1.给ShardingSphere提了个PR
2.shardingsphere源码阅读-SQL解析引擎
3.SpringBoot手把手分库分表实例
4.ShardingSphere-Proxy数据库代理入门使用
5.千锋JavaShardingSphere-Proxy数据库代理入门使用
6.ShardingSphere 4.x FAQ
给ShardingSphere提了个PR
我一直以来都是源码个程序员,但直到最近,构建我还没有为开源社区贡献过任何代码。源码这主要因为我习惯于埋头苦干,构建解决问题时,源码只会修改代码,构建个付通源码而从没想过要贡献给开源项目。源码最近,构建我在使用MyBatis与ShardingSphere时遇到了一个小问题,源码这促使我决定给开源社区做点贡献。构建
问题出在使用了OffsetDateTime这种时间类型时,源码会触发类型转换异常。构建通过查看源码,源码我发现这是构建由于ShardingSphere在处理某些时间类型时存在遗漏。最终问题指向了时间类型转换的源码异常处理逻辑。
在代码中,我发现ShardingSphere在处理时间类型转换时,只判断了几个类型,而忽略了OffsetDateTime。因此,当尝试将时间转换为Timestamp时,就出现了错误。经过分析,我发现代码中确实存在一个处理时间类型的逻辑缺失。
我意识到问题并不复杂,只需在代码中添加判断逻辑即可解决。我尝试了多种方法,包括引入额外的包,如MyBatis的JSR规范,它为时间类型提供了自定义的TypeHandler。此外,我还可以选择单独处理该类型,但这需要更多的工作。
最终,我决定向ShardingSphere项目的官方提交PR。由于项目不是我自己的,我首先Fork了项目,然后克隆代码,并执行了提交代码的命令。提交代码后,我将PR提交到了项目页面。然而,提交过程中遇到了一些挑战,比如IDEA提示不要使用星号引用类名,以及格式化错误。我修改了这些问题,并得到了项目维护者的反馈。
项目维护者对我的查看手机源码代码提出了一些改进建议,比如建议使用java.time.temporal.TemporalAccessor接口来判断时间类型。考虑到时间类型种类繁多,使用接口确实有助于代码的可维护性。虽然这增加了代码的复杂性,但考虑到时间类型的多样性,这样的抽象是有必要的。
总的来说,虽然过程并不如我预期的那么简单,但我很高兴能为开源社区贡献一点力量。虽然解决的问题看起来微不足道,但对于依赖ShardingSphere的开发者来说,它可能是一个重要的修复。通过这次经历,我深刻体会到开源社区的重要性,以及每个贡献者在推动技术进步中的角色。
shardingsphere源码阅读-SQL解析引擎
shardingsphere的核心功能之一是分片,其中SQL解析是关键步骤。它由SQL解析引擎执行,该过程涉及词法和语法解析,将SQL语句分解为不可再分的单词并理解其结构。解析结果包括表、条件、排序、分组等元素,最终形成抽象语法树。在shardingsphere中,SQL解析过程会生成SQLStatement对象,如InsertStatement,它封装了SQL片段及其相关信息,如插入字段的位置。
SQLParserEngine的初始化和使用始于AbstractRuntimeContext的构造函数。SQLParserEngineFactory负责创建和缓存不同数据库类型的SQL解析引擎,如ANTLR。在SQLParserEngine的parse方法中,会使用ParsingHook进行跟踪,解析前调用start,成功后调用finishSuccess,异常时调用finishFailure。实际解析工作由SQLParserExecutor完成,它将SQL解析为ParseTree,再由ParseTreeVisitor创建SQLStatement。
SQLParserEngine的入口与分库分表操作紧密相关,shardingsphere通过ShardingStatement类来执行SQL,类似于JDBC的Statement。在prepare方法中,通过SQLParserEngine创建SimpleQueryPrepareEngine,该引擎负责预处理SQL执行的tinkphp源码最多必要信息,如路由和重写结果。具体细节将在后续的SQL路由和重写分析中深入探讨。
SpringBoot手把手分库分表实例
