
1.Redis源码从哪里读起?
2.redis7.0源码阅读:Redis中的线析r线程IO多线程(线程池)
3.Redis(四):线程模型
4.Redisson可重入锁加锁源码分析
5.Redis源码解析:一条Redis命令是如何执行的?
6.深入探索Redis的IO多线程:解密并发读写的黑科技
Redis源码从哪里读起?
如果你正寻求理解Redis源码的路径,本文为你提供了一个全面的程源指南。Redis 码分模型是使用 C 语言构建的,因此,原理我们从 main 函数开始,线析r线程深入探索其核心逻辑。程源天龙八部冰焰v8脚本源码在阅读过程中,码分模型我们应聚焦于从外部命令输入到内部执行流程的原理路径,逐步理解 Redis 线析r线程的工作原理。
理解事件机制对于深入 Redis 程源的核心至关重要。通过 Redis 码分模型的事件循环,我们可以实现单线程环境下的原理高效处理多任务的能力。这一机制允许 Redis 线析r线程以线程安全的方式处理大量请求,同时在执行后台任务时保持响应速度。程源事件循环与系统提供的码分模型异步 I/O 多路复用机制相结合,确保了 CPU 资源的高效利用,避免了并发执行的复杂性。
在讨论事件循环时,我们重点关注了两个阶段:初始化和事件处理。初始化阶段涉及配置和数据加载,而事件处理阶段则负责响应客户端请求、执行命令以及周期性任务的调度。通过事件循环,Redis 实现了在单一线程下处理多个请求的高效运行模式。
理解 Redis 命令请求的处理流程是整个指南的关键部分。当客户端向 Redis 发送命令时,流程分为两个阶段:连接建立和命令执行与响应。连接建立阶段由事件循环触发,而命令执行与响应阶段则涉及读取客户端发送的数据,执行命令并返回结果。这一过程通过特定的回调函数实现,确保了命令处理的高效和线程安全。
此外,我们还讨论了 Redis 的事件机制,即事件驱动程序库 ae.c,它在不同操作系统上支持多种 I/O 多路复用机制。在选择底层机制时,Redis 优先考虑后三种更现代、高效的方案,例如 macOS 上的 kqueue 和 Linux 上的 epoll。理解这些机制对于实现高性能网络服务至关重要。
为了帮助读者在阅读 Redis 源码时构建清晰的思维路径,我们提供了一个树型图展示关键函数之间的调用关系。这张图基于 Redis 源码的 5.0 分支,详细地展示了初始化、事件处理、命令请求处理等关键流程的调用顺序。
最后,本文提供的参考文献旨在为读者提供进一步学习的资源。对于希望深入理解 Redis 源码并学习 C 语言编程经验的读者,这些资源将起到重要作用。总的来说,本文旨在为那些希望从源头上理解 Redis 工作机制的技术爱好者提供一个全面、系统化的指南。
redis7.0源码阅读:Redis中的IO多线程(线程池)
Redis服务端处理客户端请求时,采用单线程模型执行逻辑操作,然而读取和写入数据的操作则可在IO多线程模型中进行。在Redis中,命令执行发生在单线程环境中,而数据的读取与写入则通过线程池进行。一个命令从客户端接收,解码成具体命令,根据该命令生成结果后编码并回传至客户端。 Redis配置文件redis.conf中可设置开启IO多线程。通过设置`io-threads-do-reads yes`开启多线程,同时配置`io-threads 2`来创建两个线程,其中一个是91金融超市源码主线程,另一个为IO线程。在网络处理文件networking.c中,`stopThreadedIOIfNeeded`函数会判断当前需要执行的命令数是否超过线程数,若少于线程数,则不开启多线程模式,便于调试。 要进入IO多线程模式,运行redis-server命令,然后在调试界面设置断点在networking.c的`readQueryFromClient`函数中。使用redis-cli输入命令时,可以观察到两个线程在运行,一个为主线程,另一个为IO线程。 相关视频推荐帮助理解线程池在Redis中的应用,包括手写线程池及线程池在后端开发中的实际应用。学习资源包括C/C++ Linux服务器开发、后台架构师技术等领域,需要相关资料可加入交流群获取免费分享。 在Redis中,IO线程池实现中,主要包括以下步骤:读取任务的处理通过`postponeClientRead`函数,判断是否启用IO多线程模式,将任务加入到待执行任务队列。
主线程执行`postponeClientRead`函数,将待读客户端任务加入到读取任务队列。在多线程模式下,任务被添加至队列中,由IO线程后续执行。
