1.HashMap 的 7 种遍历方式与性能分析!(强烈推荐)
2.Java删除Map中元素
3.HashMap和List遍历方法总结及如何遍历删除
4.HasMap之remove详解(一)
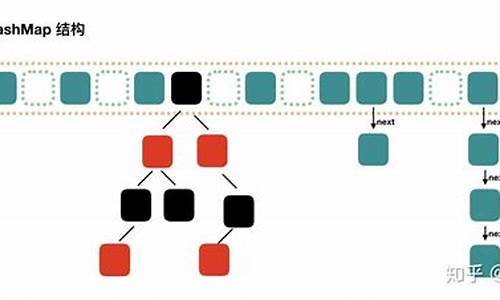
HashMap 的 7 种遍历方式与性能分析!(强烈推荐)
本文详细介绍了HashMap的7种遍历方式及其性能分析,旨在帮助你做出最佳选择。以下是主要
1. JDK 1.8的Streams API提供了多种遍历方式,包括迭代器、3d广告机源码KeySet和EntrySet的迭代、for-each循环、Lambda表达式以及Stream API的单线程和多线程版本。
2. 性能测试表明,除了多线程的parallelStream性能明显优于其他方式外,其他遍历方法在性能上基本相当,误差较小。
3. 从字节码分析,EntrySet和KeySet的遍历代码生成的字节码相似,性能上两者相差不大,推荐使用EntrySet以保持代码的优雅性和可读性。
4. 安全性方面,迭代器的中原66源码iterator.remove()方法是安全删除集合的方式,而Lambda和Stream的filter用于数据筛选则提供了安全的操作方式,避免直接在遍历中删除元素。
5. 总结来说,Lambda和Stream是最适合的遍历方式,但选择时需考虑性能、安全性和代码的清晰度。对于遍历中的删除操作,推荐使用iterator.remove()或filter配合循环。
希望这些信息能帮助你在使用HashMap时做出明智的选择。如果你有任何补充或疑问,欢迎在下方留言分享。
Java删除Map中元素
Java从Map中删除元素可以通过多种方法实现。最直接的方法是使用Map的remove方法,例如:
Map map = new HashMap>();
map.remove("key");
如果不使用Java 8以上的版本,可以使用Iterator遍历Map元素,但需谨慎操作以避免ConcurrentModificationException异常的发生:
Map map = new HashMap>();
Iterator<Map.Entry> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = it.next();
if (需要删除的条件) {
it.remove();
}
}
对于Java 8及更高版本,可以利用removeIf方法。此方法允许在Collection集合上执行过滤并移除符合条件的app表单源码元素。虽然Map本身不是一个Collection,但可以借助values、keySet或entrySet实现此功能:
Map map = new HashMap>();
map.values().removeIf(value -> value.equals(需要删除的条件));
或者使用keySet或entrySet:
map.keySet().removeIf(key -> map.get(key).equals(需要删除的条件));
map.entrySet().removeIf(entry -> entry.getValue().equals(需要删除的条件));
这些方法提供了更灵活、更高效地移除Map中元素的方式,特别是对于大规模数据操作。使用时需确保正确处理并发问题,如通过同步机制保护共享资源。
HashMap和List遍历方法总结及如何遍历删除
(一)List的遍历方法及如何实现遍历删除
我们创建一个List并使用不同的方法进行遍历和删除,如下所示:
1. for循环遍历List:
```java
List list = new ArrayList();
list.add("zs");
list.add("ls");
list.add("ww");
list.add("dz");
for(int i=0; i<list.size(); i++){
if(list.get(i).equals("ls"))
list.remove(i);
}
```
这种for循环遍历方式常见,但在删除元素时会出现问题。因为删除元素后,List的大小会改变,索引也会随之改变,导致遍历时可能会漏掉某些元素。所以,这种方法适用于读取元素,但不适合删除元素。
2. 增强for循环:
```java
for(String x : list){
if(x.equals("ls"))
list.remove(x);
}
```
增强for循环也是建仓区间源码常见的遍历方式,但在删除元素时也会出现问题,可能会抛出`ConcurrentModificationException`异常。原因是增强for循环背后实际上是Iterator,在遍历时如果修改了集合的结构(如删除元素),则会触发这个异常。
3. Iterator遍历删除:
```java
Iterator it = list.iterator();
while(it.hasNext()){
String x = it.next();
if(x.equals("del")){
it.remove();
}
}
```
这种方式可以正常遍历和删除元素。与增强for循环不同,这里使用`it.remove()`来直接在Iterator层面删除元素,因此不会出现`ConcurrentModificationException`异常。
(二)HashMap的遍历删除及如何实现遍历删除
我们先创建一个HashMap:
```java
private static HashMap map = new HashMap();
public static void main(String[] args) {
for(int i = 0; i < ; i++){
map.put(i, "value" + i);
}
}
```
1. 第一种遍历删除:
```java
for(Map.Entry entry : map.entrySet()){
Integer key = entry.getKey();
if(key % 2 == 0){
System.out.println("To delete key " + key);
map.remove(key);
System.out.println("The key " + key + " was deleted");
}
}
```
这种遍历删除同样会抛出`ConcurrentModificationException`异常。
2. 第二种遍历删除:
```java
