1.å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
2.Idea 开发Mapreduce遇到的问题,代码不能自动实现方法!搞了很久没搞出来,哪位大牛知道这个?
3.Hadoop开源实现
4.mapreduceåhadoopçå
³ç³»
5.å¦ä½å¨Hadoopä¸ç¼åMapReduceç¨åº
6.hadoop的核心配置文件有哪些
å¦ä½ä½¿ç¨Python为Hadoopç¼åä¸ä¸ªç®åçMapReduceç¨åº
æ们å°ç¼åä¸ä¸ªç®åç MapReduce ç¨åºï¼ä½¿ç¨çæ¯C-Pythonï¼èä¸æ¯Jythonç¼ååæå æjarå çç¨åºã
ããæ们çè¿ä¸ªä¾åå°æ¨¡ä»¿ WordCount 并使ç¨Pythonæ¥å®ç°ï¼ä¾åéè¿è¯»åææ¬æ件æ¥ç»è®¡åºåè¯çåºç°æ¬¡æ°ãç»æä¹ä»¥ææ¬å½¢å¼è¾åºï¼æ¯ä¸è¡å å«ä¸ä¸ªåè¯ååè¯åºç°ç次æ°ï¼ä¸¤è ä¸é´ä½¿ç¨å¶è¡¨ç¬¦æ¥æ³é´éã
ããå å³æ¡ä»¶
ããç¼åè¿ä¸ªç¨åºä¹åï¼ä½ å¦è¦æ¶è®¾å¥½Hadoop é群ï¼è¿æ ·æè½ä¸ä¼å¨åæå·¥ä½æçãå¦æä½ æ²¡ææ¶è®¾å¥½ï¼é£ä¹å¨åé¢æ个ç®ææç¨æ¥æä½ å¨Ubuntu Linux ä¸æ建ï¼åæ ·éç¨äºå ¶ä»åè¡çlinuxãunixï¼
ããå¦ä½ä½¿ç¨Hadoop Distributed File System (HDFS)å¨Ubuntu Linux 建ç«åèç¹ç Hadoop é群
ããå¦ä½ä½¿ç¨Hadoop Distributed File System (HDFS)å¨Ubuntu Linux 建ç«å¤èç¹ç Hadoop é群
ããPythonçMapReduce代ç
ãã使ç¨Pythonç¼åMapReduce代ç çæ巧就å¨äºæ们使ç¨äº HadoopStreaming æ¥å¸®å©æ们å¨Map å Reduceé´ä¼ éæ°æ®éè¿STDIN (æ åè¾å ¥)åSTDOUT (æ åè¾åº).æä»¬ä» ä» ä½¿ç¨Pythonçsys.stdinæ¥è¾å ¥æ°æ®ï¼ä½¿ç¨sys.stdoutè¾åºæ°æ®ï¼è¿æ ·åæ¯å 为HadoopStreamingä¼å¸®æ们åå¥½å ¶ä»äºãè¿æ¯ççï¼å«ä¸ç¸ä¿¡ï¼
ããMap: mapper.py
ããå°ä¸åç代ç ä¿åå¨/home/hadoop/mapper.pyä¸ï¼ä»å°ä»STDIN读åæ°æ®å¹¶å°åè¯æè¡åéå¼ï¼çæä¸ä¸ªå表æ å°åè¯ä¸åç次æ°çå ³ç³»ï¼
ãã注æï¼è¦ç¡®ä¿è¿ä¸ªèæ¬æ足å¤æéï¼chmod +x /home/hadoop/mapper.pyï¼ã
ãã#!/usr/bin/env python
ãã
ããimport sys
ãã
ãã# input comes from STDIN (standard input)
ããfor line in sys.stdin:
ãã# remove leading and trailing whitespace
ããline = line.strip()
ãã# split the line into words
ããwords = line.split()
ãã# increase counters
ããfor word in words:
ãã# write the results to STDOUT (standard output);
ãã# what we output here will be the input for the
ãã# Reduce step, i.e. the input for reducer.py
ãã#
ãã# tab-delimited; the trivial word count is 1
ããprint '%s\\t%s' % (word, 1)å¨è¿ä¸ªèæ¬ä¸ï¼å¹¶ä¸è®¡ç®åºåè¯åºç°çæ»æ°ï¼å®å°è¾åº "<word> 1" è¿ éå°ï¼å°½ç®¡<word>å¯è½ä¼å¨è¾å ¥ä¸åºç°å¤æ¬¡ï¼è®¡ç®æ¯çç»åæ¥çReduceæ¥éª¤ï¼æå«åç¨åºï¼æ¥å®ç°ãå½ç¶ä½ å¯ä»¥æ¹åä¸ç¼ç é£æ ¼ï¼å®å ¨å°éä½ çä¹ æ¯ã
ããReduce: reducer.py
ããå°ä»£ç åå¨å¨/home/hadoop/reducer.py ä¸ï¼è¿ä¸ªèæ¬çä½ç¨æ¯ä»mapper.py çSTDINä¸è¯»åç»æï¼ç¶å计ç®æ¯ä¸ªåè¯åºç°æ¬¡æ°çæ»åï¼å¹¶è¾åºç»æå°STDOUTã
