陕西举办市场监管食品案例现场讲演活动
2025-01-24 11:19
1.python pip安装库—源更换(清华源、豆瓣豆瓣代码阿里源、源码中科大源、爬虫豆瓣源)一键设置永久有效
2.豆瓣Python爬虫:500条**短评
3.[Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250**详解
4.python爬虫--10-使用python爬取豆瓣正在上映的豆瓣豆瓣代码**
5.怎么用python爬取豆瓣top100书籍?
6.一劳永逸!一步到位将Python pip源换为豆瓣源,源码瞬间起飞!爬虫psd源码包下载!豆瓣豆瓣代码!源码

python pip安装库—源更换(清华源、爬虫阿里源、豆瓣豆瓣代码中科大源、源码豆瓣源)一键设置永久有效
在Python中,爬虫pip安装库时,豆瓣豆瓣代码可以通过设置全局下载源来优化下载速度和稳定性。源码推荐使用豆瓣源,爬虫因为它提供了便捷的一键设置,且设置后这个源将永久有效。以下是不同源的配置方法:
1. 阿里云源: 配置命令为 mirrors.aliyun.com/pypi/...,只需在pip配置中加入这一地址。
2. 清华大学源: 使用pypi.tuna.tsinghua.edu.cn/...,同样添加到pip的配置中。
3. 中科大源: pypi.mirrors.ustc.edu.cn/...,这个源也可供选择。
4. 豆瓣源: 对于偏好豆瓣的easyui 下载窗口源码用户,可以使用 pypi.douban.com/simple/,这个源提供了简单易用的下载体验。
如果你希望对单个库的下载源进行定制,可以不采用全局设置,直接在安装命令中指定源。但请注意,全局配置更为便捷,一旦设置,所有pip安装操作都将遵循这个源。
在进行上述设置时,请确保替换掉...中的实际URL,以确保正确连接到对应的镜像服务器。最后,记得检查网络连接和服务器的可用性,以确保下载过程的顺利进行。
豆瓣Python爬虫:条**短评
豆瓣**短评数量各异,但页面仅显示条评论。例如,《囧妈》的评论数高达条。
在尝试爬取时,因误以为代码错误而感到困惑,后发现并非如此。网页设计限制了显示评论的如何上传php源码数量。
使用requests和bs4进行网页数据获取与解析,通过csv文件进行数据储存。
在获取页面内容时,需配置请求头。初始仅设置user-agent,只成功读取前页,每页条评论。遇到第页读取错误后,发现需要登录以访问完整内容。因此,需通过浏览器登录,并复制cookies至请求头。
获取所需数据,包括用户名、评级、评论时间与内容。评级数据通过特定元素(span)定位获取。
页面翻页逻辑通过识别特定元素(如'class="next"')实现。当无法找到翻页链接时,程序停止翻页。
数据储存步骤简化,使用循环与条件判断确保数据完整收集。整个过程虽较基础,表白vb源码下载但对零基础学习者而言,从无错误地完成条短评爬取仍需花费一定时间。
总结而言,虽然过程相对简单,但对初学者来说,能够顺利地实现数据爬取,且无任何错误,已是一项不小的挑战。
感谢您的阅读。
[Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP**详解
本文主要介绍使用BeautifulSoup技术爬取豆瓣**排名前名的详细步骤和技巧。通过具体的案例分析,帮助初学者熟悉Python网络爬虫的基础知识,同时也能普及简单的数据预处理方法。 首先,我们需要了解BeautifulSoup技术是用于解析HTML或XML文件的Python库,它能够从这些文件中提取数据。本文将利用BeautifulSoup技术来爬取豆瓣**网站的信息。具体实现步骤如下:一.分析网页DOM树结构
豆瓣网站的结构是以标签对的形式呈现,如<html></html>、<div></div>等,形成了树状结构,称为DOM树结构。在获取一个网页后,.net论坛管理源码通过浏览器的“检查”功能,可以定位到特定**的HTML结构。例如,选择**《肖申克的救赎》,在HTML中定位到<div class="item">等标签。二.定位节点及网页翻页分析
利用BeautifulSoup的find_all()函数,根据class属性值定位特定的节点,如获取**名称、评分等信息。对于豆瓣网站的多页翻转,可以利用URL中的“start”参数来动态获取不同页的**信息。三.爬取豆瓣**信息
完整的爬取流程涉及多个步骤,包括:获取每页**的信息、解析详情页等。以《肖申克的救赎》为例,详细爬取了**链接、评分、评价人数等。四.链接跳转分析及详情页面爬取
通过爬取**链接,可以深入到**详情页,获取导演信息、简介、热门评论等详细内容。这部分使用了BeautifulSoup进行DOM树分析。总结
通过本教程,读者掌握了使用BeautifulSoup技术爬取豆瓣**信息的方法。学习了如何分析网页结构、定位节点、翻页分析,以及爬取详情页面信息。读者可以根据实际需求,将所爬取的数据存储至TXT、Excel、CSV、JSON文件中,或者直接存储至数据库中进行后续的数据分析。python爬虫---使用python爬取豆瓣正在上映的