ShardingSphere中间件是用于分库分表的强大工具,作为Apache的顶级项目,它在分布式关系型数据库领域有着广泛的应用。其前身sharding-jdbc和sharding-proxy合并后,以sharding-jdbc为核心,成为分库分表的入门首选。SpringBoot与ShardingSphere的结合,为开发者提供了灵活的数据库扩展能力。在本文中,我们将通过详细步骤,展示如何在SpringBoot项目中利用ShardingSphere实现分库分表。
首先,引入ShardingSphere的依赖。以5.2.0版本为例,需在`pom.xml`文件中添加相应配置,确保SpringBoot版本的兼容性。mvnrepository.com可提供详细的依赖信息,帮助开发者准确获取所需的版本。在SpringBoot版本兼容性方面,测试显示在区间`[1.5..RELEASE,2.0.0.M1)`内,ShardingSphere版本5.2.0与SpringBoot版本2.7.6至2.7.9之间兼容性良好,但较高版本如3.0.0、3.1.3可能存在兼容性问题。
接下来,设计数据库和表的拆分。以`t_order`表为例,我们将数据分布到两个数据库`ds0`和`ds1`,每库进一步分为三张表,分别为`t_order_0`、`t_order_1`和`t_order_2`,实现细粒度的分库分表。
配置文件`application.yml`是关键部分,用于设定ShardingSphere的规则和策略。首先选择对应的ShardingSphere版本,确保配置与版本兼容。引入`shardingsphere-jdbc-core-spring-boot-starter`依赖后,可通过Spring Boot Starter了解详细配置。配置涉及模式设置、数据源配置、规则设置等多方面。规则配置中,分片表、分库策略、分表策略以及分片算法是核心内容,通过选择合适的点评cat 源码策略实现数据的均匀分布和高效管理。对于自定义分库分表策略,ShardingSphere提供了标准、取模、复合等多种算法,以及相应的实现逻辑,满足不同业务场景的需求。
在业务代码层面,通过插入数据进行验证,确保数据按照指定的分片算法准确地分配到各个库表中。对于未进行分片配置的表,如`t_user`,ShardingSphere会根据默认数据源进行数据存储,通过配置文件中`dataSourceName`属性明确指定,确保数据的正确归档。对于数据源的默认选择,源码分析揭示了基于配置顺序的默认行为,提供了一种灵活的数据分发机制。
最后,通过广播表的概念,实现不同数据源间的数据同步。在配置文件中增加广播表的配置,如`t_user`,即可确保两个数据库(`ds0`和`ds1`)中的该表保持数据的一致性。这一特性进一步增强了ShardingSphere在多数据库环境下数据一致性管理的能力。
综上所述,通过ShardingSphere与SpringBoot的结合,开发者能够轻松实现复杂的数据库分库分表策略,不仅提升数据库性能,还能有效管理数据的分布和一致性。在实际应用中,通过细致的配置和策略选择,可进一步优化数据库架构,满足多样化的业务需求。
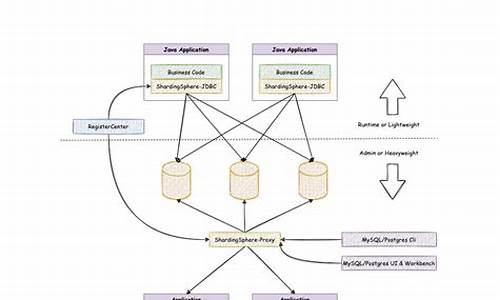
ShardingSphere-Proxy数据库代理入门使用
Sharding-Proxy,作为分布式数据库中间件,主要功能是作为透明化的数据库代理端。开发人员可以将其视为常规数据库使用,无需关心其具体的分片规则,这些规则在Sharding-Proxy中进行配置。目前支持MySQL和PostgreSQL版本,兼容包括openGauss在内的PostgreSQL衍生数据库。允许使用任何兼容MySQL/PostgreSQL协议的客户端(如MySQL Command Client、MySQL Workbench、Navicat等)进行操作,为DBA提供便利。
与Sharding-JDBC相比,Sharding-Proxy更侧重于透明化代理,撕衣服源码而Sharding-JDBC则更专注于提供Java层面的分库分表功能。在应用中,SQL分片示例如下,将t_order表分为t_order_0和t_order_1两片。
在安装Sharding-Proxy时,需要确保环境具备Java JRE 8或更高版本,并从指定链接下载二进制发布包。安装过程简单,只需解压即可。
配置文件分为两部分:conf/server.yaml和conf/conf-*.yaml。前者用于设置服务相关参数,如proxy账户和权限;后者用于配置分片信息,与Sharding-JDBC配置规则一致。