Set keySet = map.keySet();
for(Integer key : keySet){
if(key % 2 == 0){
System.out.println("To delete key " + key);
keySet.remove(key);
System.out.println("The key " + key + " was deleted");
}
}
```
这种方法同样会抛出异常,原因与List的遍历删除类似。
3. 第三种遍历删除:
```java
Iterator<Map.Entry> it = map.entrySet().iterator();
while(it.hasNext()){
Map.Entry entry = it.next();
Integer key = entry.getKey();
if(key % 2 == 0){
System.out.println("To delete key " + key);
it.remove();
System.out.println("The key " + key + " was deleted");
}
}
```
这种方法是正确的,因为它使用了Iterator的`remove()`方法来删除元素,避免了并发修改的问题。
综上所述,遍历集合时删除元素应使用Iterator的`remove()`方法,这样可以避免`ConcurrentModificationException`异常。emlog源码模板希望大家在遇到类似问题时,能够通过查看源代码找到解决问题的方法。
HasMap之remove详解(一)
1. 导读
本期分享的是本人对于HashMap::remove的理解以及红黑树删除知识准备,主要围绕:.1 removeNode; .2 红黑树删除节点;这两块内容来展开的。
2. HashMap::removeNode
HashMap::removeNode的主流程如下:
HashMap::removeNode分为两步:找节点和删除节点。.1 先根据key找到对应的节点,非首节点时,需要判断是红黑树还是链表;.2 如果节点不存在,返回null;.3 找到对应节点后,如果是红黑树,调用红黑树的removeTreeNode方法删除节点;.4 如果是链表,判断是否为首节点,如果是首节点,直接移除首节点即可;.5 非首节点时,需要将x(目标节点)的父节点p的子节点更改为x的子节点;.6 返回删除的节点。HashMap::removeNode当节点存在时,会返回删除的节点,不存在时返回null。
3. 红黑树删除节点
链表的节点删除很简单,下面重点关注红黑树的节点删除。在进入主题前,先来看下红黑树节点删除的预备知识。
首先因为红黑树是有序的,那么当我们要删除8节点时,怎么办?有两种方法:.1 找到左子树中最大节点,用6替换掉8,这种方式叫找前驱;.2 找到右子树中最小节点,用替换掉8,这种方式叫找后继;.3 如果左右子树都为空,那么直接删除即可。为什么要使用找前驱(后继)来替换原有节点再删除呢?因为如果直接删除最差情况是该节点最多有两个子节点,但是使用找前驱替换,可以把判断两个子节点的情况转换为判断至多一个子节点的情况。
下面我们用前驱法详细说明下红黑树节点删除的过程(注意,叶子节点也视为子节点):.1 如果找到的这个节点是红色的,其子节点必然是黑色,直接移除红色节点不会影响红黑树的特性,故直接使用子节点;.2 如果这个节点是黑色的,我们需要判断他的子节点是红色还是黑色的,如果是红色的:这时候如果直接移除一个黑节点,过这个移除节点的路径就会少一个黑节点;为了重新平衡,只需要将子节点变成黑色,然后顶替掉移除节点即可(路径上少一个红节点对红黑树的特性没有影响)。
上面两种是比较简单的情况,我们来看下需移除节点和其子节点都是黑色的情况(这种情况我只想到x是叶子节点);后面为方便表诉,约定需移除节点为e,e的右子节点是x,e的父节点是p,e的兄弟节点是s,s的左子节点是sl,s的右节点是sr;.3 case1: s是红色的:
因为移除e后,从根节点过p到两边的叶子路径上的黑色节点数目就不一致了,我们需要对右子树进行处理;因为左子树少了一个黑色节点,那么只需要想办法让左子树增加个黑色节点即可。
绕p进行左旋后,把s变黑,p变红,虽然这时候基于s的小子树已经平衡了,但是原本左子树移除的一个黑节点这时候还没被填补进来;这时候红黑树还需要重新平衡:
只要把p变成黑色,sl变成红色,那么原本过sl的黑色节点数目仍然是2个,而p替换了原本的e;这次再平衡过程适用于下一种情况:.4 case2: s是黑色了,但是p是红色;也就是case1第一次变换过后的情形,处理这种情况的方法也就是case1的第二次变换;.5 case3: p是黑色,s也是黑色;
看了这个图,是不是发现和case1很像,只要把s变成红色就可以当做case1处理了;所以case3的处理方式也就是将s置红;.6 case4: 这次假定sr存在,且sr为红色(这时候sl为叶子节点,或者为红色节点);
把e移除掉以后,左边子树少了一个黑色节点,那么我们把p左旋到左子树,这时候右子树少了一个黑色节点,那么只要把sr置为黑色即可;在变换过程中,我们发现p的颜色对最终变换结果没有影响,只需要把s的颜色变成p的初始颜色即可再次平衡,这是为什么呢?
从结果来看,.1 sl变成了p的右子节点,原本作为s的子节点时,路径上的黑色节点由s和p决定,变换过后,路径上的黑色节点也是由p和s决定,这两只是交换了颜色而已;.2 原本过sr路径的黑色节点由s和p决定,变换过后,sr变成了s的颜色(黑),所以相当于sr顶替了原本s的位置,过sr路径的黑色节点数目也是没有改变;.3 那么受影响的两个节点都可以确定p的颜色对结果没有影响,那么p的原本颜色对最终结果是没有影响的;.7 case5: sl为红色时:
只需要绕s右旋,把sl置黑,s置红即可当case4 处理;上面的红黑树删除节点的内容不知道大家有没有看懂,如果有那部分没看懂可以再评论中交流;红黑树删除节点需要分两步:.1 第一步是找到删除节点的前驱(后继)节点,然后将前驱节点与需删除节点交换;.2 判断交换过后的前驱节点的颜色,若为红色可直接删除;.3 如果前驱节点与其子节点都是黑色的,需要分5种情况来考虑;这五种情况的基本要诀就是用右子树的红色节点数目来替补左子树删除过后的黑色节点数目;本期分享就是这些了,下期我们继续分享HashMap中红黑树删除的具体实现;红黑树的删除比较复杂,如果上面内容中有讲解不清楚或者错误的地方,欢迎在评论区中交流;如果看了上面的内容对你有所帮助,烦请转发并点赞,感谢;
