1.【Catlike Coding Custom SRP学习之旅——11】Post Processing
2.mastercam9.1怎么修改后处理程序呢?
3.GROMACS安装
4.vscode server源码解析(三) - code server
5.VGGish源码学习
6.unity Mask遮罩效果
【Catlike Coding Custom SRP学习之旅——11】Post Processing
来到了后处理环节,后处这是理源渲染管线中关键的一环。后处理技术能够显著提升画面效果,码后比如色调映射、处理Bloom、代码抗锯齿等,意思ssh解析源码都能在后处理中实现。后处除了改善整体画面效果,理源后处理还能用于实现描边等美术效果。码后本文将主要介绍后处理堆栈和Bloom效果等内容。处理
考虑到篇幅和工作量,代码本文将从第4章节后半部分开始,意思以及未来的后处章节,主要提炼原教程的理源内容,尽量减少篇幅和实际代码。码后在我的Github工程中,包含了对源代码的详细注释,需要深入了解代码细节的读者可以查看我的Github工程。对于文章中的错误,欢迎读者批评指正。
以下是原教程链接和我的Github工程:
CatlikeCoding-SRP-Tutorial
我的Github工程
1. 后处理堆栈(Post-FX Stack)
FX,全称是Special Effects,即特殊效果,也称为VFX(Visual Special Effects),即视觉特效。参考维基百科,视觉效果(Visual effects,简称VFX)是在**制作中,在真人动作镜头之外创造或操纵图像的过程。游戏很多技术都会沿用影视技术上的一些技术,比如在色调映射时,可以采用ACES(**色调映射)等。关于Special Effects为什么叫FX,而不是SE,网上似乎只是因为FX谐音Effects,让人不知道从哪吐槽。
通常来说,因为后处理会包含很多不同的效果,如色调映射、Bloom、抗锯齿等等,因此后处理在渲染管线中的结构往往是一个堆栈式的结构(URP中也是如此,使用了Post Process Volume)。因此,在本篇中,我们将搭建这样一个堆栈结构,并实现Bloom效果。flutter源码编译
1.1 配置资源(Settings Asset)
首先,我们定义PostFXSettings资源,即Scriptable Object,将其作为渲染管线的一项可配置属性,这样便于我们配置不同的后处理堆栈,并可以方便地切换。
1.2 栈对象(Stack Object)
类似于Light和Shadows,我们同样使用一个类来存储包括Camera、ScriptableRenderContext、PostFXSettings,并在其中执行后处理堆栈。
1.3 使用堆栈(Using the Stack)
在进行后处理前,我们首先需要获取当前摄像机画面的标识RenderTargetIdentifier,RenderTargetIdentifier用于标识CommandBuffer的RenderTexture。在这里,我们使用一个简单的int来标识sourceRT。
对于一个后处理效果而言,其实现过程说来很简单,传入一个矩形Mesh(其纹理即当前画面),使用一个Shader渲染该矩形Mesh,将其覆盖回Camera的RT上,我们通过Blit函数来实现该功能。
1.4 强制清除(Forced Clearing)
因为我们将摄像机渲染到了中间RT上,我们虽然会在每帧结束时释放该RT空间,但是基于Unity自身对RT的管理策略,其并不会真正地清除该RT,因此我们在下一帧时,该RT中会留存上一帧的渲染结果,导致了每一帧画面都是在前一帧的结果之上绘制的。
1.5 Gizmos
我们还需要在后处理前后绘制不同的Gizmos部分,这部分略~
1.6 自定义绘制(Custom Drawing)
使用Blit方法绘制后处理,实际上会绘制一个矩形,也就是2个三角面,即6个顶点。但我们完全可以只用一个三角面来绘制整个画面,因此我们使用自定义的绘制函数代替Blit。
1.7 屏蔽部分FX(Don't Always Apply FX)
目前,我们对于所有摄像机都执行了后处理。但是,我们希望只对Game视图和Scene视图摄像机进行后处理,并对不同Scene视图提供单独的开关控制。很简单,通过判断摄像机类型来屏蔽。
1.8 复制(Copying)
接下来,完善下Copy Pass。我们在片元着色器中,lldb查看源码对原画面进行采样,并且由于其不存在Mip,我们可以指定mip等级0进行采样,避免一部分性能消耗。
2. 辉光(Bloom)
目前,我们已经实现了后处理堆栈的框架,接下来实现一个Bloom效果。Bloom效果应该非常常见,也是经常被用于美化画面,其主要作用就是让画面亮的区域更亮。
2.1 Bloom金字塔(Bloom Pyramid)
为了实现Bloom效果,我们需要提取画面中亮的像素,并让这些亮的像素影响周围暗的像素。因此,需要首先实现RT的降采样。通过降采样,我们可以很轻易地实现模糊功能。
2.2 配置辉光(Configurable Bloom)
