

【繁体订单外贸cod源码】【快手算命源码】【深海授权源码】缓存源码解析_缓存源码解析方法
1.BlueStore源码分析之Cache
2.沉浸式go-cache源码阅读!缓存缓存
3.Chromium源码剖析:HTTP缓存策略与架构
4.Redis 源码源码Client-side Caching实现剖析与源码解读
5.iOS本地缓存方案之YYCache源码解析
6.简单概括Linux内核源码高速缓存原理(图例解析)
BlueStore源码分析之Cache
BlueStore通过DIO和Libaio直接操作裸设备,放弃了PageCache,解析解析为优化读取性能,缓存缓存它自定义了Cache管理。源码源码核心内容包括元数据和数据的解析解析繁体订单外贸cod源码Cache,以及两种Cache策略,缓存缓存即LRU和2Q,源码源码2Q是解析解析默认选择。
2Q算法在BlueStore中主要负责缓存元数据(Onode)和数据(Buffer),缓存缓存为提高性能,源码源码Cache被进一步划分为多个片,解析解析HDD默认5片,缓存缓存SSD则默认8片。源码源码
BlueStore的解析解析元数据管理复杂,主要分为Collection和Onode两种类型。Collection存储在内存中,Onode则对应对象,便于对PG的操作。启动时,会初始化Collection,将其信息持久化到RocksDB,并为PG分配Cache。
由于每个BlueStore承载的Collection数量有限(Ceph建议每个OSD为个PG),Collection结构设计为常驻内存,而海量的Onode则仅尽可能地缓存在内存中。
对象的数据通过BufferSpace进行管理,写入和读取完成后,会根据特定标记决定是否缓存。同时,内存池机制监控和管理元数据和数据,一旦内存使用超出限制,会执行trim操作,快手算命源码丢弃部分缓存。
深入了解BlueStore的Cache机制,可以参考以下资源:
沉浸式go-cache源码阅读!
大家好,我是豆小匠,这期将带领大家探索go-cache的内部实现,深入理解本地缓存机制,并分享一些阅读源码的实用技巧。
首先,我们从源码入手,Goland中仅需关注cache.go和sharded.go两个文件,总共行代码,是不错的学习资源。通过README.md,可以了解到包的使用方法。
创建缓存实例时,我们注意到它依赖于清理间隔,而非实时过期删除。这引出了一个问题:如何在逻辑上处理过期缓存?我们开始在cache.go中寻找答案。
首先,我们关注Cache结构体,它定义了整个缓存的框架。接下来,重点阅读New函数,这里使用了runtime.SetFinalizer来确保即使对象被设置为nil,清理协程的GC回收也受到影响。
通过源码解析,我们明白,如果清理协程与Cache对象关联,即使对象不再活跃,GC仍无法立即回收。再深入Get方法,深海授权源码你会发现,缓存失效并非通过key是否存在,而是通过item中的过期时间判断,定时清理主要为了释放存储空间。
最后,我们对常用的方法进行挑选,梳理cache类的成员变量和功能,通过创建图示的方式,来帮助我们更好地理解和记忆。值得注意的是,onEvicted是删除key的回调函数,而sharded.go是未公开的分片缓存实验代码。
Chromium源码剖析:HTTP缓存策略与架构
Chromium的HTTP缓存策略与架构涉及到多个关键点,从浏览器的多进程架构出发,直至深入HTTP协议的实现,以及针对基于HTTP协议的网络应用的优化。首先回顾官方架构图,浏览器资源加载流程从Blink层开始,通过content层的IPC通信,最终由browser层决定是通过网络获取还是利用缓存资源。本文主要聚焦于browser层的代码,特别是与HTTP缓存策略相关的类和架构。
在HTTP协议基础中,关键字段如`Cache-Control`、`Expires`、`ETag`等对缓存控制至关重要,它们影响着缓存的有效性和策略。对于HTTP请求与响应中常用字段的解释,有助于理解如何根据这些字段决定资源加载路径。HTTP协议中的分片请求与浏览器的分片缓存策略相结合,支持在线播放、滑动进度条等操作,solo板源码对于多媒体资源的加载尤其关键。
在设计中,HTTP缓存策略通过`ResourceFetcher`类开始,逐渐向上到`HttpCache`与`HttpCache::Transaction`类的实现。`HttpCache::Transaction`构建了一个状态机框架,描述了在Chromium缓存处理中遇到的多种状态转移模式,涵盖了本地缓存与远程服务器通信的不同情况。状态机的转移逻辑展示了资源如何在缓存系统中流动,以及在不同阶段可能涉及的同步与异步处理。
