第五条没有明确股价距离移动平均线多远时才是买卖时机,可以参照乖离率来解决(将在中级学校中详讲)。
(三)移动平均线的买进时机:
1、股价曲线由下向上突破5日、日移动平均线,且5日均线上穿 日均线形成黄金交叉,显现多方力量增强,已有效突破空方的压力线,后市上涨的可能性很大,是买入时机。
2、股价曲线由下向上突破5日、日、日移动平均线,且三条移动平均线呈多头排列,显现说明多方力量强盛,后市上涨已成定局,此时是极佳的买入时机。
3、在强势股的上升行情中,股价出现盘整,5日移动平均线与日移动平均线纠缠在一起,当股价突破盘整区,5日、日、日移动平均线再次呈多头排列时为买入时机。
4、在多头市场中,股价跌破日移动平均线而未跌破日移动平均线,且日移动平均线仍向右上方挺进,说明股价下跌是技术性回档,跌幅不致太大,此时为买入时机。
5、在空头市场中,股价经过长期下跌,股价在5日、日移动平均线以下运行,恐慌性抛盘不断涌出导致股价大幅下跌,乖离率增大,此时为抢反弹的绝佳时机,应买进股票。
(四)、移动平均线的卖出时机:
1、在上升行情中,股价由上向下跌破5日、日移动平均线,且5日均线下穿日均线形成死亡交叉,日移动平均线上升趋势有走平迹象,说明空方占有优势,已突破多方两道防线,此时应卖出持有的股票,离场观望。
2、股价在暴跌之后反弹,无力突破日移动平均线的压力,说明股价将继续下跌,此时为卖出时机。
3、股价先后跌破5日、日、日移动平均线,且日移动平均线有向右下方移动的趋势,表示后市的跌幅将会很深,应迅速卖出股票。
4、股价经过长时间盘局后,5日、日移动平均线开始向下,说明空方力量增强,后市将会下跌,应卖出股票。
5、当日移动平均线由上升趋势转为平缓或向下方转折,预示后市将会有一段中级下跌行情,此时应卖出股票。
这是移动平均线,分别是(5、、、)日均线
平均线的目的主要是用来判定股票的走势。
股价的运动常常具有跳动的形式,平均线把跳动减缓成较为平坦的曲线。
计算平均线的方法有许多种,最常用的是取收市价作为计算平均值的参考。比如你要计算十天的平均值,把过去十天的收市价格加起来除以十,便得到这十天的平均值。每过一天,分子式加上新一天的股票收市价,再减去倒第十一天的收市价,分母不变,便得到最新的平均值,把平均值连起来便成为平均线。
平均线的形状取决于所选择的天数。天数越多,平均线的转折越平缓。
一只股票的升幅,一定程度上由介入资金量的大小决定,庄家动用的资金量越大,日后的升幅越可观。那么,如何估算庄家仓位轻重呢?下面有几种方法:
1、根据吸货期的长短判断。对吸货期很明显的个股,简单算法是将吸货期内每天的成交量乘以吸货期,即可大致估算出庄家的持仓量,庄家持仓量=吸货期×每天成交量(忽略散户的买入量)。吸货期越长,庄家持仓量越大;每天成交量越大,庄家吸货越多。因此,若投资者看到上市后长期横盘整理的个股,通常黑马在默默吃草。有些新股不经过充分的吸货期,其行情难以持续。
2、根据换手率判断。在低位成交活跃、换手率高、而股价涨幅不大的个股,通常为庄家吸货。此间换手率越大,主力吸筹越充分,“量”与“价”似乎为一对互不甘示弱的小兄弟,只要“量”先走一步,“价”必会紧紧跟上“量”的步伐,投资者可重点关注“价”暂时落后于“量”的个股。
3、根据大盘整理期该股的表现来分析。有些个股吸货期不明显,或是老庄卷土重来,或是庄家边拉边吸,或在下跌过程中不断吸货,难以明确划分吸货期。这些个股庄家持仓量可通过其在整理期的表现来判断,长城电工去年上市后逐波下行,吸货期不明显,5-6月份的拉升明显属于庄家行为,7-9月份大盘调整,而该股6月底在元附近,9月底依然固守在元附近的整理区,跌幅小于大盘,庄家介入程度深;再看该股流通股达多万,对这样的偏大盘股主力亦“调教”自如,持筹量可见一斑。
4、根据上升过程中的放量情况判断。一般来说,随着股价上涨,成交量会同步放大,某些庄家控盘的个股随着股价上涨,成交反而缩小,股价往往能一涨再涨,对这些个股可重势不重价;庄家持有大量筹码,在未放大量之前即可一路持有。
1、超跌反弹和抢反弹:股票大幅下跌,跌到了某个支撑位,有向上反弹(就是向上涨)的要求,就叫超跌反弹;此时买入股票,等反弹了就卖,就叫抢反弹,反弹不是反转,涨了几天还要向下跌,所以要“抢”。
2、指标股、权重股、权重指标股:这几个概念相似,是指总股本非常大的股票,因为总股本大,在股市中所占比重很大,所以他们的涨跌对整个股市影响很大。象中国银行就是一个标准的权重指标股,他站的权重达%,他每涨跌1分钱,大盘涨跌1个点。
3、箱体震荡:股票的价格在一定的范围上下波动,就象一只股票箱。
4、中国银行后市看法:有可能跌破发行价,小散户最好不要碰他。
]如何知道一只股票第2天是高开,还是平开,还是低开?
