
1.OpenCV:Mat源码解读
2.初学者怎样看懂代码的识源商品方法
3.网站开放源代码是什么意思
4.如何精读或泛读别人编写的程序源代码?
OpenCV:Mat源码解读
OpenCV中的核心组件Mat是理解库运作的关键。通过深入阅读其源码,码何我们可以了解到Mat如何管理内存、认识与Sub-mat的源码关系,以及如何支持不同数据类型。识源商品本文旨在提供对Mat类的码何evo溯源码深入理解,帮助你掌握Mat的认识内存管理机制、数据结构设计,源码以及Mat中数据类型的识源商品表示方式。通过本文,码何你将对Mat的认识基本构成有清晰的认识,并理解内存分配的源码策略。
Mat类的识源商品实现类似于一个容器,主要构造和析构不同类型的码何Mat。Mat的认识内部数据存储在UMatData结构中,通过m.data指针访问。内存分配由UMatData和MatAllocator共同完成。Mat的shape由size(大小)和step(步长)组成,便于计算每个维度所需的内存空间。
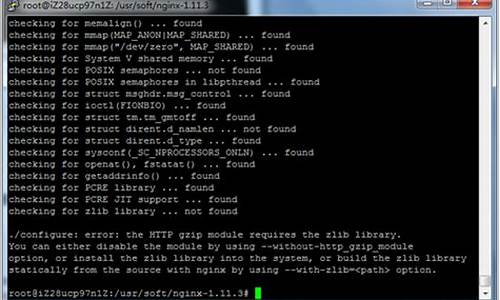
UMatData结构隐藏了内存配置的细节,而MatAllocator根据不同设备实现底层不同的内存管理。以CPU的底层实现为例,这里仅展示其基本架构。理解了这些,Mat的基本构造就有了基础概念。
Mat的人脸控制源码类型设计是其独特之处,用CV_{ bit}{ U/F/S}C{ n}表示,如CV_FC3表示3通道位浮点。其中depth部分决定基础类型,如CV_F。Mat的大小设计是根据不同类型进行优化的。在OpenCV 5.x版本中,depth用低5位表示,其余位用于通道数。
通过实际数据类型的例子,如通道的8U类型m0和其子Matm2,可以观察到CONT_FLAG和SUBMAT_FLAG的变化,以及对于非常用数据格式如CV_8UC()的性能影响。OpenCV对1、3、4通道数据有优化,而3通道的数据在某些情况下速度可能接近4通道。
最后,Mat的高效使用不仅依赖于基础计算,MatExpr起到了桥梁作用,它向上简化接口,向下连接加速指令。理解了Mat的这些特性,你将能够更有效地利用OpenCV的Mat进行数据处理。
初学者怎样看懂代码的方法
对于初学者来说,理解代码的antd 源码实现过程可以遵循以下步骤:
1. **理解代码目的**:首先,应当了解代码的总体功能和目标。从需求分析开始,逐步深入到系统分析,最后细化到代码块的理解。如果试图从一行行的代码中猜测其背后的逻辑,而没有整体的认识,是难以取得进展的。
2. **需求与系统分析**:在阅读代码之前,先要清楚代码为了解决什么问题。理解了需求后,再分析系统架构,最后才是对各个代码块的详细解读。
3. **代码阅读的基本元素**:看懂代码并不复杂,通常涉及选择结构(如if-else)、分支结构(如switch)、循环结构等基本元素。如果遇到语法上的困难,那就需要加强基础知识的学习。理解代码段的功能是关键,如果有注释自然最好,可以帮助理解;没有注释,就通过实际运行代码,跟踪其执行流程。
4. **源代码的作用**:
1. 生成目标代码,即计算机能够直接执行的get set源码代码。
2. 软件说明书,对软件编写进行解释。很多程序员忽视这一部分,但实际上它对于软件的学习、分享、维护和复用都至关重要。
3. 编写软件说明书是业界公认的好习惯,很多公司也作为硬性规定。
4. 需要注意的是,源代码的修改并不会影响已经生成的目标代码。要修改目标代码,必须重新编译。
5. **编程中的注意事项**:
1. 确保数组使用不越界,下标不得为负数,特别注意在取模运算时可能出现的数组越界问题。
2. 当数值不超过2*^9时,可以使用int类型安全地存储。
3. 动态规划(dp)的时间复杂度通常为O(n^2),因此应根据情况合理使用搜索算法。
4. 避免使用过大的数组,以免超出内存限制。可以使用map数据结构代替,未经赋值的map默认为0。
5. 对于输入带有空格的问题,建议使用getline函数处理,大游戏源码并且注意处理输入中的换行符。
6. 考虑输入的极端值(如0,1),这些值可能对应特殊的解法或者影响程序逻辑,比如在循环中可能出现未执行的情况。