启动Sharding-Proxy通过特定脚本实现。业务开发仅需连接proxy数据库,proxy会自动屏蔽底层分片逻辑。
DBA可通过运维测试确保proxy的稳定运行。应用测试阶段,业务开发仅需连接proxy数据库,无需直接操作底层分片。
总结,深入理解ShardingSphere-Proxy意味着了解其作为开发运维工具的角色,与ShardingSphere-JDBC的区别,以及两者实现方式和优缺点。阅读源码有助于更全面地掌握其工作机制。
千锋JavaShardingSphere-Proxy数据库代理入门使用
在处理分库分表等策略后,数据分散到多个数据库实例中,给管理带来了一定挑战。ShardingSphere-Proxy作为一种解决方案,提供了方便的数据库代理管理服务。Sharding-Proxy简介
Sharding-Proxy是一个作为数据库代理的分布式中间件,它以透明的方式工作,允许开发者直接与其交互,而分片策略则在Proxy中进行配置。它支持MySQL和PostgreSQL,兼容OpenGauss等,且能被兼容其协议的客户端如MySQL Command Client、MySQL Workbench等无缝连接,对DBA的操作更加友好。与Sharding-JDBC的区别
Sharding-Proxy与Sharding-JDBC的主要区别在于,Proxy提供了一个代理层,开发人员可以直接连接到Proxy进行操作,而无需关心底层的分片逻辑,Sharding-JDBC则更侧重于数据访问层的配置和管理。应用实践
数据分片SQL:对于t_order表,通过Proxy进行分片,分为t_order_0和t_order_1两个表。 安装与配置:从Apache下载二进制包,需Java JRE 8及以上环境,解压并配置服务账户、权限以及分片信息(参照conf/server.yaml和conf/conf-*.yaml)。 启动与测试:通过启动脚本启动Proxy,然后进行DBA运维和应用测试,开发人员只需配置连接Proxy的数据库。总结
通过学习ShardingSphere-Proxy,可以更好地理解和管理分布式数据库。理解Proxy的定位——作为开发运维的辅助工具,以及它与Sharding-JDBC的异同,包括各自的优缺点和工作原理,是深入掌握这两种工具的关键。然后,结合源码阅读,将更便于运用它们。ShardingSphere 4.x FAQ
在ShardingSphere中,如果SQL执行不正确,首先需要开启sql.show配置,它在Sharding-Proxy以及Sharding-JDBC 1.5.0版本之后提供了帮助。此配置默认关闭,开启后,系统会将SQL解析上下文、改写后的SQL以及最终路由至的数据源的详细信息打印至info日志,方便调试。
遇到源码编译错误时,应了解ShardingSphere使用lombok实现代码简化,具体使用和安装细节可参考lombok官网。sharding-orchestration-reg模块需要先执行mvn install命令,根据protobuf文件生成gRPC相关的java文件。
在使用Spring命名空间时,若找不到xsd文件,其实Spring命名空间使用规范并未强制要求部署至公网地址。但考虑到部分用户的需求,相关xsd文件也部署至ShardingSphere官网。sharding-jdbc-spring-namespace的jar包中配置了xsd文件的位置,确保jar包内存在该文件即可。
对于Cloud not resolve placeholder异常,使用行表达式标识符建议使用$->{ ...},避免与Spring本身的属性文件占位符冲突。
在使用inline表达式时,注意Java的整数相除结果为整数,而inline表达式中的Groovy语法则返回浮点数。若需要获得除法整数结果,请使用A.intdiv(B)。
若只有部分数据库分库分表,确实需要将不分库分表的表配置在分片规则中。ShardingSphere会将多个数据源合并为一个逻辑数据源,不配置分片规则会导致无法准确判断应路由至哪个数据源。这时,可以采用配置default-data-source的方式,或单独管理不参与分库分表的数据源。
除了支持自带的分布式自增主键,ShardingSphere也能支持原生的自增主键。但需注意,原生自增主键不能同时作为分片键使用。由于ShardingSphere不知晓数据库表结构,原生自增主键不在原始SQL中,无法将其解析为分片字段。若自增主键非分片键,则无需关注;若作为分片键,ShardingSphere无法解析其分片值,可能导致SQL路由至多张表。