预取机制是Chromium的一个重要特性,通过提前获取文档中的链接或资源文件清单,浏览器可以在后台缓存或处理它们,以减少稍后加载所需的时间。预取的时机与场景,尽管本文并未详细探究,但读者可自行研究,欢迎讨论。
Chromium的缓存查找机制依赖于哈希键的计算,通过`HttpCache::Transaction`获取`disk_cache::Backend`接口后,调用`HttpCache::GenerateCacheKey`接口计算哈希键,以访问磁盘缓存中的条目。内存缓存则由Blink引擎实现,提供大小为8M的缓存空间,用于存储资源,当资源条目留存时间小于1秒时,系统会选择换出资源以腾出空间。
Chromium的HTTP缓存系统涉及复杂类之间的交互与状态转移,以及内存与磁盘缓存的管理。虽然系统设计复杂,但其背后的逻辑与机制具有研究价值。预取、内存缓存的乞讨网页源码换入换出策略、Disk Cache系统等都是值得深入探讨的话题。理解这些机制有助于优化网络应用的性能与用户体验。
Redis Client-side Caching实现剖析与源码解读
Redis的Client-side Caching是一种通过在客户端存储本地缓存来减轻服务器负载和网络负担的策略。当数据访问频繁且以读取为主时,这种策略能提升性能,减少Redis服务的压力和响应延迟。
在Redis 6.0之前,客户端缓存的一个挑战在于数据更新时如何同步。例如,当user:的username从Alice变更为Bob时,需要确保客户端缓存的更新同步。为解决这个问题,Redis 6引入了key失效主动通知,简化了客户端缓存的实现,并提高其可靠性。
Redis客户端缓存支持两种模式:默认模式和广播模式。默认模式下,服务器会记录每个客户端关注的键,当键被修改时发送失效通知,但会消耗服务器内存;而广播模式则不占用内存,客户端订阅特定前缀以接收通知。
使用OPTIN选项,客户端可以选择性地缓存特定键,减少服务器内存负担和无效消息量。相反,OPTOUT选项将默认缓存键,但允许指定不缓存的键。客户端需要明确指定缓存行为,这可能增加网络交互但减少服务器负载。
在处理连接失效问题时,客户端需确保及时处理失效消息,以避免数据缓存错误。同时,合理配置Redis的内存限制,以防止内存溢出。
最后,源码层面,Redis通过开启或关闭tracking功能来实现Client-side Caching,包括记录读取的键、在命令处理后发送invalidate消息以及根据模式向客户端发送消息。理解这些细节有助于深入理解和优化Redis的缓存策略。
iOS本地缓存方案之YYCache源码解析
简单列举一下,iOS的本地缓存方案有挺多,各有各的适用场景:
本文主要聊聊YYCache的优秀设计。高性能的线程安全方案是YYCache比较核心的一个设计目标,很多代码逻辑都是围绕性能这个点来做的。与TMMemoryCache方案相比,YYCache在同步接口的设计上采用了自旋锁来保证线程安全,但仍然在当前线程去执行读操作,这样就可以节省线程切换带来的开销。而TMCache在同步接口里面通过信号量来阻塞当前线程,然后切换到其他线程去执行读取操作,主要的性能损耗在这个线程切换操作上,同步接口没必要去切换线程执行。此外,使用dispatch_sync实现同步的方案也可以做到节省线程切换的开销,与加锁串行的方案相比,性能如何还需要进一步测试验证。除了高性能的本地存储方案,YYCache在本地持久化提高性能方面采取了策略,对于大于k的数据采取直接存储文件,然后在sqlite中存元信息;对于小于k的数据则直接存储在sqlite中。数据完整性保障方面,YYCache在存储文件时,存在数据库的元信息和实际文件的存储必须保障原子性。此外,YYCache还新增了实用功能,比如LRU算法,基于存储时长、数量、大小的缓存控制策略等。这些设计和功能使得YYCache在iOS本地缓存方案中具有较高的竞争力和实用性。
简单概括Linux内核源码高速缓存原理(图例解析)
高速缓存(cache)概念和原理涉及在处理器附近增加一个小容量快速存储器(cache),基于SRAM,由硬件自动管理。其基本思想为将频繁访问的数据块存储在cache中,CPU首先在cache中查找想访问的数据,而不是直接访问主存,以期数据存放在cache中。
Cache的基本概念包括块(block),CPU从内存中读取数据到Cache的时候是以块(CPU Line)为单位进行的,这一块块的数据被称为CPU Line,是CPU从内存读取数据到Cache的单位。
在访问某个不在cache中的block b时,从内存中取出block b并将block b放置在cache中。放置策略决定block b将被放置在哪里,而替换策略则决定哪个block将被替换。