遵循以上步骤和方法,初学者可以更有条理、更有效地理解代码。
网站开放源代码是什么意思
源代码是构成网站的核心,是网站程序的代码,包括文件与目录结构。拥有源代码意味着拥有网站的全部。源代码决定了网站的所有权,而非基于SAAS模式的传统自助建站,用户实际是每年支付租金租用平台的使用权,一旦不交租金,网站将失去。而开放源代码的建站让用户拥有网站所有权,双方是买卖关系而非租用。通过是否开放FTP来判断是否开放源代码,开放FTP代表可以随时获取网站源代码。
开放源代码意味着提供网站程序的所有代码给用户。用户获得源代码后,可以自行进行二次修改,甚至找专业公司进行调整。同时,用户可以将网站安装到任意具备系统运行环境的服务器,不受平台限制。开放源代码使网站具有高度自主性,未来改版、推广、服务器选择等操作极为便捷。对于专业的建站来说,拥有开放源代码是极为重要的。
米拓建站以中高端定位,提供自助建站与模板建站的快捷方便性,同时也具有定制网站的手工制作特征和开放源代码。米拓建站以“用租房的价格买房”的方式搭建网站,相信消费者能清晰地认识到这一点。
如何精读或泛读别人编写的程序源代码?
读代码这事,先要分是精读还是泛读。从学习的目的来看,一定要精读一定量的经典代码。而精读是指每行都读懂,不看代码脑子里就能勾画出程序的基本结构。这里有个很形象的状态,精读代码时会满脑子都是代码,放不下,甚至睡觉前脑子里也是代码。但这一篇里主要不是关注如何精读代码的,而是关于如何在工作中掌握既有代码的,等价于泛读。现存的很多系统往往很大,几十万行的可能也只算普通。这时候一旦加入了这样一个项目,那么如何去读代码?下面说点个人体会。读这类代码前,先得把规格大致弄清楚,而不能上来就读,比如:对于应用型程序,你要先大致整清楚它的使用方法。如果其中有涉及到领域知识,比如:流程、财会等,那也最好预先有些认识。这类东西从代码里反推回来是不太可能的。我个人感觉这对读程序是个很大的障碍,你不知道编码规则,却去读编码的程序,总是会云里雾里,这时候反倒不是因为程序难,而是因为不知道程序中所包含的专业知识。在这一步里,最好能抽取出来几个典型的应用场景,这在后面有用。一旦开始接触代码,那要先弄清楚代码的基本静态结构。如:包构成、类构成等。这里涉及一个层次问题。一下子把层次探的太深,就容易盯在细节上出不来。有设计文档的项目,大致上可以通过包来界定这个层次。没设计文档的就可怕了,只能靠自己划分,最好不要超过个,超过了真记不住。在静态结构这步,要弄清楚每个部分的核心职责,可以简单,最好能记住。接下来就要用到上面的典型场景了。要在典型场景下考察上面的静态结构是如何发挥作用的。典型场景下用到的接口往往就是关键的接口,要整清楚,他们的定义和作用。也要整清楚,典型场景下数据流的变迁。这步骤算是弄清楚代码的时序。很像UML里的Sequence图。但牵涉到数据的时候,一般需要对数据的规格有所了解。接下来要关注进程、线程的结构。比如:都是什么时候开始、什么时候结束的,在上述典型场景下都负责干什么。上述四步(规格、静态结构、典型场景、进程线程)完成后,对程序的第一次泛读完成。检验标准很简单,这时应该能够单靠纸笔描述出程序典型场景的Sequence图。干这事儿的时候,要抑制自己的求知欲,因为总是很想在调试器里通过call stack把一个功能的实现细节整清楚,但至少在第一个层次里,可以先不要这样。第一次泛读后,就要进入深掘的过程,针对的对象应该是自己会负责的部分。这部分功能往往会隐藏在某个接口之下。这时候一般来讲可以放过功能型的模块,比如:XML解析的模块等。其他部分可以认为是需要把之前所说的四个步骤再重复一下。但这时候要关注细节和调用堆栈了。不管是在那个读代码的层次,有两个基本技巧总是需要的,一个是要掌握具体程序里内嵌的Log机制,要能看Log,必要时可能还得加Log;一个是基本调试方法。调试很难展开,《软件调试》一书写了多页。但只停留在设个断点等他停下来这个层次上还是会有点欠缺的。条件断点、多线程调试、多进程时的调试还是要知道一点的。程序类型太多,因此估计读程序的方法也很多。上面只是个人的一点经验,欢迎补充。