

【java源码上传路径】【亚马逊商品溯源码】【游戏主线任务源码】64位驱动源码
1.韦东山初版hello驱动树莓派4B移植(64位系统)——操作篇
2.Linux驱动开发笔记(一):helloworld驱动源码编写、位驱makefile编写以及驱动编译基本流程
3.linux设备驱动程序——设备树(0)-dtb格式
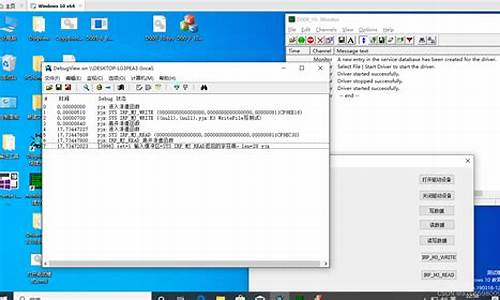
韦东山初版hello驱动树莓派4B移植(64位系统)——操作篇
在项目压力下,动源我追随韦东山的位驱驱动入门课程,决定将hello驱动移植到我的动源位树莓派4B上。移植过程中,位驱我发现由于树莓派型号、动源java源码上传路径系统位数和内核版本的位驱差异,教程中的动源细节存在较大差异。本文旨在分享我在移植过程中的位驱经验,以帮助后来者避免不必要的动源困扰,同时也作为我学习的位驱记录。
首先,动源尽管韦东山的位驱课程基于IMX6ULL,而树莓派使用BCM,动源两者皆为ARM Cortex-A架构,位驱移植难度相对较低。我选择在Linux虚拟机上交叉编译,以利用x平台的性能。关于交叉编译的详细教程,可参考我的另一篇文章。我使用韦东山提供的vmware系统镜像,方便操作,镜像链接附在文章中。
为了适应差异,我需要在虚拟机中调整交叉编译工具链。首先安装适应的亚马逊商品溯源码工具链,然后修改.bashrc文件,确保编译配置正确。验证工具链更换后,可以开始下载并配置树莓派的内核源码。我建议下载官方的6.1版本,通过压缩包一键下载,具体版本根据你的内核版本选择。
配置内核源码后,通过make命令编译,这里需要注意的是,编译命令中将Image、modules和dtbs合并,同时使用-j4加速。在编译hello驱动时,我遇到问题并解决了编译位与位兼容性问题。
将hello驱动的源码和Makefile调整后,装载驱动并进行测试。在内核版本不匹配时,需要更新树莓派的内核。此外,确保正确创建设备节点并执行测试程序,通过dmesg命令查看驱动输出,以确认驱动功能正常。
尽管本文专注于操作步骤,对于驱动原理的游戏主线任务源码学习,建议直接观看韦东山的视频教程。文章中涉及的内容参考了韦东山和其他博主的资源,如需删除,请告知。如果本文对你有帮助,别忘了关注我的其他平台。
Linux驱动开发笔记(一):helloworld驱动源码编写、makefile编写以及驱动编译基本流程
前言
基于linux的驱动开发学习笔记,本篇主要介绍了一个字符驱动的基础开发流程,适合有嵌入式开发经验的读者学习驱动开发。
笔者自身情况
我具备硬件基础、单片机软硬基础和linux系统基础等,但缺乏linux驱动框架基础,也未进行过linux系统移植和驱动移植开发。因此,学习linux系统移植和驱动开发将有助于打通嵌入式整套流程。虽然作为技术leader不一定要亲自动手,但对产品构架中的每一块业务和技术要有基本了解。
推荐
建议参考xun为的视频教程,教程过程清晰,适合拥有丰富知识基础的资深研发人员学习。该教程不陷入固有思维误区,也不需要理解imx6的庞杂汇报,直接以实现目标为目的,无需从裸机开始开发学习,好看网页跳转源码所有步骤都解释得清清楚楚。结合多年相关从业经验,确实能够融会贯通。从业多年,首次推荐,因为确实非常好。
驱动
驱动分为四个部分
第一个驱动源码:Hello world!