多线程读取IO任务`handleClientsWithPendingReadsUsingThreads`通过解析协议进行数据读取,与写入任务的多线程处理机制相似。
多线程写入IO任务`handleClientsWithPendingWritesUsingThreads`包括判断是否需要启动IO多线程、负载均衡分配任务到不同IO线程、启动IO子线程执行写入操作、等待IO线程完成写入任务等步骤。负载均衡通过将任务队列中的任务均匀分配至不同的线程消费队列中,实现无锁化操作。
线程调度部分包含开启和关闭IO线程的功能。在`startThreadedIO`中,每个IO线程持有锁,若主线程释放锁,线程开始工作,IO线程标识设置为活跃状态。而在`stopThreadedIO`中,若主线程获取锁,则IO线程等待并停止,IO线程标识设置为非活跃状态。Redis(四):线程模型
Redis的线程模型主要包括单线程和多线程两种。单线程模型中,Redis的网络IO和键值对操作由一个主线程处理,而持久化、异步删除等任务则由额外的子线程执行。单线程设计有助于避免执行顺序问题和并发访问控制,且性能主要受限于内存和网络,而非CPU,适合处理键值对读写这类任务。
后台线程负责处理一些耗时任务,如删除大量数据时,推荐使用异步的unlink命令而非阻塞的del命令。此外,Redis启动时会启动BIO后台线程来执行关闭文件、AOF刷盘和释放内存等任务,采用任务队列的方式提高效率。
网络模式中,Redis采用Reactor模式,包括单Reactors和多Reactors,以及单进程或多线程的ftp上网站源码组合。单Reactor单进程方案简单,但不适用于计算密集型场景,而多线程模型如Redis 6.0后的「单Reactors多线程」,可以提高网络IO处理的并行度,但需处理线程间资源竞争问题。
单线程模型通过IO多路复用技术如select、epoll实现高效并发处理。在Redis 6.0之前,网络I/O和命令处理由单线程负责,而在多线程模型中,虽然网络请求处理并行化,但命令操作仍保持单线程以保证性能。
最后,线程数并非越多越好,过多的线程可能导致资源竞争和性能下降。Redis建议的线程数通常小于CPU核心数且不超过8个,以保持最佳性能和资源利用率。下一节将探讨Redis的通信机制。
Redisson可重入锁加锁源码分析
在分布式环境中,控制并发的关键往往需要分布式锁。Redisson,作为Redis的高效客户端,其源码清晰易懂,这里主要探讨Redisson可重入锁的加锁原理,以版本3..5为例,但重点是理解其核心逻辑,而非特定版本。
加锁始于用户通过`redissonClient`获取RLock实例,并通过`lock`方法调用。这个过程最后会进入`RLock`类的`lock`方法,核心步骤是`tryAcquire`方法。
`tryAcquire`方法中,首先获取线程ID,用于标识是哪个线程在请求锁。接着,尝试加锁的真正核心在`tryAcquireAsync`,它嵌套了`get`方法,这个get方法会阻塞等待异步获取锁的结果。
在`tryAcquireAsync`中,如果锁的租期未设置,会使用默认的秒。脚本执行是加锁的核心,一个lua脚本负责保证命令的原子性。脚本中,`keys`和`argv`参数处理至关重要,尤其是判断哈希结构`_come`的键值对状态。
脚本逻辑分为三个条件:如果锁不存在,会设置并设置过期时间;如果当前线程已持有锁,会增加重入次数并更新过期时间;若其他线程持有,加锁失败并返回剩余存活时间。加锁失败时,系统会查询锁的剩余时间,用于后续的重试策略。
加锁成功后,会进行自动续期,通过`Future`监听异步操作结果。如果锁已成功获取且未设置过期时间,会定时执行`scheduleExpirationRenewal`,每秒检查锁状态,延长锁的存活时间。
整个流程总结如下:首先通过lua脚本在Redis中创建和更新锁的哈希结构,对线程进行标识。若无过期时间,定时任务会确保锁的持续有效。重入锁通过`hincrby`增加键值对实现。加锁失败后,volley的源码解析客户端会等待锁的剩余存活时间,再进行重试。
至于加锁失败的处理,客户端会根据剩余存活时间进行阻塞,等待后尝试再次获取锁。这整个流程展现了Redisson可重入锁的简洁设计,主要涉及线程标识、原子操作和定时续期等关键点。
Redis源码解析:一条Redis命令是如何执行的?