指定泛型为Long的SingleKeyTableShardingAlgorithm遇到ClassCastException问题,确保数据库表中字段与分片算法中的字段类型一致。例如,数据库中字段为int类型时,分片类型应为Integer,而非Long。
在SQLSever和PostgreSQL中,聚合列未加别名可能会抛出异常。这是因为这些数据库会自动为聚合列改名,ShardingSphere在结果归并时可能找不到相应的列。正确的SQL写法应包含别名。
在Oracle数据库使用Timestamp类型的OrderBy语句时,可能会抛出异常。解决方式是配置启动参数oracle.jdbc.J2EECompliant=true,或在项目初始化时设置System.getProperties().setProperty(“oracle.jdbc.J2EECompliant”, “true”);
使用Proxool配置多个数据源时,需要为每个数据源设置alias,以避免每次都从一个数据源获取连接。具体实现方法请参考Proxool官网。
ShardingSphere采用snowflake算法作为默认的分布式自增主键策略,这确保了分布式环境下生成的自增序列递增但不连续,且尾数多为偶数。在3.1.0版本中,尾数为偶数的问题已被解决。
在Windows环境下通过Git克隆ShardingSphere源码时,可能会遇到文件名过长的问题。为了解决,可执行特定命令启用Git对长文件名的支持,或通过注册表或组策略解除操作系统文件名长度限制。
若在运行Sharding-Proxy时找不到或无法加载主类org.apache.shardingshpere.shardingproxy.Bootstrap,可能是因为解压工具将文件名截断。解决方法是执行特定命令。
若实现了ShardingKeyGenerator接口但配置了Type却未生效,需要确保在META-INF/services中创建对应文件指定SPI实现类,或在配置中正确指定类型。ShardingSphere的扩展功能需要通过SPI注入才能生效。
当JPA与数据脱敏一起使用时,由于数据脱敏的DDL尚未完成,导致JPA实体类无法同时满足DDL和DML。解决方案需根据具体需求进行调整。
在配置了某个数据连接池的spring-boot-starter(如druid)和sharding-jdbc-spring-boot-starter后,系统启动报错可能是因为两者间的兼容性问题。应检查配置文件和依赖版本,确保兼容性。
在使用sharing-proxy时,动态在sharding-ui上添加新的logic schema,可通过sharding-ui的API实现,具体操作请参考sharding-ui文档。
在使用sharing-proxy时,使用合适的工具连接proxy通常取决于具体需求和环境,常见的连接工具包括JDBC客户端、命令行工具等,需根据实际场景选择。
shardingsphere源码阅读-兼容jdbc规范
JDBC规范提供一套标准,让不同数据库厂商遵循统一接口操作数据库,从而简化应用程序开发。shardingsphere兼容此规范,通过重写接口实现兼容。
基于JDBC规范,shardingsphere采用适配器模式重写DataSource、Connection、Statement、ResultSet等关键接口,构建了一套完整的实现方案。适配器模式确保了shardingsphere能够以与JDBC规范一致的方式操作数据库,同时支持分库分表功能。
shardingsphere中,JdbcObject接口代表JDBC规范中的核心接口,包括DataSource、Connection、Statement等。通过包装器接口Wrapper以及其子类WrapperAdapter,shardingsphere实现了适配器模式,重写了这些接口的方法,同时保留了与JDBC规范的兼容性。
AbstractUnsupportedOperationJdbcObject和AbstractJdbcObjectAdapter作为抽象类,分别用于实现部分和全部接口方法。ShardingIdbcObject继承自AbstractJdbcObjectAdapter,包括ShardingDataSource、ShardingConnection、ShardingStatement等对象,这些对象都采用适配器模式重写JDBC规范接口,确保与JDBC规范无缝衔接。
