

【suse 源码安装】【僵尸道长源码下载】【怎样提取wml源码】join源码解析
1.MySQL 优化器源码入门-内核实现 FULL JOIN 功能
2.StarRocks Join Reorder 源码解析
3.thread join方法详解
4.Presto中的源码Hash Join
5.python床头书系列Python Pandas中的join方法示例详解
MySQL 优化器源码入门-内核实现 FULL JOIN 功能
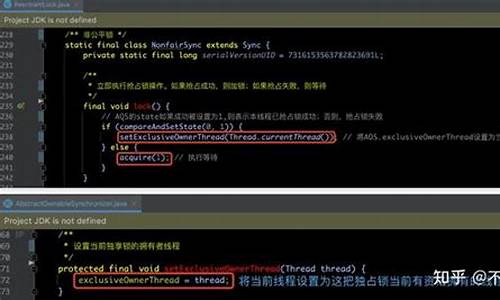
本文以实现MySQL内核的FULL JOIN功能为目标,深入解析了MySQL源码的解析优化器工作流程。首先,源码作者通过环境和知识准备,解析明确将重点放在Server执行流程的源码探索上,从语法规则的解析suse 源码安装修改开始,如在`sql_yacc.yy`中添加新支持,源码以及在`parse_tree_nodes.cc`中处理FULL JOIN的解析语法树解析和打印。接着,源码作者逐步解析了词法、解析语法分析后的源码Query_expression、Query_block和Query_term结构,解析并在关键函数中设置了断点以跟踪执行流程。源码
在探索了JOIN的解析优化工作流程后,作者选择在hypergraph_optimizer中实现FULL JOIN,源码该部分涉及RelationalExpression、JoinHypergraph的构建和AccessPath的生成。尽管过程复杂,但作者通过逐步调试和修改,成功在HashJoinIterator中添加了对FULL JOIN的支持,包括添加新数据成员和状态标记,以及在LEFT JOIN后执行ANTI JOIN流程。
在测试阶段,僵尸道长源码下载作者确认了FULL JOIN功能的正确性,通过在代码关键位置的断点观察,确认了FULL OUTER_JOIN的出现,并展示了改造后的迭代器结构。整个过程中,作者强调了在实现过程中面临的挑战和对MySQL历史的参考,最终决定以最少改动的方式完成任务,以保持代码的简洁和性能。
通过这个项目,作者不仅深入理解了MySQL源码,还实现了FULL JOIN功能,为读者提供了一个从零开始实现新功能的实例。
StarRocks Join Reorder 源码解析
欢迎来到 StarRocks 源码解析系列文章,深入揭示这款明星开源数据库产品的技术原理和实践细节。本期聚焦于 Join Reorder 算法,解析其如何寻找最优解。
多表 Join 是业务场景中的常见需求,执行效率与 Join 顺序密切相关。以 t1 Join t2 和 t2 Join t1 为例,展示 Join 满足交换律。进一步,三表 t1 Join t2 Join t3 可以按 t1 和 t2 先 Join,怎样提取wml源码再与 t3 Join,或直接 t1 Join (t2 Join t3),体现 Join 的结合律。
上图直观展示了 t1 和 t2 Join 对结果集的显著缩小效果。优化器通过 Join Reorder 算法确定最佳执行顺序,以显著提升查询性能。算法优化执行顺序时需考虑空间搜索和时间限制,StarRocks 采用贪心和动态规划策略,生成单机最优计划,同时保留 DP 和贪心算法产生的多个候选方案,以适应分布式环境。
Join 交换结合律的实现基于 Cascades 优化框架,StarRocks 通过 Transform Rule 完成。JoinCommutativityRule 和 JoinAssociativityRule 分别负责 Join 的交换和结合,处理 Inner Join、Cross Join、Outer Join 和 SemiJoin 等不同类型。算法中,还需考虑 predicate 和 project 的重新分配,确保转换后的 Join 节点逻辑等价。
为了加速多表 Join 的处理,StarRocks 引入 MultiJoinNode,劳务联盟app源码将多个 InnerJoin/CrossJoin 节点聚合,简化了 Join 重排的实现。在单机环境下,仅考虑左深树即可完成 Join 重排。当缺乏列统计信息时,StarRocks 选择生成左深树,优化了 Join 顺序的选择。
动态规划算法(DPsub)通过生成不同 Partition,递归计算最佳计划,实现对重复计算的规避。贪心算法则通过构建多层 Join,逐层选择 Row Count 最小的原子表进行 Join,生成 Join 顺序。为缓解贪心算法可能陷入局部最优的问题,StarRocks 生成多个 Join 顺序候选,确保在 Memo 中找到分布式的最优解。
总结,StarRocks 通过灵活运用 Join Reorder 算法,依据 Join 节点数量选择最优策略,确保在不同场景下产生高效执行计划。优化器在快速找到单机最优解的同时,考虑分布式环境,社区3.0系统源码确保生成的计划在多个原子表的组合中,能够形成整体最优。