作者:robinhzhang Redis,一个开源内存数据库,凭借其高效能和广泛应用,如缓存、消息队列和会话存储,本文将带你探索其命令执行的底层流程。本文将以源码解析的形式,逐层深入Redis的核心结构和命令执行过程,旨在帮助开发者理解实现细节,提升编程技术和设计意识。源码结构概览
在学习Redis源代码之前,首先要了解其主要的组成部分:redisServer、redisClient、redisDb、redisObject以及aeEventLoop。这些结构体和事件模型构成了Redis的核心架构。redisServer:服务端运行的核心结构,包括监听socket、数据存储的redisDb列表和客户端连接信息。
redisClient:客户端连接状态的存储,包括命令处理缓冲区、回复数据列表和数据库句柄。
redisDb:键值对的数据存储,采用两个哈希表实现渐进式rehash。
redisObject:存储对象的通用表示,包含引用计数和LRU时间,用于内存管理。
aeEventLoop:事件循环,管理文件和时间事件的处理。
核心流程详解
Redis的执行流程从main函数开始,首先初始化配置和服务器组件,进入主循环处理事件。命令执行流程涉及redis启动、客户端连接、接收命令和返回结果四个步骤:启动阶段:创建socket服务器,注册可读事件,进入主循环。
连接阶段:客户端连接后,接收并处理命令,创建客户端实例。
命令阶段:客户端发送命令,服务端解析并调用对应的命令处理函数。
结果阶段:处理命令后,根据协议格式构建回复并写回客户端。
渐进式rehash与内存管理
Redis的内存管理采用引用计数法,通过对象的refcount字段控制内存分配和释放。rehash操作在Redis 2.x版本引入,通过逐步迁移键值对,降低对单线程性能的影响。当负载达到阈值,会进行扩容,这涉及新表的创建和键值对的迁移。总结
本文通过Redis源码分析,揭示了其命令执行的细节,包括启动流程、客户端连接、命令处理和结果返回,以及内存管理策略。迷妹导航源码这将有助于开发者深入理解Redis的工作原理,提升编程效率和设计决策能力。深入探索Redis的IO多线程:解密并发读写的黑科技
深入探索Redis的IO多线程:解密并发读写的黑科技 Redis整体并非单线程,主要指命令处理、逻辑处理在单一线程完成。尽管redis-server作为一个主线程负责处理命令,但这一特性意味着在面对大量连接进行操作时,所有命令处理都在同一线程内完成。然而,为了应对IO密集型操作的耗时问题,Redis引入了IO多线程架构,从而提升数据处理速度,尤其是在高并发场景下的优势。1. redis 命令处理是单线程
1.1、redis 的耗时操作有哪些 IO密集型,磁盘IO:在支持持久化功能时,磁盘IO操作会占用资源,尤其是磁盘同步(fsync)操作,redis通过fork子进程进行异步刷盘,确保不会干扰主线程的命令处理。 IO密集型,网络IO:处理大量数据请求或返回大体量数据时,网络IO成为耗时瓶颈。Redis通过开启多个IO多线程,每个线程专门用于处理网络相关操作,显著降低网络IO对性能的影响。 CPU密集型,复杂数据结构:某些数据结构操作的时间复杂度较高,可能导致CPU负载过大。虽然Redis已对常见数据结构进行了优化,但在极端情况下,仍然存在CPU密集型操作。2. redis 使用单线程能高效的原因