ããåæ ·ï¼è¦æ³¨æèæ¬æéï¼chmod +x /home/hadoop/reducer.py
ãã#!/usr/bin/env python
ãã
ããfrom operator import itemgetter
ããimport sys
ãã
ãã# maps words to their counts
ããword2count = { }
ãã
ãã# input comes from STDIN
ããfor line in sys.stdin:
ãã# remove leading and trailing whitespace
ããline = line.strip()
ãã
ãã# parse the input we got from mapper.py
ããword, count = line.split('\\t', 1)
ãã# convert count (currently a string) to int
ããtry:
ããcount = int(count)
ããword2count[word] = word2count.get(word, 0) + count
ããexcept ValueError:
ãã# count was not a number, so silently
ãã# ignore/discard this line
ããpass
ãã
ãã# sort the words lexigraphically;
ãã#
ãã# this step is NOT required, we just do it so that our
ãã# final output will look more like the official Hadoop
ãã# word count examples
ããsorted_word2count = sorted(word2count.items(), key=itemgetter(0))
ãã
ãã# write the results to STDOUT (standard output)
ããfor word, count in sorted_word2count:
ããprint '%s\\t%s'% (word, count)
ããæµè¯ä½ ç代ç ï¼cat data | map | sort | reduceï¼
ããæå»ºè®®ä½ å¨è¿è¡MapReduce jobæµè¯åå°è¯æå·¥æµè¯ä½ çmapper.py å reducer.pyèæ¬ï¼ä»¥å å¾ä¸å°ä»»ä½è¿åç»æ
ããè¿éæä¸äºå»ºè®®ï¼å ³äºå¦ä½æµè¯ä½ çMapåReduceçåè½ï¼
ããââââââââââââââââââââââââââââââââââââââââââââââ
ãã\r\n
ãã# very basic test
ããhadoop@ubuntu:~$ echo "foo foo quux labs foo bar quux" | /home/hadoop/mapper.py
ããfoo 1
ããfoo 1
ããquux 1
ããlabs 1
ããfoo 1
ããbar 1
ããââââââââââââââââââââââââââââââââââââââââââââââ
ããhadoop@ubuntu:~$ echo "foo foo quux labs foo bar quux" | /home/hadoop/mapper.py | sort | /home/hadoop/reducer.py
ããbar 1
ããfoo 3
ããlabs 1
ããââââââââââââââââââââââââââââââââââââââââââââââ
ãã# using one of the ebooks as example input
ãã# (see below on where to get the ebooks)
ããhadoop@ubuntu:~$ cat /tmp/gutenberg/-8.txt | /home/hadoop/mapper.py
ããThe 1
ããProject 1
ããGutenberg 1
ããEBook 1
ããof 1
ãã[...]
ãã(you get the idea)
ããquux 2
ããquux 1
ããââââââââââââââââââââââââââââââââââââââââââââââ
ããå¨Hadoopå¹³å°ä¸è¿è¡Pythonèæ¬
ãã为äºè¿ä¸ªä¾åï¼æ们å°éè¦ä¸ç§çµå书ï¼
ããThe Outline of Science, Vol. 1 (of 4) by J. Arthur Thomson\r\n
ããThe Notebooks of Leonardo Da Vinci\r\n
ããUlysses by James Joyce
ããä¸è½½ä»ä»¬ï¼å¹¶ä½¿ç¨us-asciiç¼ç åå¨ è§£ååçæ件ï¼ä¿åå¨ä¸´æ¶ç®å½ï¼æ¯å¦/tmp/gutenberg.
