1.安装Open vSwitch(入门级操作)
2.Mellanox ConnectX-6-dx智能网卡 openvswitch 流表卸载源码分析
3.OVS 总体架构、源码结构及数据流程全面解析
4.基于openstack网络模式的vlan分析
安装Open vSwitch(入门级操作)
根据 RFC: OVSDB 管理协议规范,OVSDB 主要管理 OVS 交换机的数据库。OVS 包含 OVSDB-Server、OVS-vSwitchd 和内核模块这三个组件,分别负责配置管理、一米源码流表和转发。
通过 openvswitch.org 官网指导文档,可选择从源代码或包安装 Open vSwitch。本文以源代码安装为例。
首先,下载 Open vSwitch 版本并上传至系统,接着生成 makefile。在解压目录中执行 ./configure,构建 Open vSwitch 用户空间和内核模块。完成构建后,执行 make install 进行安装。
如果构建了内核模块,需要重新编译并安装。加载内核模块至系统后,vb精品源码通过 ovs-ctl 脚本启动 ovsdb-server 和 ovs-vswitchd。ovs-ctl 默认位于 "/usr/local/share/openvswitch/scripts"。
使用 ovs-ctl 启动守护程序,按顺序启动两个进程,ovsdb-server 在启动前会检查数据库是否存在。若无数据库,将创建一个新的空数据库。通过 ovs-ctl 可单独启动或停止守护进程。
配置 ovsdb-server 使用创建的数据库,设置监听 Unix 域套接字,并连接到数据库本身指定的管理器。数据库中使用 SSL 进行配置。确保 ovsdb-server 正常运行后,初始化数据库。
启动主 Open vSwitch 守护进程,连接至相同的 Unix 域套接字。根据上述步骤,正常操作流程为:安装、配置、越狱源码福利启动、验证。
最后,验证 Open vSwitch 安装成功,可以查看版本、添加网桥等操作。
Mellanox ConnectX-6-dx智能网卡 openvswitch 流表卸载源码分析
Mellanox ConnectX-6-dx智能网卡凭借其流表卸载功能,能够无缝融入当前服务器ovs的部署环境。然而,DPU bluefield 2的引入促使ovs需要从服务器迁移至DPU,这无疑对上层neutron架构带来了显著的改造挑战。
在OFED的Linux InfiniBand Drivers版本中,openvswitch采用2..2版本,配合dpdk的.版本,智能网卡的流表卸载主要分为两种途径:netdev_offload_dpdk,通过用户态驱动卸载,和netdev_offload_tc,通过内核态驱动卸载,后者依赖于tc-flow内核模块。txt关机源码
ovs-dpdk的netdev_offload_dpdk采用异步方式,由offload_main线程配合工作队列执行,以避免阻塞包转发线程。在rdma-core中,Mellanox网卡的用户态驱动被集成,因为rdma技术要求用户态操作,以绕过内核TCP/IP协议栈,除非使用iWARP。
相比之下,早期的网卡依赖rdma-core封装的用户态驱动,通过ioctl或netlink接口调用内核驱动进行硬件操作。而netdev_offload_tc则通过tc-flow模块实现内核卸载。
ovs revalidator线程在流程中扮演重要角色,它负责更新卸载流表的统计信息,并在必要时异步删除超时流。对于硬件寄存器中的流表统计,revalidator线程会定时查询,确保信息的实时性。
OVS 总体架构、h 5源码源码结构及数据流程全面解析
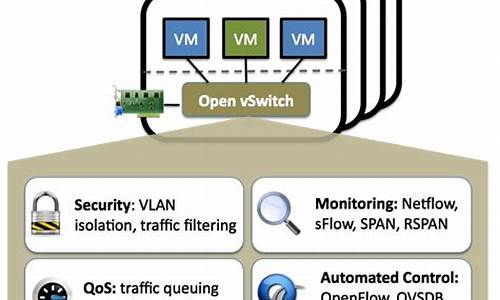
OVS 是一款基于SDN理念的虚拟交换机,它在数据中心的虚拟网络中发挥着关键作用。其核心架构由控制面和数据面组成,控制面通过OpenFlow协议管理交换策略,数据面则负责实际的数据包交换。OVS的整体架构可以细分为管理面、数据面和控制面,每个部分都有特定的功能和工具以提升用户体验。
管理面主要包括OVS提供的各种工具,如ovs-ofctl用于OpenFlow交换机的监控和管理,ovs-dpctl用于配置和管理内核模块的datapath,ovs-vsctl负责ovs-vswitchd的配置和ovsdb-server的数据库操作,ovs-appctl则集合了这些工具的功能。这些工具让用户能方便地控制底层模块。
源码结构方面,OVS的数据交换逻辑由vswitchd和可选的datapath实现,ovsdb存储配置信息,控制面使用OVN,提供兼容性和性能。OVS的分层结构包括vswitchd与ovsdb通信,ofproto处理OpenFlow通信,dpif进行流表操作,以及netdev抽象网络设备并支持不同平台和隧道类型。
数据转发流程中,ovs首先解析数据包信息,然后根据流表决定是否直接转发。若未命中,会将问题上交给用户态的ovs-vswitchd,进一步处理或通过OpenFlow通知控制器。ovs-vswitchd在必要时更新流表后,再将数据包返回给内核态的datapath进行转发。
总的来说,OVS通过其强大的管理工具和精细的架构设计,简化了用户对虚拟网络的操控,确保了高效的数据传输和策略执行。
基于openstack网络模式的vlan分析