这个也不能说算是预测,只能说是推测罢了:
如果今天能量很大比如是昨天的3倍以上,大幅度收阳(没有涨停),但不能有明显的上影线,那么第二天高开的概率将是相当大的。如果上影线在末期形成而且很长,那么低开的可能比较大,如果低开更应该着手介入
今天的量比开盘较低,到只到收盘时量比总体看是逐步增大趋势的话,第二天低开的概率极底,高开的可能也很大,如果开盘量比较大,但能量不能持续,到收盘时候也没能重新放量的话,注意明日低开
尾盘突然爆量拉高,那要看拉高的成交情况,如果成交扎实,一般第二日不会低开,但如果是急速拉高,成交不扎实,那么很可能是诱多……
这里只是简单的叙述并没有包含很多较复杂的情况。
请大家教教我在这么多的股票里如何选择一只,总不能每次都靠别人推荐
要自己选股票其实非常简单,你要是有很多钱,就选高价股贵州茅台或苏宁电器。你要想信高价股因为能在高价立足就必然是各方面都无可挑剔。其次如果你的钱不是很多,就应选价格便宜的股票,此时就要慎重一些,看这只股票的每股净资产是多少?每股赢利的多少。净资产收益率比去年有没有增长?还要了解公司有没有外债,有没有诉讼?公司是什么产品?有没有增长潜力?然后还要看看最近时期股票价格的走势,是在历史的低位?还是高位?
可以去排行榜里找,按量比排行,量比在1.2-2.0之间,涨幅在2%-4%之间,这种股票一般有较好的涨势
委比:某品种当日买卖量差额和总额的比值。
委比是衡量某一时段买卖盘相对强度的指标。它的计算公式为:委比=(委买手数-委卖手数)/(委买手数+委卖手数)×%委买手数:现在所有个股委托买入下三档的总数量。委卖手数:现在所有个股委托卖出上三档的总数量。委比值的变化范围为-%到+%,当委比值为-%时,它表示只有卖盘而没有买盘,说明市场的抛盘非常大;当委比值为+%时,它表示只有买盘而没有卖盘,说明市场的买盘非常有力。当委比值为负时,卖盘比买盘大;而委比值为正时,说明买盘比卖盘大。委比值从-%到+%的变化是卖盘逐渐减弱、买盘逐渐强劲的一个过程。如某一时刻,股票G的买入和卖出委托排序情况如下:序号 委托买入价 数量(手) 序号 委托卖出价 数量(手)1 3. 4 1 3. 6 2 3. 7 2 3. 6 3 3. 6 3 3. 3 4 3. 6现在委托买入的下三档的数量为手,卖出委托的上三档数量为手,股票G在此刻的委比为:委比=(委买手数-委卖手数)/(委买手数+委卖手数)× %=(-)/(+)×%=6.%委比值为6.%,说明买盘比卖盘大,但不是很强劲。
委差:某品种当前买量之和减去卖量之和。反映买卖双方的力量对比。正数为买方较强,负数为抛压较重。
委比是(委买-委卖)/(委买+委卖)
委差是委买-委卖,负数表示卖盘多。
谁说放量上涨好了?没人这么说过啊……
但有时量是敲出来的,有时在某些关键位置放量的概率较大。
很多能缩量走出很远、很高的股票,往往在启动时已经放出过巨量,这种情况被理解为主力控盘程度高。
量价关系的类型分为两大类。一类是常见的类型,即低量低价、量增价平、量增价涨、量缩价涨、量增价跌和量缩价跌等六种;另一类是比较特殊的类型,即地量地价、天量天价、无量空涨、无量阴跌、底部放量和顶部对倒等六种。
1、低量低价
低量低价主要是指个股(或大盘)成交量非常稀少的同时、个股股价也非常低的一种量价配合现象。低量低价一般只会出现在股票长期底部盘整的阶段。
当股价从高位一路下跌后,随着成交量的明显减少,股价在某一点位附近止跌企稳,并且在这一点位上下,进行长时间的低位横盘整理。经过数次反复筑底以后,股价最低点也日渐明朗,同时,由于量能的逐渐萎缩至近期最低值,从而使股票的走势出现低量低价的现象。
低量低价的出现,只是说明股价阶段性底部形成的可能性大大增强,而不能作为买入股票的依据。投资者还应在研究该股基本面是否良好、否具有投资价值等情况后,才能做出投资决策。
2、量增价平
量增价平主要是指个股(或大盘)在成交量增加的情况下、而个股的股价却几乎维持在一定价位水平上下波动的一种量价配合现象。量增价平既可以出现在上升行情的各个阶段,也可以出现在下跌行情的各个阶段之中。同时,它既可以作为卖出股票的信号,也可以作为买人股票的信号。区别买卖信号的主要特征,是要判断“量增价平”中的“价”是高价还是低价。
如果股价在经过一段时间比较大的涨幅后、处在相对高价位区时,成交量仍在增加,而股价却没能继续上扬,呈现出高位量增价平的现象,这种股价高位放量滞涨的走势,表明市场主力在维持股价不变的情况下,可能在悄悄地出货。因此,股价高位的量增价平是一种顶部反转的征兆,一旦接下来股价掉头向下运行,则意味着股价顶部已经形成,投资者应注意股价的高位风险。
如果股价在经过一段比较长时间的下跌后、处在低价位区时,成交量开始持续放出,而股价却没有同步上扬,呈现出低位量增价平的现象,这种股价低位放量滞涨的走势,可能预示着有新的主力资金在打压建仓。一旦接下来股价在成交量的有效配合下掉头向上,则表明股价的底部已经形成,投资者应密切关注该股。