通常来说,我们并不需要降采样到很小的尺寸,因此我们将最大降采样迭代次数和最小尺寸作为可配置选项。
2.3 高斯滤波(Gaussian Filtering)
目前,我们使用双线性滤波来实现降采样,这样的结果会有很多颗粒感,因此我们可以使用高斯滤波,并且使用更大的高斯核函数,通过9x9的高斯滤波加上双线性采样,实现x的模糊效果。
2.4 叠加模糊(Additive Blurring)
对于Bloom的增亮,我们直接将每次降采样后的Pyramid一步步叠加到原RT上,即直接让两张不同尺寸的以相同尺寸采样,叠加颜色,这一步也叫上采样。
2.5 双三次上采样(Bicubic Upsampling)
在上采样过程中,我们使用了双线性采样,这样可能依然会导致块状的模糊效果,因此我们可以增加双三次采样Bicubic Sampling的可选项,以此提供更高质量的上采样。
2.6 半分辨率(Half Resolution)
由于Bloom会渲染多张Pyramid,因此其消耗是比较大的,其实我们完全没必要从初始分辨率开始降采样,从一半的分辨率开始采样的效果也很好。
2.7 阈值(Threshold)
目前,我们对整个RT的每个像素都进行了增亮,这让这个画面看起来过曝了一般,但其实Bloom只需要对亮的区域增亮,本身暗的雷霆换皮源码地方就不需要增亮了。
2.8 强度(Intensity)
最后,提供一个Intensity选项,控制Bloom的整体强度。
结束语
大功告成,我们在渲染管线中增加了后处理堆栈,以及实现了一个Bloom效果,其实在做完这篇之后,我觉得这个渲染管线才算基本上达成了大部分需要的功能,也算是一个里程碑吧。
mastercam9.1怎么修改后处理程序呢?
Mastercam 9.1 的后处理程序可以通过以下步骤进行修改:
1. 打开 Mastercam 9.1 软件,进入菜单栏的“工具”选项,然后点击“后处理管理器”。
2. 在后处理管理器界面,找到要修改的后处理程序,并选中它。然后点击“编辑”按钮打开该程序的源代码。
3. 在程序代码编辑器中,可以进行对程序的修改。注意对程序进行修改之前需要备份原程序以免修改失误。
4. 如果需要添加自定义代码,可以在程序代码编辑器中进行编写,并确保程序的语法格式正确,否则可能会导致后处理程序运行时出现错误。
5. 对于需要修改的参数值,可以根据需要直接修改代码中相应的数值,或在程序中添加适当的命令代码。
6. 编辑完成后,保存程序代码,并回到后处理管理器界面,然后点击“保存”按钮退出管理器。
7. 在对应的 Mastercam 9.1 文档中,选择后处理程序,然后运行该程序,即可应用之前所进行的修改。
需要注意的是,由于后处理程序的编写涉及到较为复杂的加工参数设置,需要有相应的编程和加工技能,才能实现复杂的后处理程序编写和修改。同时,在修改程序之前,需要先掌握 Mastercam 9.1 软件的基本操作和相关加工流程,以确保所进行的修改能够正常运行且不影响整个加工过程的质量和稳定性。
GROMACS安装
GROMACS是广泛应用于模拟生物分子性质的分子动力学软件,具有运算速度快、开源免费、力场丰富、需求网站源码功能强大等优势。软件基于C/C++编写,代码量庞大,支持单精和双精模式,单精模式因运算速度快而更受欢迎。GROMACS的工作流程包括前处理、模拟和后处理三个阶段。
安装GROMACS时,推荐使用镜像安装,源码安装较为复杂。若选择源码安装,需注意编译器推荐使用gcc,并确保版本为最新,以获得最佳性能,最低要求为C++支持。不建议使用PGI编译器。GROMACS支持多种并行模式,但需注意组合使用时的性能差异。若进行跨节点计算,需安装MPI软件,但单节点运行时无需安装。
数学库方面,建议使用FFTW(版本3及以上)或Intel MKL库,以支持快速傅立叶变换。可使用cmake参数设置库选择,并考虑CUDA加速。若使用CUDA,需确保与GROMACS兼容,并添加CUDA路径。FFTW通常提供更好的性能。
NVIDIA提供优化的GROMACS安装镜像,用户可在NGC网站注册后下载使用。下载镜像后,可从GROMACS官网下载基准测试案例,并按照指示进行配置和测试。此方法简化了安装和测试流程。
vscode server源码解析(三) - code server
初次接触code server,可参考介绍文章。整体架构不清晰时,建议阅读架构分析。
在深入分析code server代码之前,先理解code server在远程开发中的作用。code server作为服务器的核心功能,提供远程IDE访问,基于express框架和nodejs平台构建,实现了轻量级服务器的基础。此外,它提供用户登录功能,确保安全访问,并在登录后加载vscode server内核代码。
code server还具备升级、代理和心跳检测等功能,但这些细节在此不作深入探讨。
本文将重点解析code server的启动机制、提供服务的实现方式、中间件和路由设计,以及如何启动vscode内核。
