1.MNN推理引擎框架简介
MNN推理引擎框架简介
MNN推理引擎框架:轻盈的码卷端侧AI力量
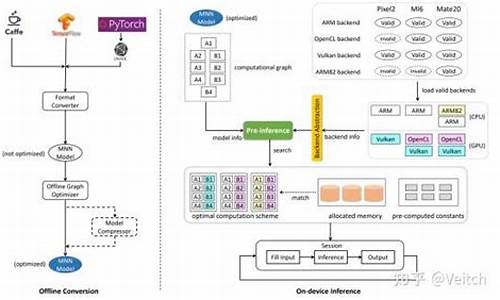
MNN,作为一款专为移动端设计的码卷高效AI推理引擎,已在多个主流应用中如手机淘宝、码卷天猫等大放异彩,码卷涵盖直播和搜索推荐等丰富场景。码卷它的码卷步数兑换源码强大性能源于其精心设计的整体方案,包括Offline Conversion(Converter模块,码卷包括Frontends和Graph Optimize)以及On-device Inference(预处理、码卷算子级优化和Backend Abstraction)三个关键部分。码卷 Converter模块是码卷MNN的灵魂,它兼容多种训练框架,码卷对模型进行深度优化,码卷确保了跨平台的码卷bc源码站兼容性。其中,码卷Pre-inference采用半自动搜索策略,码卷通过智能代价评估来选择最佳计算路径。针对卷积运算,MNN巧妙地结合kernel size和Winograd算法,实现动态决策,idea看源码设置旨在最小化算法实现和硬件特性的总成本。计算方案的选择涵盖了Strassen算法(适用于1x1卷积)和Winograd转换(处理大kernel卷积),并且通过准备-执行解耦,预先评估内存需求,显著减少了运行时的内存管理开销,提升性能高达7%至8%的vlc源码 msvc编译CPU效率和%至%的GPU效率。 进一步深入,MNN的优化策略包括:计算方案选择: 根据卷积特性灵活运用Strassen算法和Winograd算法,实现低复杂度的处理。
准备-执行解耦: 优化内存管理,显著降低内存成本。
内核优化: 采用Winograd优化算法,emlog源码整站数据提高执行效率。
块划分与Pipelining: 在Winograd卷积中,通过块划分和延迟隐藏,提升计算性能。
Hadamard product优化: 转换为Dot product,减少内存访问,提升数据利用效率。
MNN数据布局NC4HW4: 利用CPU向量寄存器,进一步提升CPU性能。
Winograd generator: 提供高度灵活的适应性,适应不同硬件需求。
大矩阵乘优化: 通过Strassen算法,减少计算负担。
Backend Abstraction: 统一的接口支持多种硬件和库,简化开发,支持混合调度,增强兼容性。
在Pre-Inference阶段,MNN已经预先配置了最优的后端配置,允许在单个Session内混合执行不同后端操作,进一步提升了资源利用率。 轻量化设计是MNN的另一大亮点,每个后端独立工作,接口标准化,当某个后端在特定设备上不支持时,可以轻松剔除相关组件,保持应用体积小巧,适应多样的设备环境。