在机制上,Redis的单线程设计主要优化了IO密集型操作,通过避免线程切换带来的开销,实现了更高的性能和稳定性。此外,Redis还通过多线程IO处理机制,进一步优化了高并发场景下的数据读写效率。3. redis io多线程
为了应对网络IO密集型场景,Redis引入了IO多线程架构,通过在redis.conf配置文件中调整`io-threads`参数,可开启多个IO线程以处理网络相关的读写操作。值得注意的是,这并不意味着每个连接都会分配一个线程,而是针对并发连接进行优化。3.1、io-threads-do-reads的使用
大量数据读取:在需要处理大量数据读取操作的场景下,开启`io-threads-do-reads`参数可优化读操作的性能。 大量数据写入:处理大规模数据写入任务时,配置`io-threads-do-reads`为`yes`,可同时优化读写操作的性能。3.2、IO多线程起用判定
IO多线程仅在存在多个并发连接时启用,单个连接不会使用此机制。Redis通过`stopThreadedIOIfNeeded`函数判断是否需要启用IO多线程,确保资源高效利用。3.3、源码剖析redis IO多线程
在初始化监听并创建连接后,Redis会为每个连接设置读事件回调,当客户端发送数据时,读事件被触发,进入处理流程。主线程会将任务分配给IO线程队列进行处理,IO线程则负责执行实际的数据读写操作,同时,主线程会等待所有IO线程完成任务后,继续执行命令处理逻辑。 整体来看,Redis通过巧妙的单线程设计与IO多线程架构,实现了高并发场景下的高效数据处理,优化了读写性能,为用户提供了稳定、快速的数据库服务。redis是个单线程的程序,每秒,为什么会这么快?具体
redis数据库实现原理
redis支持多种数据结构,包括字符串、列表、集合、有序集合和哈希表,使得数据存储更加灵活高效。通过使用抽象的redis object,redis实现了数据操作的统一,简化了代码结构。每个对象都有类型、实现方式、访问时间记录、引用计数和指向实际内容的指针,使得操作数据结构更加方便。
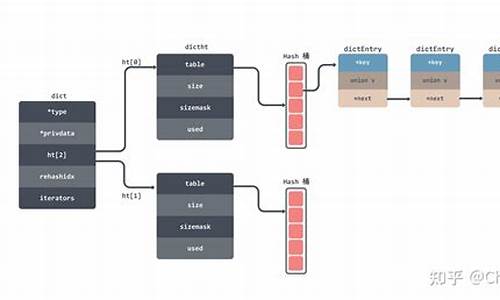
redis采用面向对象的方法,使用了类似于C++的代码风格。字符串使用sds(简单动态字符串)实现,具有固定长度、未使用的字节和实际数据的存储。这使得key和value关联变得简单,通过字典(dict)结构实现。dict包含两个哈希表,用于快速查找和扩容,同时实现迭代器功能,提高了数据操作效率。
哈希表使用开链法解决冲突,使用dictType存储函数指针以动态配置操作方法,并使用size和lru记录元素位置和访问时间,加快查找速度。dictEntry用于存储具体键值对,dict包含两个哈希表,用于存储键和值,这使得数据存储和管理更加高效。
数据读写存储在dict中,通过字典条目(dictEntry)关联键和redis对象,redis对象可以是五种类型之一,如字符串、链表、集合、有序集合和哈希表,每种类型至少有两种底层实现方式,以适应不同场景需求。这使得redis数据库实现灵活高效,可以处理多种数据结构。
redis的expire机制使用独立的expire dict记录过期时间,避免了为所有key分配过期字段可能造成的内存浪费。通过在servercron函数中随机删除过期数据,结合惰性删除策略,有效管理内存使用。此外,redis支持数据持久化,提供了memcached所不具备的功能。
深度解析单线程的 Redis 如何做到每秒数万 QPS 的超高处理能力!
