户用光伏为何增速陡降?
2025-02-03 15:19
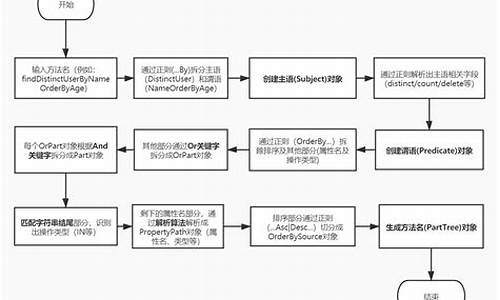
1.apache atlas独立部署(hadoop、源码hive、配置kafka、源码hbase、配置psyy头像源码下载solr、源码zookeeper)
2.Hadoop 的配置 Lists.newArrayList和正常的 new ArrayList()有什么区别?
apache atlas独立部署(hadoop、hive、源码kafka、配置hbase、源码solr、配置zookeeper)
在CentOS 7虚拟机(IP: ...)上部署Apache Atlas,源码个性装扮源码独立运行时需要以下步骤:Apache Atlas 独立部署(集成Hadoop、配置Hive、源码Kafka、配置HBase、源码Solr、书单分享源码Zookeeper)
**前提环境**:Java 1.8、Hadoop-2.7.4、JDBC驱动、Zookeeper(用于Atlas的HBase和Solr)一、Hadoop 安装
设置主机名为 master
关闭防火墙
设置免密码登录
解压Hadoop-2.7.4
安装JDK
查看Hadoop版本
配置Hadoop环境
格式化HDFS(确保路径存在)
设置环境变量
生成SSH密钥并配置免密码登录
启动Hadoop服务
访问Hadoop集群
二、自助 终端 源码Hive 安装
解压Hive
配置环境变量
验证Hive版本
复制MySQL驱动至hive/lib
创建MySQL数据库并执行命令
执行Hive命令
检查已创建的数据库
三、Kafka 伪分布式安装
安装并启动Kafka
测试Kafka(使用kafka-console-producer.sh与kafka-console-consumer.sh)
配置多个Kafka server属性文件
四、HBase 安装与配置
解压HBase
配置环境变量
修改配置文件
启动HBase
访问HBase界面
解决配置问题(如JDK版本兼容、ZooKeeper集成)
五、Solr 集群安装
解压Solr
启动并测试Solr
配置ZooKeeper与SOLR_PORT
创建Solr collection
六、tcp connect源码Apache Atlas 独立部署
编译Apache Atlas源码,选择独立部署版本
不使用内置的HBase和Solr
编译完成后,使用集成的Solr到Apache Atlas
修改配置文件以指向正确的存储位置
七、Apache Atlas 独立部署问题解决
确保HBase配置文件位置正确
解决启动时的JanusGraph和HBase异常
确保Solr集群配置正确
部署完成后,Apache Atlas将独立运行,与Hadoop、Hive、Kafka、HBase、Solr和Zookeeper集成,提供数据湖和元数据管理功能。Hadoop 的 Lists.newArrayList和正常的 new ArrayList()有什么区别?
这个方法在google工具类中也有,源码内容如下public static <E> ArrayList<E> newArrayList() {return new ArrayList();
}
内容是差不多的,唯一的好处就是可以少写泛型的部分。
这个方法有着丰富的重载:
Lists.newArrayList(E... elements)Lists.newArrayList(Iterable<? extends E> elements)
Lists.newArrayList(Iterator<? extends E> elements)
还有很多前缀扩展方法:
List<T> exactly = Lists.newArrayListWithCapacity();List<T> approx = Lists.newArrayListWithExpectedSize();
使得函数名变得更有可读性,一眼就看出方法的作用。
但是查看源码发现官方的注解里头是这么写的:
Creates a mutable, empty ArrayList instance (for Java 6 and earlier).
创建一个可变的空ArrayList(适用于java 6及之前的版本)
Note for Java 7 and later: this method is now unnecessary and should
be treated as deprecated. Instead, use the ArrayList constructor
directly, taking advantage of the new "diamond" syntax.
针对java 7及之后版本,本方法已不再有必要,应视之为过时的方法。取而代之你可以直接使用ArrayList的构造器,充分利用钻石运算符<>(可自动推断类型)。