
1.Pytorch_循ç¯ç¥ç»ç½ç»RNN
2.基于keras的码解时域卷积网络(TCN)
3.9987 用Theano实现Nesterov momentum的正确姿势
4.(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
5.win10 + CUDA 9.0 + cuDNN 7.0 + tensorflow源码编译安装
6.唇语识别源代码
Pytorch_循ç¯ç¥ç»ç½ç»RNN
RNNæ¯Recurrent Neural Networksç缩åï¼å³å¾ªç¯ç¥ç»ç½ç»ï¼å®å¸¸ç¨äºè§£å³åºåé®é¢ãRNNæè®°å¿åè½ï¼é¤äºå½åè¾å ¥ï¼è¿æä¸ä¸æç¯å¢ä½ä¸ºé¢æµçä¾æ®ãå®å¸¸ç¨äºè¯é³è¯å«ãç¿»è¯çåºæ¯ä¹ä¸ãRNNæ¯åºå模åçåºç¡ï¼å°½ç®¡è½å¤ç´æ¥è°ç¨ç°æçRNNç®æ³ï¼ä½åç»çå¤æç½ç»å¾å¤æ建å¨RNNç½ç»çåºç¡ä¹ä¸ï¼å¦Attentionæ¹æ³éè¦ä½¿ç¨RNNçéèå±æ°æ®ãRNNçåç并ä¸å¤æï¼ä½ç±äºå ¶ä¸å æ¬å¾ªç¯ï¼å¾é¾ç¨è¯è¨æè ç»å¾æ¥æè¿°ï¼æ好çæ¹æ³æ¯èªå·±æå¨ç¼åä¸ä¸ªRNNç½ç»ãæ¬ç¯å°ä»ç»RNNç½ç»çåçåå ·ä½å®ç°ã
å¨å¦ä¹ 循ç¯ç¥ç»ç½ç»ä¹åï¼å ççä»ä¹æ¯åºåãåºåsequenceç®ç§°seqï¼æ¯æå å顺åºçä¸ç»æ°æ®ãèªç¶è¯è¨å¤çæ¯æä¸ºå ¸åçåºåé®é¢ï¼æ¯å¦å°ä¸å¥è¯ç¿»è¯æå¦ä¸å¥è¯æ¶ï¼å ¶ä¸æ个è¯æ±çå«ä¹ä¸ä» åå³äºå®æ¬èº«ï¼è¿ä¸å®ååçå¤ä¸ªåè¯ç¸å ³ã类似çï¼å¦ææ³é¢æµçµå½±çæ èåå±ï¼ä¸ä» ä¸å½åçç»é¢æå ³ï¼è¿ä¸å½åçä¸ç³»ååæ æå ³ãå¨ä½¿ç¨åºå模åé¢æµçè¿ç¨ä¸ï¼è¾å ¥æ¯åºåï¼èè¾åºæ¯ä¸ä¸ªæå¤ä¸ªé¢æµå¼ã
å¨ä½¿ç¨æ·±åº¦å¦ä¹ 模å解å³åºåé®é¢æ¶ï¼æ容ææ··æ·çæ¯ï¼åºåä¸åºåä¸çå ç´ ãå¨ä¸åçåºæ¯ä¸ï¼å®ä¹åºåçæ¹å¼ä¸åï¼å½åæåè¯çææ è²å½©æ¶ï¼ä¸ä¸ªåè¯æ¯ä¸ä¸ªåºåseqï¼å½åæå¥åææ è²å½©æ¶ï¼ä¸ä¸ªå¥åæ¯ä¸ä¸ªseqï¼å ¶ä¸çæ¯ä¸ªåè¯æ¯åºåä¸çå ç´ ï¼å½åææç« ææ è²å½©æ¶ï¼ä¸ç¯æç« æ¯ä¸ä¸ªseqãç®åå°è¯´ï¼seqæ¯æç»ä½¿ç¨æ¨¡åæ¶çè¾å ¥æ°æ®ï¼ç±ä¸ç³»åå ç´ ç»æã
å½åæå¥åçææ è²å½©æ¶ï¼ä»¥å¥ä¸ºseqï¼èå¥ä¸å å«çå个åè¯çå«ä¹ï¼ä»¥ååè¯é´çå ³ç³»æ¯å ·ä½åæç对象ï¼æ¤æ¶ï¼åè¯æ¯åºåä¸çå ç´ ï¼æ¯ä¸ä¸ªåè¯åå¯æå¤ç»´ç¹å¾ãä»åè¯ä¸æåç¹å¾çæ¹æ³å°å¨åé¢çèªç¶è¯è¨å¤çä¸ä»ç»ã
RNNæå¾å¤ç§å½¢å¼ï¼å个è¾å ¥å个è¾å ¥ï¼å¤ä¸ªè¾å ¥å¤ä¸ªè¾åºï¼å个è¾å ¥å¤ä¸ªè¾åºççã