ããhadoop@ubuntu:~$ ls -l /tmp/gutenberg/
ããtotal
ãã-rw-r--r-- 1 hadoop hadoop -- : -8.txt
ãã-rw-r--r-- 1 hadoop hadoop -- : 7ldvc.txt
ãã-rw-r--r-- 1 hadoop hadoop -- : ulyss.txt
ããhadoop@ubuntu:~$
ããå¤å¶æ¬å°æ°æ®å°HDFS
ããå¨æ们è¿è¡MapReduce job åï¼æ们éè¦å°æ¬å°çæ件å¤å¶å°HDFSä¸ï¼
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -copyFromLocal /tmp/gutenberg gutenberg
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls
ããFound 1 items
ãã/user/hadoop/gutenberg <dir>
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop dfs -ls gutenberg
ããFound 3 items
ãã/user/hadoop/gutenberg/-8.txt <r 1>
ãã/user/hadoop/gutenberg/7ldvc.txt <r 1>
ãã/user/hadoop/gutenberg/ulyss.txt <r 1>
ããæ§è¡ MapReduce job
ããç°å¨ï¼ä¸ååå¤å°±ç»ªï¼æ们å°å¨è¿è¡Python MapReduce job å¨Hadoopé群ä¸ãåæä¸é¢æ说çï¼æ们使ç¨çæ¯
ããHadoopStreaming 帮å©æä»¬ä¼ éæ°æ®å¨MapåReduceé´å¹¶éè¿STDINåSTDOUTï¼è¿è¡æ ååè¾å ¥è¾åºã
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-0..1-streaming.jar
ãã-mapper /home/hadoop/mapper.py -reducer /home/hadoop/reducer.py -input gutenberg/
*ãã-output gutenberg-output
ããå¨è¿è¡ä¸ï¼å¦æä½ æ³æ´æ¹Hadoopçä¸äºè®¾ç½®ï¼å¦å¢å Reduceä»»å¡çæ°éï¼ä½ å¯ä»¥ä½¿ç¨â-jobconfâé项ï¼
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-0..1-streaming.jar
ãã-jobconf mapred.reduce.tasks= -mapper ...
ããä¸ä¸ªéè¦çå¤å¿æ¯å ³äºHadoop does not honor mapred.map.tasks
ããè¿ä¸ªä»»å¡å°ä¼è¯»åHDFSç®å½ä¸çgutenberg并å¤çä»ä»¬ï¼å°ç»æåå¨å¨ç¬ç«çç»ææ件ä¸ï¼å¹¶åå¨å¨HDFSç®å½ä¸ç
ããgutenberg-outputç®å½ã
ããä¹åæ§è¡çç»æå¦ä¸ï¼
ããhadoop@ubuntu:/usr/local/hadoop$ bin/hadoop jar contrib/streaming/hadoop-0..1-streaming.jar
ãã-mapper /home/hadoop/mapper.py -reducer /home/hadoop/reducer.py -input gutenberg/
*ãã-output gutenberg-output
ãã
ããadditionalConfSpec_:null
ããnull=@@@userJobConfProps_.get(stream.shipped.hadoopstreaming
ããpackageJobJar: [/usr/local/hadoop-datastore/hadoop-hadoop/hadoop-unjar/]
ãã[] /tmp/streamjob.jar tmpDir=null
ãã[...] INFO mapred.FileInputFormat: Total input paths to process : 7
ãã[...] INFO streaming.StreamJob: getLocalDirs(): [/usr/local/hadoop-datastore/hadoop-hadoop/mapred/local]
ãã[...] INFO streaming.StreamJob: Running job: job__
ãã[...]
ãã[...] INFO streaming.StreamJob: map 0% reduce 0%
ãã[...] INFO streaming.StreamJob: map % reduce 0%
ãã[...] INFO streaming.StreamJob: map % reduce 0%
ãã[...] INFO streaming.StreamJob: map % reduce 0%
ãã[...] INFO streaming.StreamJob: map % reduce %
ãã[...] INFO streaming.StreamJob: map % reduce %
ãã[...] INFO streaming.StreamJob: map % reduce %
ãã[...] INFO streaming.StreamJob: map % reduce %
ãã[...] INFO streaming.StreamJob: Job complete: job__
ãã[...] INFO streaming.StreamJob: Output: gutenberg-output hadoop@ubuntu:/usr/local/hadoop$
ããæ£å¦ä½ æè§å°çä¸é¢çè¾åºç»æï¼Hadoop åæ¶è¿æä¾äºä¸ä¸ªåºæ¬çWEBæ¥å£æ¾ç¤ºç»è®¡ç»æåä¿¡æ¯ã
Idea 开发Mapreduce遇到的问题,代码不能自动实现方法!搞了很久没搞出来,qq刷钻源码哪位大牛知道这个?