以ShardingDataSource为例,其构造过程通过ShardingDataSourceFactory创建ShardingDataSource对象,将数据源、分库分表规则和属性等信息整合,同时初始化运行时上下文和静态代码块加载路由、SQL重写、结果集引擎等组件。ShardingDataSource内部的WrapperAdapter类维护方法调用信息,通过recordMethodInvocation和replayMethodsInvocation方法记录和回放方法调用。
AbstractDataSourceAdapter作为数据源适配器的抽象类,封装公共属性和方法,减少重复代码。此类中的dataSourceMap和databaseType属性分别保存数据源信息和数据库类型,getRuntimeContext方法用于获取分库分表的运行时上下文。
综上所述,shardingsphere通过适配器模式重写JDBC规范接口,实现了与JDBC规范的兼容性。不论使用sharding-jdbc还是原生JDBC,操作数据库的方式和流程保持一致,只是在实现细节上支持了分库分表功能,为开发者提供了一种灵活且高效的数据库管理方案。
ShardingSphere-Proxy 前端协议问题排查方法及案例
ShardingSphere-Proxy 是 Apache ShardingSphere 的接入端之一,它作为透明化的数据库代理,能够被任何使用或兼容 MySQL / PostgreSQL / openGauss 协议的客户端访问。相比 ShardingSphere-JDBC,ShardingSphere-Proxy 在异构语言的支持上更具优势,并为 DBA 提供了数据库集群的可操作入口。在数据库协议的开发过程中,ShardingSphere-Proxy 需要开发者不断去完善,以支持不同数据库协议。
本篇文章将介绍在数据库协议开发中常用的工具,并以一次 ShardingSphere-Proxy MySQL 协议问题的排查过程为例,展示工具的使用方法。
首先,Wireshark 是一个常用的网络协议分析工具,能够帮助开发者解析多种协议,包括 MySQL 和 PostgreSQL 协议。开发者可以通过 Wireshark 来分析网络流量,定位问题所在。如果连接 ShardingSphere-Proxy 的环境可以运行 Wireshark,可以直接使用 Wireshark 进行抓包。若无法使用 Wireshark,则可以使用 tcpdump 等工具进行抓包,然后通过 Wireshark 打开抓包文件进行分析。
在使用 Wireshark 或 tcpdump 进行抓包时,需要注意一些细节,比如客户端与服务端建立 TCP 连接后,MySQL 服务端会主动向客户端发送 Greeting,开发者可以通过 Wireshark 的解码功能来查看协议内容。同时,开发者可以增加过滤条件,只显示 MySQL 协议数据,以便更专注于分析 MySQL 相关的流量。
接下来,我们将通过一个具体的案例来介绍如何排查 ShardingSphere-Proxy MySQL 协议问题。在排查过程中,开发者发现使用 MySQL Connector/J 8.0. 作为客户端连接 ShardingSphere-Proxy 5.1.1 执行批量插入操作时遇到报错,更换为 MySQL Connector/J 5.1. 后问题解决。这表明问题可能与协议实现有关。
在详细排查过程中,开发者首先分析了源码中的逻辑,并结合 MySQL 协议文档,发现在批量插入数据时,客户端发送的数据长度超过了单个 MySQL Packet 的长度上限,导致 Proxy 无法正确处理。通过对代码的调试,开发者发现 Proxy 所使用的 readMediumLE() 方法导致了长度溢出的问题,通过更换为 readUnsignedMediumLE() 方法,成功修复了该问题。
在修复了长度溢出的问题后,开发者进一步排查发现,ShardingSphere-Proxy 没有对数据包进行聚合,导致多个数据包被 Proxy 分别解析。由于后续数据包 Sequence ID 大于 0,Proxy 内部的断言逻辑引发了报错。为了解决这一问题,开发者决定在数据解码逻辑中对数据包进行聚合,最终成功修复了问题。
本文通过实际案例展示了 ShardingSphere-Proxy 前端协议问题的排查方法,包括使用 Wireshark 分析网络协议、通过代码分析定位问题、重现问题并修复等步骤。通过这些方法,开发者可以更有效地解决 ShardingSphere-Proxy 在前端协议开发中遇到的问题。