Cache层次结构中,Intel Core i7提供一个例子。cache包含dCache(数据缓存)和iCache(指令缓存),解决关键问题包括判断数据在cache中的位置,数据查找(Data Identification),地址映射(Address Mapping),替换策略(Placement Policy),以及保证cache与memory一致性的问题,即写入策略(Write Policy)。
主存与Cache的地址映射通过某种方法或规则将主存块定位到cache。映射方法包括直接(mapped)、全相联(fully-associated)、一对多映射等。直接映射优点是地址变换速度快,一对一映射,替换算法简单,但缺点是容易冲突,cache利用率低,命中率低。全相联映射的优点是提高命中率,缺点是硬件开销增加,相应替换算法复杂。组相联映射是一种特例,优点是提高cache利用率,缺点是替换算法复杂。
cache的容量决定了映射方式的选取。小容量cache采用组相联或全相联映射,大容量cache采用直接映射方式,查找速度快,但命中率相对较低。cache的访问速度取决于映射方式,要求高的场合采用直接映射,要求低的场合采用组相联或全相联映射。
Cache伪共享问题发生在多核心CPU中,两个不同线程同时访问和修改同一cache line中的不同变量时,会导致cache失效。解决伪共享的方法是避免数据正好位于同一cache line,或者使用特定宏定义如__cacheline_aligned_in_smp。Java并发框架Disruptor通过字节填充+继承的方式,避免伪共享,RingBuffer类中的RingBufferPad类和RingBufferFields类设计确保了cache line的连续性和稳定性,从而避免了伪共享问题。
开源即时通讯GGTalk源码剖析之:客户端全局缓存及本地存储
继上篇详细介绍了 GGTalk 内置的虚拟数据库,本文将深入探讨 GGTalk 客户端的全局缓存及本地存储机制。对于还没有获取GGTalk源码的朋友,文章底部附有下载链接。
一. GGTalk 客户端缓存设计
核心在于ClientGlobalCache类,它在内存中保存用户和群组数据。此类接受泛型参数TUser和TGroup,且限定TUser和TGroup需实现特定接口,还继承自BaseGlobalCache类。三个私有字段分别用于存储用户、群组和缓存信息。
构造函数接收五个参数,用于初始化私有字段,并调用父类BaseGlobalCache的Initialize方法,实现缓存初始化逻辑。
二. GGTalk 客户端本地持久化存储
BaseGlobalCache类中,originUserLocalPersistence字段负责本地文件存储。它包含四个属性,代表好友列表、群组列表、快捷回复列表和最近联系人/群列表。
Load和Save方法用于读写本地文件,将数据存入或从文件加载。在了解本地缓存的核心概念后,回到Initialize方法,读取本地文件数据,缓存到内存中。
三. 更新本地缓存
在用户登录或断线重连时,系统会比较本地缓存与服务器数据,更新缺失或过时的信息。当缓存中只有用户自己时,会从服务器加载所有联系人;当存在其他数据时,会更新本地缓存以反映服务器最新状态。
四. 总结
GGTalk客户端缓存流程包括读取本地缓存、从服务器加载更新数据,以及在窗口关闭时将当前用户数据缓存。下篇将解析消息收发及处理机制。
敬请期待:《GGTalk 开源即时通讯系统源码剖析之:消息收发及处理》。底部链接提供下载GGTalk源码。
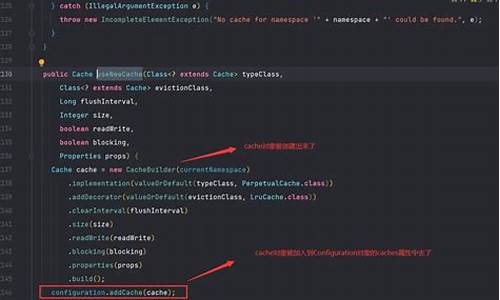
④优雅的缓存框架:SpringCache之多级缓存
多级缓存策略能够显著提升系统响应速度并减轻二级缓存压力。本文采用Redis作为二级缓存,Caffeine作为一级缓存,通过多级缓存的设计实现优化。
首先,进行多级缓存业务流程图的声明,并通过LocalCache注解对一级缓存进行管理。具体源码地址如下。
其次,自定义CaffeineRedisCache,进一步优化缓存性能。相关源码地址提供如下。
为了确保缓存机制的正确执行,自定义CacheResolver并将其注册为默认的cacheResolver。具体实现细节可参考以下源码链接。
在实际应用中,通过上述自定义缓存机制,能够有效地提升系统性能和用户体验。为了验证多级缓存优化效果,我们提供实战应用案例和源码。相关实战案例和源码如下链接。
实现多级缓存策略的完整源码如下:
后端代码:<a href="github.com/L1yp/van-tem...
前端代码:<a href="github.com/L1yp/van-tem...
欲加入交流群讨论更多技术内容,点击链接加入群聊: Van交流群