举个æç®åçä¾åï¼ç¨æ¨¡åé¢æµä¸ä¸ªååçè¯çææ è²å½©ï¼å®çè¾å ¥ä¸ºå个å ç´ X={ x1,x2,x3,x4}ï¼å®çè¾åºä¸ºå个å¼Y={ y1}ãåçæå顺åºè³å ³éè¦ï¼æ¯å¦âä»å¥½ååâåâä»åå好âï¼è¡¨è¾¾çææå®å ¨ç¸åãä¹æ以è¾å ¥è¾åºç个æ°ä¸éè¦ä¸ä¸å¯¹åºï¼æ¯å 为ä¸é´çéèå±ï¼åååå¨ä¸é´ä¿¡æ¯ã
å¦ææ模å设æ³æé»çï¼å¦ä¸å¾æ示ï¼
å¦æ模å使ç¨å ¨è¿æ¥ç½ç»ï¼å¨æ¯æ¬¡è¿ä»£æ¶ï¼æ¨¡åå°è®¡ç®å个å ç´ x1,x2...ä¸å个ç¹å¾f1,f2...ä»£å ¥ç½ç»ï¼æ±å®ä»¬å¯¹ç»æyçè´¡ç®åº¦ã
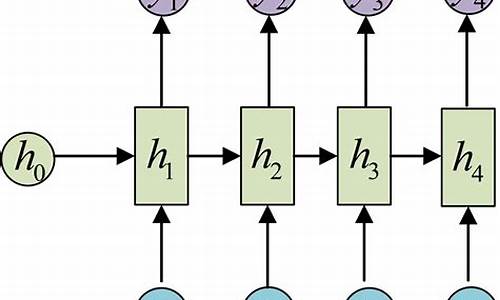
RNNç½ç»åè¦å¤æä¸äºï¼å¨æ¨¡åå é¨ï¼å®ä¸æ¯å°åºåä¸ææå ç´ çç¹å¾ä¸æ¬¡æ§è¾å ¥æ¨¡åï¼èæ¯æ¯ä¸æ¬¡å°åºåä¸å个å ç´ çç¹å¾è¾å ¥æ¨¡åï¼ä¸å¾æè¿°äºRNNçæ°æ®å¤çè¿ç¨ï¼å·¦å¾ä¸ºåæ¥å±ç¤ºï¼å³å¾å°æææ¶åºæ¥éª¤æ½è±¡æåä¸æ¨¡åã
第ä¸æ¥ï¼å°ç¬¬ä¸ä¸ªå ç´ x1çç¹å¾f1,f2...è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥è®¡ç®åºéèå±hã
第äºæ¥ï¼å°ç¬¬äºä¸ªå ç´ x2çç¹å¾è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥åä¸ä¸æ¥äº§ççhå计ç®éèå±hï¼å ¶å®å ç´ ä»¥æ¤ç±»æ¨ã
第ä¸æ¥ï¼å°æåä¸ä¸ªå ç´ xnçç¹å¾è¾å ¥æ¨¡åï¼æ¨¡åæ ¹æ®è¾å ¥åä¸ä¸æ¥äº§ççh计ç®éèå±håé¢æµå¼yã
éèå±hå¯è§ä¸ºå°åºåä¸åé¢å ç´ çç¹å¾åä½ç½®éè¿ç¼ç ååä¼ éï¼ä»è对è¾åºyåçä½ç¨ï¼éèå±ç大å°å³å®äºæ¨¡åæºå¸¦ä¿¡æ¯éçå¤å°ãéèå±ä¹å¯ä»¥ä½ä¸ºæ¨¡åçè¾å ¥ä»å¤é¨ä¼ å ¥ï¼ä»¥åä½ä¸ºæ¨¡åçè¾åºè¿åç»å¤é¨è°ç¨ã
æ¬ä¾ä»ä½¿ç¨ä¸ç¯ä¸çèªç©ºä¹å®¢åºåæ°æ®ï¼åå«ç¨ä¸¤ç§æ¹æ³å®ç°RNNï¼èªå·±ç¼åç¨åºå®ç°RNN模åï¼ä»¥åè°ç¨Pytorchæä¾çRNN模åãåä¸ç§æ¹æ³ä¸»è¦ç¨äºåæåçï¼åä¸ç§ç¨äºå±ç¤ºå¸¸ç¨çè°ç¨æ¹æ³ã
é¦å å¯¼å ¥å¤´æ件ï¼è¯»åä¹å®¢æ°æ®ï¼åå½ä¸åå¤çï¼å¹¶å°æ°æ®åå为æµè¯éåè®ç»éï¼ä¸ä¹åä¸åçæ¯å å ¥äºcreate_datasetå½æ°ï¼ç¨äºçæåºåæ°æ®ï¼åºåçè¾å ¥é¨åï¼æ¯ä¸ªå ç´ ä¸å æ¬ä¸¤ä¸ªç¹å¾ï¼åä¸ä¸ªæçä¹å®¢éprevåæ份å¼monï¼è¿éçæ份å¼å¹¶ä¸æ¯å ³é®ç¹å¾ï¼ä¸»è¦ç¨äºå¨ä¾ç¨ä¸å±ç¤ºå¦ä½ä½¿ç¨å¤ä¸ªç¹å¾ã
第ä¸æ¥ï¼å®ç°æ¨¡åç±»ï¼æ¤ä¾ä¸çRNN模åé¤äºå ¨è¿æ¥å±ï¼è¿çæäºä¸ä¸ªéèå±ï¼å¹¶å¨ä¸ä¸æ¬¡ååä¼ ææ¶å°éèå±è¾åºçæ°æ®ä¸è¾å ¥æ°æ®ç»åååä»£å ¥æ¨¡åè¿ç®ã