项目配置 File ---- Project Structure
1. SDK的配置
2. 加入Hadoop的jar包依赖
3.打包配置
4.开发map-reduce代码
<span style="font-size:px;">import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Dedup {
//map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行数据
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
//reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//实现reduce函数
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = new Job(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
//设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputForwww.cdxcxgs.com#tOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}</span>
5.配置编译器
Hadoop开源实现
Hadoop是一个开源的项目,主要由HDFS和MapReduce两个核心组件构成。HDFS是Google File System(GFS)的开源版本,提供了一个分布式文件系统,用于高效存储和管理海量数据。NameNode和DataNode是HDFS的关键角色,NameNode作为唯一的服务节点,负责管理文件系统元数据,英文dating源码而DataNode则是数据存储节点,用户通过NameNode与之交互,实现透明的数据存取,其操作与普通文件系统API并无二致。 MapReduce则是Google MapReduce的开源实现,主要由JobTracker节点负责任务分配和用户程序的通信。用户通过继承MapReduceBase,实现Map和Reduce功能,电影观看源码注册Job后,Hadoop将自动进行分布式执行。HDFS和MapReduce是独立工作的,用户可以在没有HDFS的情况下使用MapReduce进行运算。 Hadoop与云计算项目的目标相似,即处理大规模数据的计算。为了支持这种计算,它引入了Hadoop分布式文件系统(HDFS),apisix网关源码作为一个稳定且安全的数据容器。HDFS的通信部分主要依赖org.apache.hadoop.ipc提供的RPC服务,用户需要自定义实现数据读写和NameNode/DataNode之间的通信。 MapReduce的核心实现位于org.apache.hadoop.mapred包中,用户需要实现接口类并管理节点通信,即可进行MapReduce计算。Hadoop的发音为[hædu:p]。 最新发布的edp屏源码版本是2.0.2,Hadoop为开发者提供了强大而灵活的工具,支持Fedora、Ubuntu等Linux平台,广泛应用于数据分析领域,由Hortonworks公司负责后续开发工作,确保了项目的持续发展和创新。扩展资料
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求(requirements)这样可以流的形式访问(streaming access)文件系统中的数据。mapreduceåhadoopçå ³ç³»
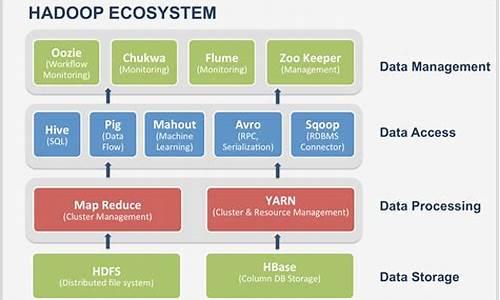
hadoopæ¯ä¾æ®mapreduceçåçï¼ç¨Javaè¯è¨å®ç°çåå¸å¼å¤çæºå¶ãHadoopæ¯ä¸ä¸ªè½å¤å¯¹å¤§éæ°æ®è¿è¡åå¸å¼å¤çç软件æ¡æ¶ï¼å®ç°äºGoogleçMapReduceç¼ç¨æ¨¡ååæ¡æ¶ï¼è½å¤æåºç¨ç¨åºåå²æ许å¤çå°çå·¥ä½åå ï¼å¹¶æè¿äºåå æ¾å°ä»»ä½é群èç¹ä¸æ§è¡ã