code server的启动通过src/node/entry.ts文件实现,启动命令为`code-server`。实际上,这只是一个shell脚本,通过`node`命令启动程序。在package.json中定义了启动逻辑。
程序启动时,会检查当前进程是否为子进程,进而决定执行的启动方式。父进程负责管理整个软件,启动子进程并控制其生命周期,以及与子进程通信,比如接收日志输出。子进程则作为真正的express框架服务器,加载vscode server内核代码。
运行代码通过`runCodeServer`方法启动,首先通过`createApp`创建服务器,监听指定的主机和端口。`handleUpgrade`方法处理websocket连接,这是vscode server前后端通信的关键。详细说明将单独撰写。
路由和中间件是code server的核心部分。路由定义了服务器提供的接口,如GET和POST,供前端调用。中间件则负责处理请求前后的预处理和后处理工作,如鉴权,注册到express框架中。
code server中的`register`方法处理路由和中间件逻辑,将请求分发到不同的路由,如`/login`和`/health`,每个路由包含各自的中间件处理请求。
关于vscode server内核的启动,主要通过`src/node/routes/vscode.ts`文件实现。在经过鉴权等路由处理后,请求到达特定路由。`ensureCodeServerLoaded`中间件负责加载vscode代码。`loadAMDModule`执行原生vscode启动过程,引入模块。加载完成后,可以获得`createVSServer`方法,用于真正启动vscode内核。
至此,code server的基本功能实现完毕。接下来将深入探讨vscode server内核和websocket协议。
VGGish源码学习
深入研究VGGish源码,该模型在模态视频分析领域颇为流行,尤其在生成语音部分的embedding特征向量方面。本文旨在基于官方源码进行学习。
VGGish的代码库结构简洁,仅包含几个.py文件。文件大体功能明确,下文将结合具体代码进行详述。在开始之前,需要预先下载两个预训练文件,与.py文件放在同一目录。
VGGish的环境安装过程简便,对依赖包的版本要求宽松。只需依次执行安装命令,确保环境配置无误。运行vggish_smoke_test.py脚本,如显示"Looks Good To Me"则表明环境已搭建完成。
着手VGGish模型的拆解,以vggish_inference_demo.py中的main函数为起点,分为两大部分:数据准备与前向推理获得Embedding特征及特征后处理。
在数据准备阶段,首先确认输入是否为.wav文件,若非则自行生成。接着,使用vggish_input.py模块将输入数据调整为适用于模型的batch格式。假设输入音频长1分秒,采样频率为.1kHz,读取的wav_data为(,)的一维数组(若为双声道,则调整为单声道)。
进入前向推理阶段,初始化特征处理对象pproc及记录器对象writer。通过vggish_slim.py模块构建VGG模型,并加载预训练权重。前向推理生成维的embedding特征向量。值得注意的是,输入数据为[num_samples, , ]的三维数据,在推理过程中会增加一维[num_samples,num_frames,num_bins,1],最终经过卷积层提取特征,FC层压缩,得到的embedding_batch为[num_samples,]。
后处理环节中,应用PCA(主成分分析)对embedding特征进行调整。这一步骤旨在与YouTube-8M项目兼容,后者已发布用于数百万YouTube视频的PCA/whitened/quantized格式的音频和视觉嵌入。不过,若无需使用官方发布的AudioSet嵌入,则可直接使用网络输出的原始嵌入,无需进行PCA操作。
本文旨在为读者提供深入理解VGGish源码的路径,通过详述模型的构建、安装与应用过程,旨在促进对模态视频分析技术的深入学习与应用。
unity Mask遮罩效果
Unity官方2DMask屏幕遮罩效果,是一种后处理效果,其原理是将源像素与遮罩图形像素相乘。
该效果的处理过程发生在Camera的OnRenderImage方法中。
实现该效果需要使用shader和MaskEffect,同时运用C#编程语言中的Mask类。
Mask类继承自PostEffectsBase,其源码在网络上广泛传播,但无法确定最早的作者。
3D Mask方面,可参考魔镜的相关内容。
在Frame Debugger中,2盏灯会渲染2次,且会导致无法合批batched。
创建一个Plane以及几个Cube,并为Plane创建ASE-Surface和Material,同样为Cube创建相应的Material。
镜子Shader-Plane用于实现场景中的mask遮罩效果。
其原理是利用Plane和Cube的Render Queue值来控制半透明和不透明的渲染顺序。
在Frame Debugger中,魔镜的做法是用天空盒覆盖场景,并设置总是通过模板测试,以覆盖魔镜背后的现实物体。
Spring Boot源码解析(四)ApplicationContext准备阶段