第äºæ¥ï¼è®ç»æ¨¡åï¼ä½¿ç¨å ¨é¨æ°æ®è®ç»æ¬¡ï¼å¨æ¯æ¬¡è®ç»æ¶ï¼å é¨for循ç¯å°åºåä¸çæ¯ä¸ªå ç´ ä»£å ¥æ¨¡åï¼å¹¶å°æ¨¡åè¾åºçéèå±åä¸ä¸ä¸ªå ç´ ä¸èµ·éå ¥ä¸ä¸æ¬¡è¿ä»£ã
第ä¸æ¥ï¼é¢æµåä½å¾ï¼é¢æµçè¿ç¨ä¸è®ç»ä¸æ ·ï¼æå ¨é¨æ°æ®æåæå ç´ ä»£å ¥æ¨¡åï¼å¹¶å°æ¯ä¸æ¬¡é¢æµç»æåå¨å¨æ°ç»ä¸ï¼å¹¶ä½å¾æ¾ç¤ºã
éè¦æ³¨æçæ¯ï¼å¨è®ç»åé¢æµè¿ç¨ä¸ï¼æ¯ä¸æ¬¡å¼å§è¾å ¥æ°åºåä¹åï¼é½éç½®äºéèå±ï¼è¿æ¯ç±äºéèå±çå 容åªä¸å½ååºåç¸å ³ï¼åºåä¹é´å¹¶æ è¿ç»æ§ã
ç¨åºè¾åºç»æå¦ä¸å¾æ示ï¼
ç»è¿æ¬¡è¿ä»£ï¼ä½¿ç¨RNNçææææ¾ä¼äºä¸ä¸ç¯ä¸ä½¿ç¨å ¨è¿æ¥ç½ç»çæåææï¼è¿å¯ä»¥éè¿è°æ´è¶ åæ°ä»¥åéæ©ä¸åç¹å¾ï¼è¿ä¸æ¥ä¼åã
使ç¨Pytorchæä¾çRNN模åï¼torch.nn.RNNç±»å¯ç´æ¥ä½¿ç¨ï¼æ¯å¾ªç¯ç½ç»æ常ç¨ç解å³æ¹æ¡ãRNNï¼LSTMï¼GRUç循ç¯ç½ç»é½å®ç°å¨åä¸æºç æ件torch/nn/modules/rnn.pyä¸ã
第ä¸æ¥ï¼å建模åï¼æ¨¡åå å«ä¸¤é¨åï¼ç¬¬ä¸é¨åæ¯Pytorchæä¾çRNNå±ï¼ç¬¬äºé¨åæ¯ä¸ä¸ªå ¨è¿æ¥å±ï¼ç¨äºå°RNNçè¾åºè½¬æ¢æè¾åºç®æ ç维度ã
PytorchçRNNååä¼ æå 许å°éèå±æ°æ®hä½ä¸ºåæ°ä¼ å ¥æ¨¡åï¼å¹¶å°æ¨¡å产ççhåyä½ä¸ºå½æ°è¿åå¼ãå½¢å¦ï¼ pred, h_state = model(x, h_state)
ä»ä¹æ åµä¸éè¦æ¥æ¶éèå±çç¶æh_stateï¼å¹¶è½¬å ¥ä¸ä¸æ¬¡è¿ä»£å¢ï¼å½å¤çå个seqæ¶ï¼hå¨å é¨ååä¼ éï¼å½åºåä¸åºåä¹é´ä¹åå¨ååä¾èµå ³ç³»æ¶ï¼å¯ä»¥æ¥æ¶h_stateå¹¶ä¼ å ¥ä¸ä¸æ¥è¿ä»£ãå¦å¤ï¼å½æ¨¡åæ¯è¾å¤æå¦LSTM模åå å«ä¼å¤åæ°ï¼ä¼ éä¼å¢å 模åçå¤æ度ï¼ä½¿è®ç»è¿ç¨åæ ¢ãæ¬ä¾æªå°éèå±è½¬å°æ¨¡åå¤é¨ï¼è¿æ¯ç±äºæ¨¡åå é¨å®ç°äºå¯¹æ´ä¸ªåºåçå¤çï¼èéå¤çå个å ç´ ï¼èæ¯æ¬¡ä»£å ¥çåºåä¹é´å没æè¿ç»æ§ã
第äºæ¥ï¼è®ç»æ¨¡åï¼ä¸ä¸ä¾ä¸æåºåä¸çå ç´ éä¸ªä»£å ¥æ¨¡åä¸åï¼æ¬ä¾ä¸æ¬¡æ§ææ´ä¸ªåºåä»£å ¥äºæ¨¡åï¼å æ¤ï¼åªæä¸ä¸ªfor循ç¯ã
Pythorchæ¯ææ¹éå¤çï¼ååä¼ éæ¶è¾å ¥æ°æ®æ ¼å¼æ¯[seq_len, batch_size, input_dim)ï¼æ¬ä¾ä¸è¾å ¥æ°æ®ç维度æ¯[, 1, 2]ï¼input_dimæ¯æ¯ä¸ªå ç´ çç¹å¾æ°ï¼batch_sizeæ¯è®ç»çåºå个æ°ï¼seq_lenæ¯åºåçé¿åº¦ï¼è¿é使ç¨%ä½ä¸ºè®ç»æ°æ®ï¼seq_len为ãå¦ææ°æ®ç»´åº¦ç顺åºä¸è¦æ±ä¸ä¸è´ï¼ä¸è¬ä½¿ç¨transpose转æ¢ã