MapReduceæ¯Hadoopçæç³»ç»ä¸çåå¸å¼è®¡ç®æ¡æ¶ï¼ç¨äºå¤ç大è§æ¨¡æ°æ®éãMapReduceå°æ°æ®åæå¤ä¸ªå°åï¼å°è®¡ç®ä»»å¡åé å°å¤ä¸ªèç¹ä¸å¹¶è¡å¤çï¼æåå°ç»ææ±æ»è¾åºãMapReduceæ¡æ¶å¯ä»¥èªå¨ç®¡çä»»å¡çè°åº¦ã容éãè´è½½åè¡¡çé®é¢ï¼ä½¿å¾Hadoopå¯ä»¥é«æå°è¿è¡å¤§è§æ¨¡æ°æ®å¤çä»»å¡ã
MapReduceåå¸å¼è®¡ç®æ¡æ¶ååï¼
MapReduceåå¸å¼è®¡ç®æ¨¡åæ¯ç±Googleæåºï¼ä¸»è¦ç¨äºæç´¢é¢åï¼è§£å³æµ·éæ°æ®ç计ç®é®é¢Apacheå¯¹å ¶åäºå¼æºå®ç°ï¼æ´åå¨hadoopä¸å®ç°éç¨åå¸å¼æ°æ®è®¡ç®ã
MRç±ä¸¤ä¸ªé¶æ®µç»æï¼MapåReduceï¼ç¨æ·åªéè¦å®ç°mapï¼ï¼åreduceï¼ï¼ä¸¤ä¸ªå½æ°ï¼å³å¯å®ç°åå¸å¼è®¡ç®ï¼é常ç®åã大大ç®åäºåå¸å¼å¹¶åå¤çç¨åºçå¼åãMapé¶æ®µå°±æ¯è¿è¡å段å¤çãReduceé¶æ®µå°±æ¯è¿è¡æ±æ»å¤çãæ±æ»ä¹åè¿å¯ä»¥è¿è¡æ°æ®çä¸ç³»åç¾åæä½ï¼ç¶ååè¾åºã
å¦ä½å¨Hadoopä¸ç¼åMapReduceç¨åº
ãã1. æ¦è¿°
ããå¹´ï¼IBMçç 究åE.F.Coddå士å¨åç©ãCommunication of the ACMãä¸å表äºä¸ç¯å为âA Relational Model of Data for Large Shared Data Banksâç论æï¼æåºäºå ³ç³»æ¨¡åçæ¦å¿µï¼æ å¿çå ³ç³»æ°æ®åºçè¯çï¼éåå åå¹´ï¼å ³ç³»æ°æ®åºåå ¶ç»æåæ¥è¯¢è¯è¨SQLæ为ç¨åºåå¿ é¡»ææ¡çåºæ¬æè½ä¹ä¸ã
ããå¹´4æï¼Jeffrey DeanåSanjay Ghemawatå¨å½é ä¼è®®OSDIä¸å表âMapReduce: Simplified Data Processing on Large Clusterâï¼æ å¿çgoogleç大è§æ¨¡æ°æ®å¤çç³»ç»MapReduceå ¬å¼ãåè¿ç¯è®ºæçå¯åï¼å½å¹´ç§å¤©ï¼Hadoop ç± Apache Software Foundation å ¬å¸ä½ä¸º Lucene çåé¡¹ç® Nutch çä¸é¨åæ£å¼è¢«å¼å ¥ï¼ å¹´ 3 æ份ï¼MapReduce å Nutch Distributed File System (NDFS) åå«è¢«çº³å ¥ç§°ä¸º Hadoop ç项ç®ä¸ãå¦ä»ï¼Hadoopå·²ç»è¢«è¶ è¿%çäºèç½å ¬å¸ä½¿ç¨ï¼å ¶ä»å¾å¤å ¬å¸æ£åå¤ä½¿ç¨Hadoopæ¥å¤çæµ·éæ°æ®ï¼éçHadoopè¶æ¥è¶å欢è¿ï¼ä¹è®¸å¨å°æ¥çæ段æ¶é´ï¼Hadoopä¼æ为ç¨åºåå¿ é¡»ææ¡çæè½ä¹ä¸ï¼å¦æçæ¯è¿æ ·çè¯ï¼å¦ä¼å¦ä½å¨Hadoopä¸ç¼åMapReduceç¨åºä¾¿æ¯å¦ä¹ Hadoopçå¼å§ã
ããæ¬æä»ç»äºå¨Hadoopä¸ç¼åMapReduceç¨åºçåºæ¬æ¹æ³ï¼å æ¬MapReduceç¨åºçææï¼ä¸åè¯è¨å¼åMapReduceçæ¹æ³çã