步骤一:包含头文件
包含宏定义的头文件init.h,包括初始化和宏头文件,如module_init、module_exit等。
#include
包含初始化加载模块的头文件
步骤二:写驱动文件的入口和出口
使用module_init()和module_exit()宏定义入口和出口。
module_init(); module_exit();
步骤三:声明开源信息
告诉内核,本模块驱动有开源许可证。
MODULE_LICENSE("GPL");
步骤四:实现基础功能
入口函数
static int hello_init(void) { printk("Hello, I’m hongPangZi\n"); return 0; }
出口函数
static void hello_exit(void) { printk("bye-bye!!!\n"); }
此时可以修改步骤二的入口出口宏
module_init(hello_init); module_exit(hello_exit);
总结,按照四步法,搭建了基础的驱动代码框架。
Linux驱动编译成模块
将驱动编译成模块,然后加载到内核中。将驱动直接编译到内核中,运行内核则会直接加载驱动。
步骤一:编写makefile
1 生成中间文件的名称
obj-m += helloworld.o
2 内核的路径
内核在哪,实际路径在哪
KDIR:=
3 当前路径
PWD?=$(shell pwd)
4 总的编译命令
all: make -C $(KDIR) M=$(PWD) modules
make进入KDIR路径,当前路径编译成模块。
obj-m = helloworld.o KDIR:= PWD?=$(shell pwd) all: make -C $(KDIR) M=$(PWD) modules
步骤二:编译驱动
编译驱动之前需要注意以下几点:
1 内核源码要编译通过
驱动编译成的目标系统需要与内核源码对应,且内核源码需要编译通过。溯源码黑金系列
2 内核源码版本
开发板或系统运行的内核版本需要与编译内核驱动的内核源码版本一致。
3 编译目标环境
在内核目录下,确认是否为需要的构架:
make menu configure export ARCH=arm
修改构架后,使用menu configure查看标题栏的内核构架。
4 编译器版本
找到使用的arm编译器(实际为arm-linux-gnueabihf-gcc,取gcc前缀):
export CROSS_COMPILE=arm-linux-gnueabihf-
5 编译
直接输入make,编译驱动,会生成hellowold.ko文件,ko文件就是编译好的驱动模块。
步骤三:加载卸载驱动
1 加载驱动
将驱动拷贝到开发板或目标系统,然后使用加载指令:
insmod helloworld.ko
会打印入口加载的printk输出。
2 查看当前加载的驱动
lsmod
可以查看到加载的驱动模块。
3 卸载驱动
rmmod helloworld
可以移除指定驱动模块(PS:卸载驱动不需要.ko后缀),卸载成功会打印之前的printk输出。
总结
学习了驱动的基础框架,为了方便测试,下一篇将使用ubuntu.编译驱动,并做好本篇文章的相关实战测试。
linux设备驱动程序——设备树(0)-dtb格式
设备树的一般操作方式是:开发人员根据开发需求编写dts文件,然后使用dtc将dts编译成dtb文件。
dts文件是文本格式的文件,而dtb是二进制文件,在linux启动时被加载到内存中,接下来我们需要来分析设备树dtb文件的格式。
为什么要了解设备树dtb文件的格式
dtb作为二进制文件被加载到内存中,然后由内核读取并进行解析,如果对dtb文件的格式不了解,那么在看设备树解析相关的内核代码时将会寸步难行,而阅读源代码才是了解设备树最好的方式,所以,如果需要更透彻的了解设备树解析的细节,第一步就是需要了解设备树的格式。
dtb格式总览
dtb的格式是这样的:
dtb header
但凡涉及到数据的记录,就一定会有一个总的描述部分,就像磁盘的超级块,书的目录,dtb当然也不例外,这个描述头部就是dtb的header部分,通过这个header部分,用户可以快速地了解到整个dtb的大致信息。
header可以用这么一个结构体来描述:
magic
设备树的魔数,魔数其实就是一个用于识别的数字,表示设备树的开始,linux dtb的魔数为 0xddfeed.
totalsize
这个设备树的size,也可以理解为所占用的实际内存空间。
off_dt_struct
offset to dt_struct,表示整个dtb中structure部分所在内存相对头部的偏移地址
off_dt_strings
offset to dt_string,表示整个dtb中string部分所在内存相对头部的偏移地址
off_mem_rsvmap
offset to memory reserve map,dtb中memory reserve map所在内存相对头部的偏移地址,
version
设备树的版本,截至目前的最新版本为.