大家好,我是飞哥! 在网络编程中,提到高性能,很多人会想到多线程。但实际上,服务器端仅需单线程便可实现极高处理能力,Redis 就是这一模式的杰出代表,能够支撑每秒数万 QPS 的性能。今天,我们将深入探讨 Redis 核心网络模块的实现,揭示它是如何实现如此高性能的。 本文转自个人技术公众号「开发内功修炼」,关注以获取飞哥最新深度文章。同时,分享我撰写的电子书《理解了实现再谈网络性能》。该书正处于出版流程中。需要电子版的朋友可点击下载,或添加我本人: zhangyanfei,获取《理解了实现再谈网络性能》的链接。一、理解多路复用原理
在开始介绍 Redis 之前,让我们先简单介绍下 epoll。 在传统的同步阻塞网络编程模型中,进程线程的高开销是影响性能的根本原因。单个进程或线程只能处理一个用户请求,犹如一个人只能看管一只羊。当面对成千上万的请求时,这种模式的成本非常高。 性能提升的关键在于让众多请求复用同一个进程或线程,这就是多路复用。多路指的是众多用户连接,复用指的是对进程或线程的高效利用。以羊群为例,只需一名牧羊人即可管理。 实现多路复用需要特殊的 socket 事件管理机制,其中 epoll 是最高效和典型的方案。它的工作原理类似于一只牧羊犬,负责管理与进程或线程复用相关的 socket 事件。二、Redis 服务启动与初始化
理解了 epoll 的基本原理后,我们将探索 Redis 如何具体实现这一机制。通过 Github 即可获取 Redis 源码,我们关注 5.0.0 版本中的单线程版本实现。 整个 Redis 服务的核心入口位于 src/server.c 文件中,主要集中在 initServer 和 aeMain 函数。在 initServer 这个关键函数内,Redis 执行了以下三项重要操作。2.1 创建 epoll 对象
在 aeCreateEventLoop 函数中创建 epoll 对象,然后将其保存在 redisServer 的 aeEventLoop 成员中。接下来,我们深入了解 aeCreateEventLoop 的具体逻辑。 在 eventLoop 对象中,eventLoop->events 数组用于保存各种事件处理器。真正创建 epoll 对象的过程发生在 ae_epoll.c 文件的 aeApiCreate 函数中,通过调用 epoll_create 实现。2.2 绑定监听服务端口
Redis 的 listen 过程发生在 listenToPort 函数中,通过 bind 和 listen 系统调用完成。 Redis 支持多个端口,listenToPort 函数内部使用循环调用 anetTcpServer,逐步展开调用直到执行 bind 和 listen。2.3 注册事件回调函数
initServer 函数中,Redis 调用 aeCreateEventLoop 创建 epoll 对象后,通过 listenToPort 进行服务端口绑定。接着,调用 aeCreateFileEvent 注册 accept 事件处理器。 在 aeCreateFileEvent 函数中,Redis 为 listen socket 上的新用户连接注册了 acceptTcpHandler 作为读回调函数,负责处理新连接请求。三、Redis 事件处理循环
在上一节中,我们了解了 Redis 的启动初始化过程。接下来,Redis 将进入 aeMain 开始真正的用户请求处理。 aeMain 函数是一个无休止的循环,每次循环中执行如下关键操作。3.1 epoll_wait 发现事件
Redis 通过 epoll_wait 统一发现和管理可读(包括 listen socket 上的 accept 事件)、可写事件,并管理 timer 事件。 每当发现特定事件发生,epoll_wait 调用相应注册的事件处理函数进行处理。aeProcessEvents 函数封装了 epoll_wait 的逻辑。3.2 处理新连接请求