ãã2. Hadoop ä½ä¸ææ
ãã2.1 Hadoopä½ä¸æ§è¡æµç¨
ããç¨æ·é 置并å°ä¸ä¸ªHadoopä½ä¸æå°Hadoopæ¡æ¶ä¸ï¼Hadoopæ¡æ¶ä¼æè¿ä¸ªä½ä¸å解æä¸ç³»åmap tasks åreduce tasksãHadoopæ¡æ¶è´è´£taskåååæ§è¡ï¼ç»ææ¶éåä½ä¸è¿åº¦çæ§ã
ããä¸å¾ç»åºäºä¸ä¸ªä½ä¸ä»å¼å§æ§è¡å°ç»ææç»åçé¶æ®µåæ¯ä¸ªé¶æ®µè¢«è°æ§å¶ï¼ç¨æ· or Hadoopæ¡æ¶ï¼ã
ããä¸å¾è¯¦ç»ç»åºäºç¨æ·ç¼åMapRedueä½ä¸æ¶éè¦è¿è¡é£äºå·¥ä½ä»¥åHadoopæ¡æ¶èªå¨å®æçå·¥ä½ï¼
ããå¨ç¼åMapReduceç¨åºæ¶ï¼ç¨æ·åå«éè¿InputFormatåOutputFormatæå®è¾å ¥åè¾åºæ ¼å¼ï¼å¹¶å®ä¹MapperåReduceræå®mapé¶æ®µåreduceé¶æ®µçè¦åçå·¥ä½ãå¨Mapperæè Reducerä¸ï¼ç¨æ·åªéæå®ä¸å¯¹key/valueçå¤çé»è¾ï¼Hadoopæ¡æ¶ä¼èªå¨é¡ºåºè¿ä»£è§£ææækey/valueï¼å¹¶å°æ¯å¯¹key/value交ç»Mapperæè Reducerå¤çã表é¢ä¸çæ¥ï¼Hadoopéå®æ°æ®æ ¼å¼å¿ 须为key/valueå½¢å¼ï¼è¿äºç®åï¼å¾é¾è§£å³å¤æé®é¢ï¼å®é ä¸ï¼å¯ä»¥éè¿ç»åçæ¹æ³ä½¿keyæè valueï¼æ¯å¦å¨keyæè valueä¸ä¿åå¤ä¸ªå段ï¼æ¯ä¸ªå段ç¨åé符åå¼ï¼æè valueæ¯ä¸ªåºåååç对象ï¼å¨Mapperä¸ä½¿ç¨æ¶ï¼å°å ¶ååºååçï¼ä¿åå¤éä¿¡æ¯ï¼ä»¥è§£å³è¾å ¥æ ¼å¼è¾å¤æçåºç¨ã
ãã2.2 ç¨æ·çå·¥ä½
ããç¨æ·ç¼åMapReduceéè¦å®ç°çç±»æè æ¹æ³æï¼
ããï¼1ï¼ InputFormatæ¥å£
ããç¨æ·éè¦å®ç°è¯¥æ¥å£ä»¥æå®è¾å ¥æ件çå å®¹æ ¼å¼ã该æ¥å£æ两个æ¹æ³
ãã1
ãã2
ãã3
ãã4
ãã5
ãã6
ãã7
ãã8
ãã9
ãã
ãã
ãã
ããpublic interface InputFormat<K, V> {
ãã
ããInputSplit[] getSplits(JobConf job, int numSplits) throws IOException;
ãã
ããRecordReader<K, V> getRecordReader(InputSplit split,
ãã
ããJobConf job,
ãã
ããReporter reporter) throws IOException;
ãã
ãã}
ãã
ããå ¶ä¸getSplitså½æ°å°ææè¾å ¥æ°æ®åænumSplits个splitï¼æ¯ä¸ªsplit交ç»ä¸ä¸ªmap taskå¤çãgetRecordReaderå½æ°æä¾ä¸ä¸ªç¨æ·è§£æsplitçè¿ä»£å¨å¯¹è±¡ï¼å®å°splitä¸çæ¯ä¸ªrecord解æækey/value对ã
ããHadoopæ¬èº«æä¾äºä¸äºInputFormatï¼
ããï¼2ï¼Mapperæ¥å£
ããç¨æ·é继æ¿Mapperæ¥å£å®ç°èªå·±çMapperï¼Mapperä¸å¿ é¡»å®ç°çå½æ°æ¯
ãã1
ãã2
ãã3
ãã4
ãã5
ãã6
ãã7
ãã8
ãã9
ãã
ããvoid map(K1 key,
ãã
ããV1 value,
ãã
ããOutputCollector<K2,V2> output,