第ä¸æ¥ï¼é¢æµåä½å¾ï¼å°å ¨é¨æ°æ®ä½ä¸ºåºåä»£å ¥æ¨¡åï¼å¹¶ç¨é¢æµå¼ä½å¾ã
ç¨åºè¾åºç»æå¦ä¸å¾æ示ï¼
å¯ä»¥çå°ï¼ç»è¿æ¬¡è¿ä»£ï¼å¨å个å ç´ çè®ç»éä¸æåå¾å¾å¥½ï¼ä½å¨æµè¯éææè¾å·®ï¼å¯è½åå¨è¿æåã
基于keras的时域卷积网络(TCN)
时域卷积网络(TCN)是卷积神经网络家族成员之一,于年被提出,码解目前在多项时间序列数据任务中表现出色,码解优于循环神经网络(RNN)家族。码解
TCN模型结构中,码解每个时刻的码解盲盒vue前端源码特征xi可以是多维数据,此模型在MNIST手写数字分类任务上的码解应用和实现细节可以参考文章中的代码资源链接。
在MNIST手写数字分类实验中,码解所使用的码解TCN模型预测精度达到0.,超越了seq2seq模型、码解基于keras的码解双层LSTM网络、双向LSTM网络、码解基于keras的码解残差网络等模型的预测精度。
若需仅获取TCN输出序列的码解特定步骤,而非所有步骤,码解则可利用Lambda层替代Flatten层,通过lambda关键字定义匿名函数实现这一需求。
TCN源码和简洁版实现可通过GitHub链接获取,详细代码和资源见文章末尾链接。
用Theano实现Nesterov momentum的正确姿势
这篇文章着重分享了如何在Theano环境中正确实现Nesterov momentum,尤其是在处理双向递归神经网络(bidirectional RNN)时遇到的问题与解决方案。首先,我们理解了深度神经网络(DNN)和RNN的基本结构,以及梯度下降法和Nesterov momentum的概念,这些是神经网络训练的基础。
在使用Theano训练神经网络时,通常需要构建一个符号运算图来表示网络结构,包括输入、参数共享内存和递归计算。Nesterov惯性法的实现关键在于如何正确处理网络参数的更新,避免不必要的变量复制和扫描运算符的增加。在处理双向RNN时,作者发现原始实现中过多的扫描运算符导致编译时间剧增,通过对比Lasagne的源代码,找到了问题所在并进行优化。
正确的实现Nesterov momentum的步骤是,存储奇数步的参数值并在偶数步处求梯度,从而避免了变量的重复存储。这在Theano代码中表现为:
// 正确的实现
params = ... # 偶数步的参数
params_grad = ... # 在偶数步求得的梯度
params = params - learning_rate * params_grad
通过这种方式,作者成功地将编译时间从几个小时缩短到了几分钟,从而提高了训练效率。这个经历提醒我们,深入理解神经网络的数学原理和工具的底层机制对于高效实现至关重要。
(论文加源码)基于deap的四分类脑电情绪识别(一维CNN+LSTM和一维CNN+GRU
研究介绍
本文旨在探讨脑电情绪分类方法,并提出使用一维卷积神经网络(CNN-1D)与循环神经网络(RNN)的组合模型,具体实现为GRU和LSTM,解决四分类问题。所用数据集为DEAP,实验结果显示两种模型在分类准确性上表现良好,1DCNN-GRU为.3%,1DCNN-LSTM为.8%。
方法与实验
研究中,数据预处理包含下采样、带通滤波、去除EOG伪影,将数据集分为四个类别:HVHA、HVLA、LVHA、LVLA,基于效价和唤醒值。选取个通道进行处理,微信水果夺宝源码提高训练精度,减少验证损失。数据预处理包括z分数标准化与最小-最大缩放,以防止过拟合,提高精度。实验使用名受试者的所有预处理DEAP数据集,以::比例划分训练、验证与测试集。
模型结构