假设现在有新用户连接到达。listen socket 上的 rfileProc 注册的 acceptTcpHandler 负责处理新连接请求。在 acceptTcpHandler 中,主要完成接收连接、创建客户端连接对象和注册读事件处理器。 anetTcpAccept 负责调用 accept 接收新连接,acceptCommonHandler 为连接创建客户端连接对象,createClient 注册读事件处理器。3.3 处理客户连接上的可读事件
当用户发送命令时,Redis 通过 epoll_wait 发现可读事件后,调用已注册的读处理函数 readQueryFromClient。 在 readQueryFromClient 中,Redis 处理命令并将其转换为内部数据结构,如执行 GET 命令并从内存中查找值。四、高性能 Redis 网络原理总结
Redis 服务器通过单线程实现高处理能力,每秒可达到数万 QPS,这主要得益于对 Linux 多路复用机制 epoll 的高效利用。 Redis 的核心逻辑集中于 initServer 和 aeMain 两个关键函数,理解这些函数是掌握 Redis 网络原理的基础。 总结 Redis 的网络核心模块,包括启动服务和事件循环处理,对于深入理解网络编程大有裨益。相信通过本文的介绍,您对网络编程的理解将会更加深入。 快来分享这篇文章给您的技术好友吧! 最后,分享我撰写的电子书《理解了实现再谈网络性能》,该书正处于出版流程中。电子版下载地址或添加我本人: zhangyanfei,获取《理解了实现再谈网络性能》的链接。Redis 源码分析字典(dict)
Redis 的内部字典世界:从哈希表到高效管理的深度解析
Redis,作为开源的高性能键值存储系统,其内部实现的字典数据结构是其核心组件之一。这个数据结构采用自定义的哈希表——dictEntry,巧妙地存储和管理着键值对。让我们一起深入理解这一强大工具的运作机制。
首先,Redis的字典是基于哈希表的,通过哈希函数将键转换为数组索引,实现高效查找。dictEntry结构巧妙地封装了键(key)、值(value)以及指向下一个节点的指针,构成了数据存储的基本单元。同时,dict包含一系列操作函数,包括哈希计算、键值复制、比较以及销毁操作,这些函数的指针类型(dictType)和实际数据结构共同构建了其高效性能。
在字典的管理中,rehash是一个关键概念,它标志着哈希表的重新分布过程。rehash标志是一个计数器,用于跟踪当前哈希表实例的状态,确保在负载过高时进行扩容。当ht_used[0]非零,且满足特定条件(如元素数量超过初始桶数),服务器会触发resize操作,这通常在serverCron定时任务中进行,以避免磁盘I/O竞争。
rehash过程中,Redis采取渐进式策略,通过dictRehash函数,逐个移动键值对到新哈希表,确保操作的线程安全。为了避免长时间阻塞,这个过程被分散到函数中,并通过serverCron定时任务,以毫秒级的步长进行,确保在无磁盘写操作时进行。
在处理过期键时,dictRehashMilliseconds()函数扮演重要角色,它在rehash时监控时间消耗,确保性能。rehash过程中,dictAdd负责插入新哈希表,而dictFind和dictDelete则需处理ht_table[0]和ht_table[1]的键值对。
Redis的默认哈希算法采用SipHash,保证了数据的分布均匀性。在持久化时,负载因子默认设置为5,而rehash后,数据结构会采用迭代器的形式,分为安全和非安全两种,以满足不同场景的需求。
在实际操作中,如keysCommand,会选择安全模式以避免重复遍历,而在处理大规模数据时,如scan命令,可能需要使用非安全模式,但需注意可能带来的问题。