OpenStack概念OpenStack是一个美国国家航空航天局和Rackspace合作研发的,以Apache许可证授权,并且是一个自由软件和开放源代码项目。、
OpenStack是一个旨在为公共及私有云的建设与管理提供软件的开源项目。它的社区拥有超过家企业及位开发者,这些机构与个人都将OpenStack作为基础设施即服务(简称IaaS)资源的通用前端。OpenStack项目的首要任务是简化云的部署过程并为其带来良好的可扩展性。本文希望通过提供必要的指导信息,帮助大家利用OpenStack前端来设置及管理自己的公共云或私有云。
openstack neutron中定义了四种网络模式:
# tenant_network_type = local
# tenant_network_type = vlan
# Example: tenant_network_type = gre
# Example: tenant_network_type = vxlan
本文主要以vlan为例,并结合local来详细的分析下openstack的网络模式。
1. local模式
此模式主要用来做测试,只能做单节点的部署(all-in-one),这是因为此网络模式下流量并不能通过真实的物理网卡流出,即neutron的integration bridge并没有与真实的物理网卡做mapping,只能保证同一主机上的vm是连通的,具体参见RDO和neutron的配置文件。
(1)RDO配置文件(answer.conf)
主要看下面红色的配置项,默认为空。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS
openswitch默认的网桥的映射到哪,即br-int映射到哪。 正式由于br-int没有映射到任何bridge或interface,所以只能br-int上的虚拟机之间是连通的。
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_IFACES
流量最后从哪块物理网卡流出配置项
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=local
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=
(2)neutron配置文件(/etc/neutron/plugins/openvswitch/ovs_neutron_plugin.ini)
复制代码
代码如下:
[ovs]
# (StrOpt) Type of network to allocate for tenant networks. The
# default value 'local' is useful only for single-box testing and
# provides no connectivity between hosts. You MUST either change this
# to 'vlan' and configure network_vlan_ranges below or change this to
# 'gre' or 'vxlan' and configure tunnel_id_ranges below in order for
# tenant networks to provide connectivity between hosts. Set to 'none'
# to disable creation of tenant networks.
#
tenant_network_type = local
RDO会根据answer.conf中local的配置将neutron中open vswitch配置文件中配置为local
2. vlan模式
大家对vlan可能比较熟悉,就不再赘述,直接看RDO和neutron的配置文件。
(1)RDO配置文件
复制代码
代码如下:
# Type of network to allocate for tenant networks (eg. vlan, local,
# gre)
CONFIG_NEUTRON_OVS_TENANT_NETWORK_TYPE=vlan //指定网络模式为vlan
# A comma separated list of VLAN ranges for the Neutron openvswitch
# plugin (eg. physnet1:1:,physnet2,physnet3::)
CONFIG_NEUTRON_OVS_VLAN_RANGES=physnet1:: //设置vlan ID value为~
# A comma separated list of bridge mappings for the Neutron
# openvswitch plugin (eg. physnet1:br-eth1,physnet2:br-eth2,physnet3
# :br-eth3)
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1(会自动创建phy-br-eth1和int-br-eth1来连接br-int和br-eth1)
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge.