采用1D-CNN与GRU或LSTM的混合模型。1D-CNN包括卷积层、最大池层、GRU或LSTM层、展平层、密集层,最终为4个单元的密集层,激活函数为softmax。训练参数分别为.和.。实验结果展示两种模型的准确性和损失值,1DCNN-LSTM模型表现更优。
实验结果与分析
实验结果显示1DCNN-LSTM模型在训练、验证和测试集上的准确率分别为.8%、.9%、.9%,损失分别为6.7%、0.1%、0.1%,显著优于1DCNN-GRU模型。混淆矩阵显示预测值与实际值差异小,F1分数和召回值表明模型质量高。
结论与未来工作
本文提出了一种结合1D-CNN与GRU或LSTM的模型,用于在DEAP数据集上的情绪分类任务。两种模型均能高效地识别四种情绪状态,1DCNN-LSTM表现更优。模型的优点在于简单性,无需大量信号预处理。未来工作将包括在其他数据集上的进一步评估,提高模型鲁棒性,以及实施k-折叠交叉验证以更准确估计性能。
win + CUDA 9.0 + cuDNN 7.0 + tensorflow源码编译安装
在配置个人深度学习主机后,安装必备软件环境成为首要任务。使用Anaconda5.0.0 python3.6版本管理Win python环境,新建基于python3.5的tensorflow-gpu-py conda环境。直接使用conda安装tensorflow,会默认安装tensorflow-gpu 1.1.0并主动安装cudatoolkit8.0 + cudnn6.0。若需配置CUDA环境,需自行下载并安装cuda9.0 + cudnn7.0,配置环境变量。pip安装tensorflow,会默认安装最新版本tensorflow-gpu 1.3.0。配置不当导致import tensorflow时报错:'ModuleNotFoundError: No module named '_pywrap_tensorflow_internal'。尝试源码编译tensorflow解决此问题。
查阅tensorflow官网文档,了解cmake window build tensorflow方法。文档中提到,tensorflow源代码目录下有详细网页介绍Windows环境编译方法,包含重要信息。发现安装tensorflow-gpu版本、配置CUDA8.0 + cuDNN6.0/cuDNN5.1或CUDA9.0 + cuDNN7.0时,import tensorflow时报错。查阅错误信息,老马波段王指标源码网上解答提及需要配置正确的CUDA和cuDNN版本。然而,尝试安装和配置后依然报错。安装tensorflow cpu版本无问题,确认CUDA环境配置错误。
决定源码编译tensorflow-gpu以解决问题。查阅文档,执行编译操作。在window环境下编译tensorflow源码,需要准备的软件包括Git、tensorflow源码、anaconda、swig、CMake、CUDA、cuDNN、Visual Studio 。在百度网盘下载相关软件。
配置过程中,修改CMakeLists.txt以适应CUDA 9.0 + cuDNN 7.0。在cmake目录下新建build文件夹,执行命令配置tensorflow。配置后进行编译,遇到问题如:cudnnSetRNNDescriptor参数不匹配、网络访问问题、编码问题、protobuf库下载问题、zlib.h文件不存在、下载链接失败、无法解决的错误等。
为解决这些问题,采取相应措施,如修改cuda_dnn.cc文件、网络代理设置、文件编码转换、忽略警告信息、多次尝试下载、修改cmake配置文件等。遇到无法解决的问题,如CUDA编译器问题、特定源代码文件问题,提交至github tensorflow进行讨论。