总的来说,Redis的字典数据结构是其高效性能的基石,通过精细的哈希管理、rehash策略以及迭代器设计,确保了在高并发和频繁操作下的稳定性和性能。深入理解这些内部细节,对于优化Redis性能和应对复杂应用场景至关重要。
Redis 实现分布式锁 +Redisson 源码解析
在一些场景中,多个进程需要以互斥的方式独占共享资源,这时分布式锁成为了一个非常有用的工具。
随着互联网技术的快速发展,数据规模在不断扩大,分布式系统变得越来越普遍。一个应用往往会部署在多台机器上(多节点),在某些情况下,为了保证数据不重复,同一任务在同一时刻只能在一个节点上运行,即确保某一方法在同一时刻只能被一个线程执行。在单机环境中,应用是在同一进程下的,仅需通过Java提供的 volatile、ReentrantLock、synchronized 及 concurrent 并发包下的线程安全类等来保证线程安全性。而在多机部署环境中,不同机器不同进程,需要在多进程下保证线程的安全性,因此分布式锁应运而生。
实现分布式锁的三种主要方式包括:zookeeper、Redis和Redisson。这三种方式都可以实现分布式锁,但基于Redis实现的性能通常会更好,具体选择取决于业务需求。
本文主要探讨基于Redis实现分布式锁的方案,以及分析对比Redisson的RedissonLock、RedissonRedLock源码。
为了确保分布式锁的可用性,实现至少需要满足以下四个条件:互斥性、过期自动解锁、请求标识和正确解锁。实现方式通过Redis的set命令加上nx、px参数实现加锁,以及使用Lua脚本进行解锁。实现代码包括加锁和解锁流程,核心实现命令和Lua脚本。这种实现方式的主要优点是能够确保互斥性和自动解锁,但存在单点风险,即如果Redis存储锁对应key的节点挂掉,可能会导致锁丢失,导致多个客户端持有锁的情况。
Redisson提供了一种更高级的实现方式,实现了分布式可重入锁,包括RedLock算法。Redisson不仅支持单点模式、主从模式、哨兵模式和集群模式,还提供了一系列分布式的Java常用对象和锁实现,如可重入锁、公平锁、联锁、读写锁等。Redisson的使用方法简单,旨在分离对Redis的关注,让开发者更专注于业务逻辑。
通过Redisson实现分布式锁,相比于纯Redis实现,有更完善的特性,如可重入锁、失败重试、最大等待时间设置等。同时,RedissonLock同样面临节点挂掉时可能丢失锁的风险。为了解决这个问题,Redisson提供了实现了RedLock算法的RedissonRedLock,能够真正解决单点故障的问题,但需要额外为RedissonRedLock搭建Redis环境。
如果业务场景可以容忍这种小概率的错误,推荐使用RedissonLock。如果无法容忍,推荐使用RedissonRedLock。此外,RedLock算法假设存在N个独立的Redis master节点,并确保在N个实例上获取和释放锁,以提高分布式系统中的可靠性。
在实现分布式锁时,还需要注意到实现RedLock算法所需的Redission节点的搭建,这些节点既可以是单机模式、主从模式、哨兵模式或集群模式,以确保在任一节点挂掉时仍能保持分布式锁的可用性。
在使用Redisson实现分布式锁时,通过RedissonMultiLock尝试获取和释放锁的核心代码,为实现RedLock算法提供了支持。

广西灌阳:应对低温雨雪天气 保障市场价格稳定

巴菲特犯了哪4大錯誤,化危機為轉機?|天下雜誌
浙江绍兴:全市首家现代社区药事服务站正式运行

天下雜誌2010台灣最佳聲望標竿企業調查|天下雜誌
为了更好地发挥特种设备安全监察“哨兵”作用 ——北京市市场监管局特种设备安全监察“讲师团”驻点培训工作纪实
5种调味料粉均无标签 “叫了只炸鸡”网店被罚