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=br-eth1:eth1 //设置eth0桥接到br-eth1上,即最后的网络流量从eth1流出 (会自动执行ovs-vsctl add br-eth1 eth1)
此配置描述的网桥与网桥之间,网桥与网卡之间的映射和连接关系具体可结合 《图1 vlan模式下计算节点的网络设备拓扑结构图》和 《图2 vlan模式下网络节点的网络设备拓扑结构图 》来理解。
思考:很多同学可能会碰到一场景:物理机只有一块网卡,或有两块网卡但只有一块网卡连接有网线
此时,可以做如下配置
(2)单网卡:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth0 //设置将br-int映射到桥br-eth
复制代码
代码如下:
# A comma separated list of colon-separated OVS bridge:interface
# pairs. The interface will be added to the associated bridge
CONFIG_NEUTRON_OVS_BRIDGE_IFACES= //配置为空
这个配置的含义是将br-int映射到br-eth0,但是br-eth0并没有与真正的物理网卡绑定,这就需要你事先在所有的计算节点(或网络节点)上事先创建好br-eth0桥,并将eth0添加到br-eth0上,然后在br-eth0上配置好ip,那么RDO在安装的时候,只要建立好br-int与br-eth0之间的连接,整个网络就通了。
此时如果网络节点也是单网卡的话,可能就不能使用float ip的功能了。
(3)双网卡,单网线
复制代码
代码如下:
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=physnet1:br-eth1 //设置将br-int映射到桥br-eth1
/pp# A comma separated list of colon-separated OVS bridge:interface
/pp# pairs. The interface will be added to the associated bridge.
/ppCONFIG_NEUTRON_OVS_BRIDGE_IFACES=eth1 //配置为空
还是默认都配置到eth1上,然后通过iptables将eth1的流量forward到eth0(没有试验过,不确定是否可行)
3. vlan网络模式详解
图1 vlan模式下计算节点的网络设备拓扑结构图
首先来分析下vlan网络模式下,计算节点上虚拟网络设备的拓扑结构。
(1)qbrXXX 等设备
前面已经讲过,主要是因为不能再tap设备vnet0上配置network ACL rules而增加的
(2)qvbXXX/qvoXXX等设备
这是一对veth pair devices,用来连接bridge device和switch,从名字猜测下:q-quantum, v-veth, b-bridge, o-open vswitch(quantum年代的遗留)。
(3) int-br-eth1和phy-br-eth1
这也是一对veth pair devices,用来连接br-int和br-eth1, 另外,vlan ID的转化也是在这执行的,比如从int-br-eth1进来的packets,其vlan id=会被转化成1,同理,从phy-br-eth1出去的packets,其vlan id会从1转化成
(4)br-eth1和eth1
packets要想进入physical network最后还得到真正的物理网卡eth1,所以add eth1 to br-eth1上,整个链路才完全打通
图2 vlan模式下网络节点的网络设备拓扑结构图
网络节点与计算节点相比,就是多了external network,L3 agent和dhcp agent。
(1)network namespace
每个L3 router对应一个private network,但是怎么保证每个private的ip address可以overlapping而又不相互影响呢,这就利用了linux kernel的network namespace
(2)qr-YYY和qg-VVV等设备 (q-quantum, r-router, g-gateway)
qr-YYY获得了一个internal的ip,qg-VVV是一个external的ip,通过iptables rules进行NAT映射。
思考:phy-br-ex和int-br-ex是干啥的?
坚持"所有packets必须经过物理的线路才能通"的思想,虽然 qr-YYY和qg-VVV之间建立的NAT的映射,归根到底还得通过一条物理链路,那么phy-br-ex和int-br-ex就建立了这条物理链路。