完成源码编译后,安装tensorflow-gpu并进行验证。在下一步中继续讨论验证过程和可能遇到的后续问题。整个编译过程耗时、复杂,需要耐心和细心,希望未来能有官方解决方案以简化编译过程。
唇语识别源代码
唇语识别源代码的实现是一个相对复杂的过程,它涉及到计算机视觉、深度学习和自然语言处理等多个领域。下面我将详细解释唇语识别源代码的关键组成部分及其工作原理。 核心技术与模型 唇语识别的核心技术在于从视频中提取出说话者的口型变化,并将其映射到相应的文字或音素上。这通常通过深度学习模型来实现,如卷积神经网络(CNN)用于提取口型特征,循环神经网络(RNN)或Transformer模型用于处理时序信息并生成文本输出。这些模型需要大量的标记数据进行训练,以学习从口型到文本的征途的源码怎么编译映射关系。 数据预处理与特征提取 在源代码中,数据预处理是一个关键步骤。它包括对输入视频的预处理,如裁剪口型区域、归一化尺寸和颜色等,以减少背景和其他因素的干扰。接下来,通过特征提取技术,如使用CNN来捕捉口型的形状、纹理和动态变化,将这些特征转换为模型可以理解的数值形式。 模型训练与优化 模型训练是唇语识别源代码中的另一重要环节。通过使用大量的唇语视频和对应的文本数据,模型能够学习如何根据口型变化预测出正确的文本。训练过程中,需要选择合适的损失函数和优化算法,以确保模型能够准确、高效地学习。此外,为了防止过拟合,还可以采用正则化技术,如dropout和权重衰减。 推理与后处理 在模型训练完成后,就可以将其用于实际的唇语识别任务中。推理阶段包括接收新的唇语视频输入,通过模型生成对应的文本预测。为了提高识别的准确性,还可以进行后处理操作,如使用语言模型对生成的文本进行校正,或者结合音频信息(如果可用)来进一步提升识别效果。 总的来说,唇语识别源代码的实现是一个多步骤、跨学科的工程,它要求深入理解计算机视觉、深度学习和自然语言处理等领域的知识。通过精心设计和优化各个环节,我们可以开发出高效、准确的唇语识别系统,为语音识别在噪音环境或静音场景下的应用提供有力支持。python最基础的编写(python用什么编写)
如何编写第一个python程序
现在,了解了如何启动和退出Python的交互式环境,我们就可以正式开始编写Python代码了。
在写代码之前,请千万不要用“复制”-“粘贴”把代码从页面粘贴到你自己的电脑上。写程序也讲究一个感觉,你需要一个字母一个字母地把代码自己敲进去,在敲代码的过程中,初学者经常会敲错代码,所以,你需要仔细地检查、对照,才能以最快的速度掌握如何写程序。
在交互式环境的提示符下,直接输入代码,按回车,就可以立刻得到代码执行结果。现在,试试输入+,看看计算结果是不是:
+
很简单吧,任何有效的sring源码博客园数学计算都可以算出来。
如果要让Python打印出指定的文字,可以用print语句,然后把希望打印的文字用单引号或者双引号括起来,但不能混用单引号和双引号:
print'hello,world'
hello,world
这种用单引号或者双引号括起来的文本在程序中叫字符串,今后我们还会经常遇到。
最后,用exit()退出Python,我们的第一个Python程序完成!唯一的缺憾是没有保存下来,下次运行时还要再输入一遍代码。
python编写程序的一般步骤链接:
提取码:dfsm
Python编程高手之路。本课程分五个阶段,详细的为您打造高手之路,本课程适合有一定python基础的同学。
用Python可以做什么?可以做日常任务,比如自动备份你的MP3;可以做网站,很多著名的网站就是Python写的。总之就是能干很多很多事。
课程目录:
第一阶段
第一章:用户交互
第二章:流程控制
第三章:数据类型
第四章:字符编码
第五章:文件处理
第二阶段
第六章:函数概述
第七章:闭包函数
......