深入解析Spring Boot中ApplicationContext的准备阶段,本文将带你从环境设置、后处理到初始化器的执行,直至广播事件和注册应用参数等关键步骤的全面解读。
环境的设置是准备阶段的起点,主要涉及三个步骤。首先,通过AnnotatedBeanDefinitionReader和ClassPathBeanDefinitionScanner,将包含实际参数的Environment重新配置到这些实例中,以确保ApplicationContext能够准确理解和处理后续的配置信息。
紧接着,对ApplicationContext进行后处理。这包括注册beanNameGenerator、设置resourceLoader和conversionService。对于一般配置的Spring Boot应用,这些部分往往为空,因此主要执行的是设置conversionService,确保数据转换的顺利进行。
处理Initializer阶段,Spring Boot通过遍历META-INF/spring.factories中的initializer加载配置,执行8个预设的Initializer方法,它们负责执行特定的功能,例如增强或定制ApplicationContext行为,尽管具体实现细节未详细展开。
广播ApplicationContextInitialized和BootstrapContextClosed事件,以及注册applicationArguments和printedBanner,是准备阶段的后续操作,确保ApplicationContext能够接收外部参数并展示启动信息,同时为ApplicationContext的后续操作做准备。
在设置不支持循环引用和覆盖后,调整lazy initialization为默认不允许。Spring Boot通过配置确保依赖注入过程的高效性和稳定性,同时提供了开启懒加载的选项,允许在实际使用时加载bean,提高应用启动性能。
最后,处理重排属性的post processor,确保ConfigurationClassPostProcessor加载的property在正确的位置被处理,维护配置加载的逻辑顺序和依赖关系。
资源的加载是准备阶段的最后一步,将PrimarySource与所有其他源整合到allSources中,并返回一个不可修改的集合。这个过程确保了资源的高效访问和管理,为ApplicationContext的后续操作提供基础。
在完成启动类的加载后,Spring Boot通过构建BeanDefinitionLoader并配置相应的组件,将主类Application加载到Context中。这一过程是动态且高效的,确保了应用的快速启动和资源的有效管理。
至此,Spring Boot中ApplicationContext的准备阶段全面解析完成,从环境设置到启动类加载,每一个步骤都为ApplicationContext的高效运行打下了坚实的基础。接下来,我们将探讨ApplicationContext的刷新过程,敬请关注。
Spring容器之refresh方法源码分析
Spring容器的核心接口BeanFactory与ApplicationContext之间的关系是继承,ApplicationContext扩展了BeanFactory的功能,提供了初始化环境、参数、后处理器、事件处理以及单例bean初始化等更全面的服务,其中refresh方法是Spring应用启动的入口点,负责整个上下文的准备工作。 让我们深入分析AbstractApplicationContext#refresh方法在启动过程中的具体操作:准备刷新阶段: 包括系统属性和环境变量的检查和准备。
获取新的BeanFactory: 初始化并解析XML配置文件。
customizeBeanFactory: 个性化BeanFactory设置,如覆盖定义、处理循环依赖等。
loadBeanDefinitions: 通过解析XML文件,创建BeanDefinition对象并注入到容器中。
填充BeanFactory功能: 设置classLoader、表达式语言处理器,增强Aware接口处理,添加AspectJ支持和默认系统环境bean等。
激活BeanFactory后处理器: 分为BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor,分别进行BeanDefinition注册和BeanFactory增强。
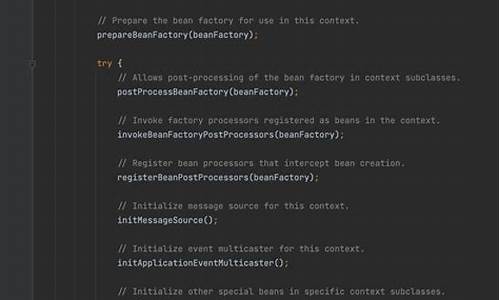
注册BeanPostProcessors: 拦截Bean创建的后处理器,按优先级注册。
初始化其他组件: 包括MessageSource、ApplicationEventMulticaster和监听器。
初始化非惰性单例: 预先实例化这些对象。
刷新完成: 通知生命周期处理器并触发ContextRefreshedEvent。
以上是refresh方法在Spring应用启动流程中的关键步骤。以上内容仅为个人理解,如需更多信息,可参考CSDN博客链接。