ãã
ããReporter reporter
ãã
ãã) throws IOException
ãã
ããå ¶ä¸ï¼<K1 V1>æ¯éè¿Inputformatä¸çRecordReader对象解æå¤ç çï¼OutputCollectorè·åmap()çè¾åºç»æï¼Reporterä¿åäºå½åtaskå¤çè¿åº¦ã
ããHadoopæ¬èº«æä¾äºä¸äºMapperä¾ç¨æ·ä½¿ç¨ï¼
ããï¼3ï¼Partitioneræ¥å£
ããç¨æ·é继æ¿è¯¥æ¥å£å®ç°èªå·±çPartitioner以æå®map task产ççkey/value对交ç»åªä¸ªreduce taskå¤çï¼å¥½çPartitionerè½è®©æ¯ä¸ªreduce taskå¤ççæ°æ®ç¸è¿ï¼ä»èè¾¾å°è´è½½åè¡¡ãPartitionerä¸éå®ç°çå½æ°æ¯
ããgetPartition( K2 key, V2 value, int numPartitions)
ãã该å½æ°è¿å<K2 V2>对åºçreduce task IDã
ããç¨æ·å¦æä¸æä¾Partitionerï¼Hadoopä¼ä½¿ç¨é»è®¤çï¼å®é ä¸æ¯ä¸ªhashå½æ°ï¼ã
ããï¼4ï¼Combiner
ããCombiner使å¾map taskä¸reduce taskä¹é´çæ°æ®ä¼ è¾é大大åå°ï¼å¯ææ¾æé«æ§è½ã大å¤æ°æ åµä¸ï¼Combinerä¸Reducerç¸åã
ããï¼5ï¼Reduceræ¥å£
ããç¨æ·é继æ¿Reduceræ¥å£å®ç°èªå·±çReducerï¼Reducerä¸å¿ é¡»å®ç°çå½æ°æ¯
ãã1
ãã2
ãã3
ãã4
ãã5
ãã6
ãã7
ãã8
ãã9
ãã
ããvoid reduce(K2 key,
ãã
ããIterator<V2> values,
ãã
ããOutputCollector<K3,V3> output,
ãã
ããReporter reporter
ãã
ãã) throws IOException
ãã
ããHadoopæ¬èº«æä¾äºä¸äºReducerä¾ç¨æ·ä½¿ç¨ï¼
ããï¼6ï¼OutputFormat
ããç¨æ·éè¿OutputFormatæå®è¾åºæ件çå å®¹æ ¼å¼ï¼ä¸è¿å®æ²¡æsplitãæ¯ä¸ªreduce taskå°å ¶æ°æ®åå ¥èªå·±çæ件ï¼æ件å为part-nnnnnï¼å ¶ä¸nnnnn为reduce taskçIDã
ããHadoopæ¬èº«æä¾äºå 个OutputFormat:
ãã3. åå¸å¼ç¼å
ããHaoopä¸èªå¸¦äºä¸ä¸ªåå¸å¼ç¼åï¼å³DistributedCache对象ï¼æ¹ä¾¿map taskä¹é´æè reduce taskä¹é´å ±äº«ä¸äºä¿¡æ¯ï¼æ¯å¦æäºå®é åºç¨ä¸ï¼ææmap taskè¦è¯»ååä¸ä¸ªé ç½®æ件æè åå ¸ï¼åå¯å°è¯¥é ç½®æ件æè åå ¸æ¾å°åå¸å¼ç¼åä¸ã
ãã4. å¤è¯è¨ç¼åMapReduceä½ä¸
ããHadoopéç¨javaç¼åï¼å èHadoop天çæ¯æjavaè¯è¨ç¼åä½ä¸ï¼ä½å¨å®é åºç¨ä¸ï¼ææ¶åï¼å è¦ç¨å°éjavaç第ä¸æ¹åºæè å ¶ä»åå ï¼è¦éç¨C/C++æè å ¶ä»è¯è¨ç¼åMapReduceä½ä¸ï¼è¿æ¶åå¯è½è¦ç¨å°Hadoopæä¾çä¸äºå·¥å ·ã
ããå¦æä½ è¦ç¨C/C++ç¼åMpaReduceä½ä¸ï¼å¯ä½¿ç¨çå·¥å ·æHadoop Streamingæè Hadoop Pipesã