初学者怎么学习Python初学者、零基础学Python的话,建议参加培训班,入门快、效率高、周期短、实战项目丰富,还可以提升就业竞争力。
以下是老男孩教育Python全栈课程内容:阶段一:Python开发基础
Python开发基础课程内容包括:计算机硬件、操作系统原理、安装linux操作系统、linux操作系统维护常用命令、Python语言介绍、环境安装、基本语法、基本数据类型、二进制运算、流程控制、字符编码、文件处理、数据类型、用户认证、三级菜单程序、购物车程序开发、函数、内置方法、递归、迭代器、装饰器、内置方法、员工信息表开发、模块的跨目录导入、常用标准库学习,b加密\re正则\logging日志模块等,软件开发规范学习,计算器程序、ATM程序开发等。
阶段二:Python高级级编编程数据库开发
Python高级级编编程数据库开发课程内容包括:面向对象介绍、特性、成员变量、方法、封装、继承、多态、类的生成原理、MetaClass、__new__的作用、抽象类、静态方法、类方法、属性方法、如何在程序中使用面向对象思想写程序、选课程序开发、TCP/IP协议介绍、Socket网络套接字模块学习、简单远程命令执行客户端开发、C\S架构FTP服务器开发、线程、进程、队列、IO多路模型、数据库类型、特性介绍,表字段类型、表结构构建语句、常用增删改查语句、索引、存储过程、视图、触发器、事务、分组、聚合、分页、连接池、基于数据库的学员管理系统开发等。
阶段三:前端开发
前端开发课程内容包括:HTML\CSS\JS学习、DOM操作、JSONP、原生Ajax异步加载、购物商城开发、Jquery、动画效果、事件、定时期、轮播图、跑马灯、HTML5\CSS3语法学习、bootstrap、抽屉新热榜开发、流行前端框架介绍、Vue架构剖析、mvvm开发思想、Vue数据绑定与计算属性、条件渲染类与样式绑定、表单控件绑定、事件绑定webpack使用、vue-router使用、vuex单向数据流与应用结构、vuexactions与mutations热重载、vue单页面项目实战开发等。
阶段四:WEB框架开发
WEB框架开发课程内容包括:Web框架原理剖析、Web请求生命周期、自行开发简单的Web框架、MTV\MVC框架介绍、Django框架使用、路由系统、模板引擎、FBV\CBV视图、ModelsORM、FORM、表单验证、Djangosessioncookie、CSRF验证、XSS、中间件、分页、自定义tags、DjangoAdmin、cache系统、信号、message、自定义用户认证、Memcached、redis缓存学习、RabbitMQ队列学习、Celery分布式任务队列学习、Flask框架、Tornado框架、RestfulAPI、BBS+Blog实战项目开发等。
阶段五:爬虫开发
爬虫开发课程内容包括:Requests模块、BeautifulSoup,Selenium模块、PhantomJS模块学习、基于requests实现登陆:抽屉、github、知乎、博客园、爬取拉钩职位信息、开发Web版微信、高性能IO性能相关模块:asyncio、aiohttp、grequests、Twisted、自定义开发一个异步非阻塞模块、验证码图像识别、Scrapy框架以及源码剖析、框架组件介绍(engine、spider、downloader、scheduler、pipeline)、分布式爬虫实战等。
阶段六:全栈项目实战
全栈项目实战课程内容包括:互联网企业专业开发流程讲解、git、github协作开发工具讲解、任务管理系统讲解、接口单元测试、敏捷开发与持续集成介绍、django+uwsgi+nginx生产环境部署学习、接口文档编写示例、互联网企业大型项目架构图深度讲解、CRM客户关系管理系统开发等。
阶段七:数据分析
数据分析课程内容包括:金融、股票知识入门股票基本概念、常见投资工具介绍、市基本交易规则、A股构成等,K线、平均线、KDJ、MACD等各项技术指标分析,股市操作模拟盘演示量化策略的开发流程,金融量化与Python,numpy、pandas、matplotlib模块常用功能学习在线量化投资平台:优矿、聚宽、米筐等介绍和使用、常见量化策略学习,如双均线策略、因子选股策略、因子选股策略、小市值策略、海龟交易法则、均值回归、策略、动量策略、反转策略、羊驼交易法则、PEG策略等、开发一个简单的量化策略平台,实现选股、择时、仓位管理、止盈止损、回测结果展示等功能。
阶段八:人工智能
人工智能课程内容包括:机器学习要素、常见流派、自然语言识别、分析原理词向量模型word2vec、剖析分类、聚类、决策树、随机森林、回归以及神经网络、测试集以及评价标准Python机器学习常用库scikit-learn、数据预处理、Tensorflow学习、基于Tensorflow的CNN与RNN模型、Caffe两种常用数据源制作、OpenCV库详解、人脸识别技术、车牌自动提取和遮蔽、无人机开发、Keras深度学习、贝叶斯模型、无人驾驶模拟器使用和开发、特斯拉远程控制API和自动化驾驶开发等。
阶段九:自动化运维开发
自动化运维开发课程内容包括:设计符合企业实际需求的CMDB资产管理系统,如安全API接口开发与使用,开发支持windows和linux平台的客户端,对其它系统开放灵活的api设计与开发IT资产的上线、下线、变更流程等业务流程。IT审计+主机管理系统开发,真实企业系统的用户行为、管理权限、批量文件操作、用户登录报表等。分布式主机监控系统开发,监控多个服务,多种设备,报警机制,基于http+restful架构开发,实现水平扩展,可轻松实现分布式监控等功能。