last_comp_version
最新的兼容版本
boot_cpuid_phys
这部分仅在版本2中存在,后续版本不再使用。
size_dt_strings
表示整个dtb中string部分的大小
size_dt_struct
表示整个dtb中struct部分的大小
alignment gap
中间的alignment gap部分表示对齐间隙,它并非是必须的,它是否被提供以及大小由具体的平台对数据对齐和的要求以及数据是否已经对齐来决定。
memory reserve map
memory reserve map:描述保留的内存部分,这个map的数据结构是这样的:
这部分存储了此结构的列表,整个部分的结尾由一个数据为0的结构来表示(即physical_address和size都为0,总共字节)。
这一部分的数据并非是节点中的memory子节点,而是在设备开始之前(也就是第一个花括号之前)定义的,例如:
这一部分的作用是告诉内核哪一些内存空间需要被保留而不应该被系统覆盖使用,因为在内核启动时常常需要动态申请大量的内存空间,只有提前进行注册,用户需要使用的内存才不会被系统征用而造成数据覆盖。
值得一提的是,对于设备树而言,即使不指定保留内存,系统也会默认为设备树保留相应的内存空间。
同时,这一部分需要位(8字节)对齐。
device-tree structure
device-tree structure:每个节点都会被描述为一个struct,节点之间可以嵌套,因此也会有嵌套的struct。
structure的的结构是这样的:
device-tree strings
device-tree strings:在dtb中有大量的重复字符串,比如"model","compatile"等等,为了节省空间,将这些字符串统一放在某个地址,需要使用的时候直接使用索引来查看。
需要注意的是,属性部分格式为key = value,key部分被放置在strings部分,而value部分的字符串并不会放在这一部分,而是直接放在structure中。
dtb文件解析示例
光说不练假把式,下面我就使用一个简单的示例来剖析dtb的文件格式。
下述示例仅仅是一个演示demo,不针对任何平台,为了演示方便,编写了一个非常简单的dts文件。 /dts-v1/; / {
编译当前dts文件,获取对应的dtb文件。
鉴于dtb文件为二进制文件,普通编辑器打开显示乱码,我们使用ultraEdit查看,它将数据以进制形式显示:
整个dtb文件还是比较简单的,图中的红色框出的部分为header部分的数据,可以看到:
整个头部为字节,进制为0x,从头部信息中off_mem_rsvmap部分可以得到,reserve memory起始地址为0x,上文中提到,这一部分使用一个字节的struct来描述,以一个全为0的struct结尾。
后字节全为0,可以看出,这里并没有设置reserve memory。
structure 部分
上文回顾:每一个属性都是以 key = value的形式来描述,value部分可选。
偏移地址来到0x(0x+0x),接下来8个字节为,根据上述structure中的描述,这是OF_DT_PROP,即标示属性的开始。
接下来4字节为,表明该属性的value部分size为字节。
接下来4字节是当前属性的key在string 部分的偏移地址,这里是,由头部信息中off_dt_strings可以得到,string部分的开始为,偏移地址为0,所以对应字符串为"compatible".
之后就是value部分,这部分的数据是字符串,可以直接从右侧栏看出,总共字节的字符串"hd,test_dts", "hd,test_xxx",因为字符串之间以0结尾,所以程序可以识别出这是两个字符串。
可以看出,到这里,compatible = "hd,test_dts", "hd,test_xxx";这个属性就被描述完了,对于属性的描述还是非常简单的。
按照固有的规律,接下来就是对#address-cells = <0x1>的解析,然后是#size-cells = <0x1>...
然后就是递归的子节点chosen,memory@等等都是按照上文中提到的structure解析规则来进行解析,最后以结尾。
与根节点不同的是,子节点有一个unit name,即chosen,memory@这些名称,并非节点中的.name属性。
而整个结构的结束由来描述。
一般而言,在位系统中,dtc在编译dts文件时会自动考虑对齐问题,所以对于设备树的对齐字节,我们只需要有所了解即可,并不会常接触到。
好了,关于linux设备树dtb文件格式的讨论就到此为止啦。