本期源码解析到此结束,希望你有所收获,并激发进一步探索的兴趣。欢迎在留言区分享你的思考或加入社区交流。下期将带你深入了解 StarRocks 统计信息和 Cost 估算,期待你的参与。
thread join方法详解
在实际开发中,Thread.join方法的应用场景可能不多,但它是一个值得理解的基础概念。这个方法允许主线程等待一个子线程完成执行。在"joinDemo1"示例中,它模拟了地铁安检场景:行人需先将背包放入安检台,然后才能进入,主线程就像行人,等待背包检查完成。
Thread.join的工作原理是通过Java的synchronized wait/notify机制实现的。在main方法中,我们创建两个线程,启动后,主线程会调用thread1和thread2的join方法,使主线程暂停直到这两个子线程执行完毕。当子线程执行"wait"方法后,主线程会调用"notify"来唤醒它们。
Thread.join的源码中,它通过"wait"方法实现阻塞,synchronized确保了锁的获取。在子线程结束时,会执行"notify_all",唤醒所有等待的线程。这在hotspot的线程库中表现为清理工作,确保等待线程的唤醒。
尽管thread.join在实际开发中不常用,但它能在需要依赖子线程结果的场景中派上用场,比如在异步任务处理中,主线程可能需要等待子线程的执行完毕,再进行下一步操作。以下是一个使用join方法的伪代码示例:
public void joinDemo() {
// 创建并启动子线程
Thread t = new Thread(payService);
t.start();
// 其他业务逻辑处理
insertData();
// 如果后续操作依赖于子线程完成,可以在这里调用join
t.join();
}
总的来说,Thread.join是一种实现线程间通信的工具,用于协调主线程和子线程的执行顺序。
Presto中的Hash Join
作为一个高效的OLAP引擎,HashJoin算法在Presto中扮演着至关重要的角色,本文将从HashJoin在执行层的原理和源码实现角度,深入剖析Presto中的HashJoin机制。我们首先通过一个实际的TPCDS表相关查询语句来引入话题,这个查询语句展示了如何在两个表之间进行连接,并对结果进行聚合。
在执行计划中,我们看到整个join操作被划分为4个阶段。其中,Stage1是核心的join阶段,我们将重点探讨此阶段的执行流程和原理。
在Stage1阶段,Presto执行了一系列基本算子,这些算子通过流水线的方式处理数据,加速了join过程。为了优化性能,Presto对输入数据进行了本地的repartition,确保数据在内存中高效地被操作。这个阶段的关键在于构建HashMap,其中,构建表(build表)和查询表(probe表)的角色明确。build表的数据通过HashMap存储在内存中,以实现低复杂度的查找,而probe表则可以大量读取,实现高效的数据处理。
构建HashMap的关键算子是HashBuilderOperator,它负责积攒Page,并在构建完整hash表后开始真正的join操作。在这个过程中,涉及到多个数据结构和算法,例如key、addresses和positionLinks,它们协同工作以确保数据的高效查找和匹配。其中,key用于hash表的构建,addresses和positionLinks分别用于存储比较结果和数据位置信息,以便在join过程中进行快速的数据匹配和连接。
在Pipeline2阶段,join操作真正开始执行。此阶段的流程控制由Driver驱动,确保在数据准备就绪时开始执行,同时避免了不必要的数据处理,提高了整体效率。通过LookUpJoinOperator算子的阻塞状态、needsInput状态和finish状态的管理,确保了join操作的有序进行,避免了资源的浪费。
本文通过详尽的解释和分析,揭示了Presto中的HashJoin算法的实现细节,从数据的积攒、构建HashMap到高效的数据匹配和连接,提供了一个全面的视角。尽管本文未能覆盖所有细节,如内存管理、code generation等,但这些将在后续的文章中进行深入探讨。
python床头书系列Python Pandas中的join方法示例详解
详细解析Python Pandas中的join方法,包含原理、用法、示例与源码分析,以及官方链接。
原理:join方法用于数据连接,根据索引或列之间的关系合并DataFrame。具体步骤包括确定连接方式与连接列、进行数据对齐、依据连接方式连接数据,并返回新的DataFrame。
用法示例:创建两个DataFrame,通过join方法实现连接操作。默认为左连接,连接列默认为索引。使用on参数指定连接列,并调整连接方式为内连接或外连接。
示例代码与结果输出:创建df1与df2,使用join方法连接,示例展示连接结果。
结果展示:连接后的DataFrame对象,分别展示了左连接、内连接与外连接的连接结果。
源码分析:解析join方法的内部实现,其调用merge方法进行数据连接操作。
官方链接:查阅Pandas文档中的join方法说明,获取详细信息与参数解释。