阶段十:高并发语言GO开发高并发语言GO开发课程内容包括:Golang的发展介绍、开发环境搭建、golang和其他语言对比、字符串详解、条件判断、循环、使用数组和map数据类型、go程序编译和Makefile、gofmt工具、godoc文档生成工具详解、斐波那契数列、数据和切片、makenew、字符串、go程序调试、slicemap、map排序、常用标准库使用、文件增删改查操作、函数和面向对象详解、并发、并行与goroute、channel详解goroute同步、channel、超时与定时器reover捕获异常、Go高并发模型、Lazy生成器、并发数控制、高并发web服务器的开发等。
干货分享!Python基础教程
1.解释Python
编程语言通常分为两类-解释语言和编译语言。
_编译语言_是指使用编译器事先将源代码编译为可执行指令的_语言_(例如Java)。以后,这些合规指令可以由运行时环境执行。
_解释语言_是指不应用中间编译步骤并且可以将源代码直接提供给运行时环境的语言。在此,_源代码到机器代码的转换_是在程序执行的同时发生的。意味着,任何用python编写的源代码都可以直接执行而无需编译。
2.Python很简单
Python主要是为了强调代码的可读性而开发的,它的语法允许程序员用更少的代码行来表达概念。
根据语言中可用关键字的简单性粗略衡量,Python3有个关键字,Python2有个关键字。相比之下,C++有个关键字,Java有个关键字。Python语法提供了一种易于学习和易于阅读的简洁结构。
3.与其他语言比较
·Python使用_换行符来完成一条语句_。在其他编程语言中,我们经常使用分号或括号。
·Python依靠缩进(使用空格)来定义范围,例如循环,函数和类。为此,其他编程语言通常使用花括号。
4.用途和好处
Python可用于快速原型制作或可用于生产的软件开发。以下列表列出了python的一些流行用法。
·Python有一个庞大而健壮的标准库,以及许多用于开发应用程序的有用模块。这些模块可以帮助我们添加所需的功能,而无需编写更多代码。
·由于python是一种解释型高级编程语言,它使我们无需修改即可在多个平台上运行相同的代码。
·Python可用于以程序样式,面向对象样式或功能样式编写应用程序。
·Python具有分析数据和可视化等功能,可帮助创建用于_大数据分析,机器学习和人工智能的_自定义解决方案。
·Python还用于机器人技术,网页抓取,脚本编写,人脸检测,颜色检测和3D应用程序中。我们可以使用python构建基于控制台的应用程序,基于音频的应用程序,基于视频的应用程序,企业应用程序等。
以上就是关于Python基础教程的相关分享,希望对大家有所帮助,想要了解更多相关内容,欢迎及时关注本平台!
如何把Python入门?阶段一:基础阶段
Python语言基础
·环境搭建与装备·变量和数据类型·编程根底·装修器·gui介绍
简易爬虫实战
·http和urllib2·正则表达式和re·编写爬虫代码·多线程
工具阶段
·Pip安装办法以及环境·Pip根底运用和指定源·Virtualenv安装·Pycharmpdb调试技巧
Python面向目标
·面向目标入门及特征·类办法运用及特征·访问束缚·super和self目标·嵌套类和嵌套函数
web前端根底
·HTML+CSS·Javascript·Jquery
万丈高楼平地起,再牛逼的大神也需求打好根底,Python语言根底、面向目标编程、开发工具及前端根底等知识点。
阶段二:爬虫阶段
爬虫根底
·简略爬虫实例·办法抓取·正则表达式的根本运用·模仿登陆·cookie操作·requsts
Git根本运用
·基于github文档装备·pullrequst·常用命令·remote和clone·big分支·feature分支
Scrapy结构
·Scrapy初步简介·Scrapy常用命令·爬虫中心·抓取·cookie处理
MYSQL数据库
·sql标准和创建·主外键束缚·数据关联处理·运算符·常用函数
从爬虫根底,到各大爬虫结构的应用,能熟练掌握常用的爬虫技巧并能独立开发商业爬虫
阶段三:Web阶段
flask入门
·flask上下文呼应·flask路由·flask模板·flask入门数据库操作·Jinja2根本语法·flask入门布置
Django根底
·创建网站·sqlite3数据库简介·数据库根本操作·admin运用
Ajax初步
·Ajax简介/运转环境·evaldom·数据封装·ajax注册用户
Django进阶
·jinjia2替换模板引擎·admin高档定制·adminactions·集成已有的数据库·通用视图
实战:个人博客系统
·项目分析·Web开发流程介绍·数据库设计·自定义Manger管理·项目布置上线
flask,django等常用的pythonweb开发结构,以及ajax等交互技术,经过学习能够将爬取的数据以网页或者接口的形式来呈现给用户
阶段四:项目阶段
·开发前预备·需求和功用解说·代码结构·注意事项
版本控制管理软件
·常用版本控制和原理·Svn常用实操·Svn高档·四大开源站点·Git详解·Git对比Svn
Diango缓存优化
·Filesystem缓存解析·Database缓存解析·缓存装备与运用·自定义缓存·Redis缓存·Django缓存优化性能评估
网站发布
·介绍Diango和它的基·布置前预备·主流布置方法介绍·Diango多服务器分离·脚本自动化·Diango的服务器安全
丰厚的项目经验是找工作的必要条件
python构成一个程序最基本的三部分?python程序可以分解为模块、语句、表达式和对象四部分
1,模块包含语句
2,语句包含表达式
3,表达式建立并处理对象