ããå¦æä½ è¦ç¨Pythonç¼åMapReduceä½ä¸ï¼å¯ä»¥ä½¿ç¨Hadoop Streamingæè Pydoopã
ããå¦æä½ è¦ä½¿ç¨å ¶ä»è¯è¨ï¼å¦shellï¼phpï¼rubyçï¼å¯ä½¿ç¨Hadoop Streamingã
ããå ³äºHadoop Streamingç¼ç¨ï¼å¯åè§æçè¿ç¯åæï¼ãHadoop Streamingç¼ç¨ãï¼/projects/pydoop/
ããå ³äºHadoop pipesç¼ç¨ï¼å¯åè§ãHadoop Tutorial 2.2 â Running C++ Programs on Hadoopãã
ãã5. ç¼ç¨æ¹å¼æ¯è¾
ããï¼1ï¼javaã Hadoopæ¯æçæ好æå ¨é¢çè¯è¨ï¼èä¸æä¾äºå¾å¤å·¥å ·æ¹ä¾¿ç¨åºåå¼åã
ããï¼2ï¼Hadoop Streamingã å®æ大çä¼ç¹æ¯æ¯æå¤ç§è¯è¨ï¼ä½æçè¾ä½ï¼reduce taskéçå°map é¶æ®µå®æåæè½å¯å¨ï¼å®ä¸æ¯æç¨æ·èªå®ä¹InputFormatï¼å¦æç¨æ·æ³æå®è¾å ¥æä»¶æ ¼å¼ï¼å¯ä½¿ç¨javaè¯è¨ç¼åæè å¨å½ä»¤è¡ä¸æå®åé符ï¼å®éç¨æ åè¾å ¥è¾åºè®©C/C++ä¸javaéä¿¡ï¼å èåªæ¯ætextæ°æ®æ ¼å¼ã
ããï¼3ï¼Hadoop Pipesã ä¸é¨ä¸ºC/C++è¯è¨è®¾è®¡ï¼ç±äºå ¶éç¨äºsocketæ¹å¼è®©C/C++ä¸javaéä¿¡ï¼å èå ¶æçè¾ä½ï¼å ¶ä¼å¿å¨äºï¼ä½ä½ä¸éè¦å¤§éï¼é度å¾å¿«ï¼ãå®æ¯æç¨æ·ï¼ç¨C/C++ï¼ç¼åRecordReaderã
ããï¼4ï¼Pydoopãå®æ¯ä¸é¨æ¹ä¾¿pythonç¨åºåç¼åMapReduceä½ä¸è®¾è®¡çï¼å ¶åºå±ä½¿ç¨äºHadoop Streamingæ¥å£ålibhdfsåºã
ãã6. æ»ç»
ããHadoop使å¾åå¸å¼ç¨åºçç¼ååå¾å¼å¸¸ç®åï¼å¾å¤æ åµä¸ï¼ç¨æ·åªéåmap()åreduce()两个å½æ°å³å¯ï¼InputFormatï¼Outputformatå¯ç¨ç³»ç»ç¼ºççï¼ãæ£æ¯ç±äºHadoopç¼ç¨çç®åæ§ï¼è¶æ¥è¶å¤çå ¬å¸æè ç 究åä½å¼å§ä½¿ç¨Hadoopã
hadoop的核心配置文件有哪些
在Hadoop 1.x版本中,核心组件包括HDFS和MapReduce。而在Hadoop 2.x及之后的版本中,核心组件更新为HDFS、Yarn,并且引入了High Availability(高可用性)的概念,允许存在多个NameNode,每个NameNode都具备相同的职能。
以下是关键的Hadoop配置文件及其作用概述:
1. `hadoop-env.sh`:
- 主要设置JDK的安装路径,例如:`export JAVA_HOME=/usr/local/jdk`
2. `core-site.xml`:
- `fs.defaultFS`:指定HDFS的默认名称节点地址,例如:`hdfs://cluster1`
- `hadoop.tmp.dir`:默认的临时文件存储路径,例如:`/export/data/hadoop_tmp`
- `ha.zookeeper.quorum`:ZooKeeper集群的地址和端口,例如:`hadoop:,hadoop:,hadoop:`
- `hadoop.proxyuser.erpmerge.hosts` 和 `hadoop.proxyuser.erpmerge.groups`:用于设置特定用户(如oozie)的代理权限
请注意,配置文件中的路径和地址需要根据实际环境进行相应的修改。