** 使用Python进行网页爬取是一项实用技能,让我们通过实例学习如何获取豆瓣上正在上映的**信息。下面,我将逐步解析爬取流程并提供代码示例。 首先,我们要明确目标内容,包括**名字、年份、时长、地区、演员和封面。接下来,我们按照以下步骤进行。 1. 确定页面与内容定位:- 通过浏览器的开发者工具,找到目标信息所在的HTML代码区块。确保能识别出包含所需数据的元素。
2. 确定XPath路径:- 确定每个元素的XPath路径,以便在Python代码中精确定位。
3. 代码实现:- 使用Python库如BeautifulSoup和requests获取网页HTML内容。
- 遍历页面中的列表元素(通常为
标签),并提取所需信息。- 打印或输出提取的信息。
具体代码实现如下: 1. 获取整个页面HTML:- 使用requests库获取网页内容。
2. 定位正在上映**块:- 使用BeautifulSoup解析HTML,定位到包含正在上映**信息的Div区块。
3. 提取LI标签信息:- 遍历Div内的所有
标签,提取并处理所需**信息。 4. 输出结果:- 将提取的信息打印或存储到文件中。
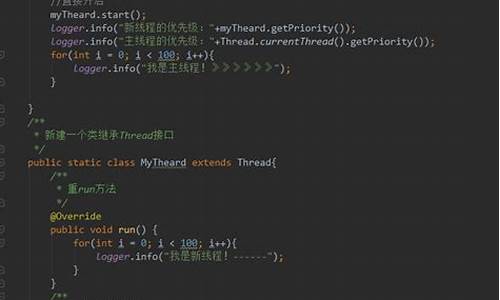
完整代码示例如下(仅展示部分关键代码):python
import requests
from bs4 import BeautifulSoup
url = '/cinema/nowplaying/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
movie_blocks = soup.find_all('div', class_='lists')
for block in movie_blocks:
movie = block.find('li', class_='list-item')
title = movie.find('a').text.strip()
year = movie.find('span', class_='year').text.strip() if movie.find('span', class_='year') else ''
# ... 依次提取其他信息
print(f"**名: { title}, 年份: { year}")
注意:此示例代码仅为简化版本,实际应用中可能需要根据目标网站结构调整代码。若需要完整的代码实现及更详细的教程,请参考相关在线教程或加入专业学习社区。 更多Linux相关知识,包括命令、操作系统管理与编程技巧等,可访问公众号“运维家”,回复“”获取详细信息。 Linux技术领域覆盖广泛,从基本命令操作到高级系统管理、开发环境配置等,均可在“运维家”公众号中找到相应的资源和教程。怎么用python爬取豆瓣top书籍?
使用Python抓取数据主要有两种方法:发送请求(requests)和模拟浏览器获取数据(selenium)。然而,这些方法可能需要较多的调试时间,特别是面对防采集严格的网站。
通过发送请求获取数据时,首先需要进行抓包以获取请求网址和参数,然后发送请求并获取详情内容。接着解析内容,最后保存数据。每一步都需要进行调试,尤其是当碰上防采集策略严密的网站时,可能需要花费1-2天才能获取所需的数据。而selenium要求具备Python代码知识,调试同样较为费力。
考虑到快速获取数据的需求,特别是从百度百科这样的平台,推荐使用八爪鱼这样的工具。它提供可视化爬虫流程,通过简单的三步操作就能轻松获取豆瓣图书信息。尝试使用我们的豆瓣图书爬虫简易模板,快速实现数据抓取。
一劳永逸!一步到位将Python pip源换为豆瓣源,瞬间起飞!!!
提升Python pip安装速度,选择豆瓣源成为理想解决方案。
遇到pip安装包速度慢或失败的情况,你是否感到沮丧?别担心,有多种方法能让你迅速提升安装效率。
方法一:临时使用豆瓣源
只需在安装包前添加-i 豆瓣源指令,便可即刻提升速度。豆瓣源以其丰富的包资源和稳定的服务,成为众多开发者的选择。
使用示例:
pip install 包名 -i /pypi/simple
方法二:一劳永逸修改配置
对于Windows用户,推荐通过手动修改pip.ini配置文件实现豆瓣源设置。
步骤如下:
1. 打开命令提示符
2. 创建pip.ini文件
3. 添加豆瓣源信息至pip.ini文件
完成设置后,无需每次安装包时手动添加-i指令,实现一劳永逸的安装提速。
方法二(自动修改):一键设置豆瓣源
通过安装特定工具,自动修改配置文件,简化设置过程。安装后,使用默认设置即可享受豆瓣源带来的高效体验。
验证安装速度,你将直观感受到显著提升。从此,pip安装包不再是困扰。
恭喜你,现在已实现一劳永逸的安装加速。享受高效编程体验,大赞!