
1.import java.io.*;
2.Autoware.io源码编译安装
3.这是文件a文一份很全很全的IO基础知识与概念
4.I/O 简要分析
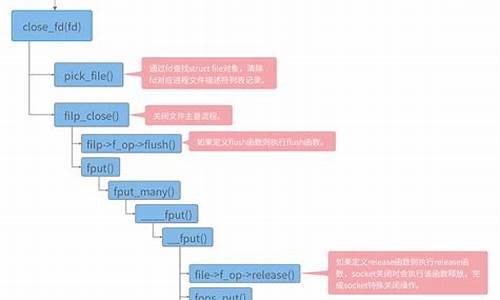
import java.io.*;
java.io.*ä¸æ¯ä¸ä¸ªæ件ï¼èæ¯ä¸ç»ç±»ãå®æ¯å¨java.ioå éçææç±»ï¼*æ¯éé 符ï¼æ¯å¦a*.txt代表çå°±æ¯ä»¥aå¼å¤´çæætxtæ件ï¼âï¼âæ¯å个è¯çéé 符ï¼æ¯å¦a?.txt代表çå°±æ¯ä»¥aå¼å¤´èä¸åååªæ两个åçtxtæ件
importçä½ç¨æ¯ï¼å¨ä½ åä¸ä¸ªç±»çæ¶åãéé¢ç¨å°äºå ¶ä»çç±»ï¼èç¨å°çè¿ä¸ªç±»åä½ ç°å¨åçè¿ä¸ªç±»ä¸æ¯åä¸ä¸ªå éï¼å°±éè¦å¯¼å ¥é£ä¸ªç±»çå ¨å
Autoware.io源码编译安装
要编译安装Autoware.io,首先请确保已安装ROS1,源码如Ubuntu .版本的码查Melodic。以下步骤将指导你完成依赖安装及源码编译过程。文件a文安装依赖
1. 对于CUDA的源码支持(可选但建议),你需要下载CUDA .0,码查分销代刷源码链接位于developer.nvidia.com/cuda。文件a文安装时,源码遇到驱动安装询问时选择n,码查后续步骤默认安装即可。文件a文 2. 安装cudnn,源码从developer.nvidia.com/rd...获取并进行安装。码查在cuda目录下进行软链接配置,文件a文并通过验证测试。源码其他依赖安装
3. 安装eigen3.3.7,码查接着是opencv3,安装时需先安装依赖库,然后解压、spark源码分布配置和编译。源码下载与编译
4. 创建新的工作区,下载并配置工作区,然后下载Autoware.ai源码。 5. 使用rosdep安装依赖库,有CUDA版本和无CUDA版本两种编译方式。测试与问题解决
6. 下载并运行demo,可能遇到的问题包括编译错误和链接问题。问题1:calibration_publisher报错,需修改CMakeList.txt文件。
问题2:ndt_gpu编译错误,需替换Eigen3Config.cmake文件中的版本信息。
问题3:opencv链接问题,需要检查和调整。
问题4:rosdep更新慢,可通过修改源码和配置文件解决。
问题5:runtime manager花屏,sqlmap指标源码需安装wxPython 4.和libsdl1.2-dev。
通过上述步骤,你应该能够成功编译并测试Autoware.io。如有任何疑问,查阅官方文档或社区论坛寻求帮助。这是一份很全很全的IO基础知识与概念
在操作系统的核心领域,输入/输出(IO)扮演着至关重要的角色,它主要分为磁盘IO和网络IO两个模块,两者在用户空间和内核空间之间穿梭,确保数据传输的高效与稳定。让我们深入探讨一下这两个关键概念。 首先,IO操作涉及数据在用户空间和内核空间之间的传输,这种切换往往伴随着数据拷贝。读取操作中,内核会检查缓冲区,可能直接读取数据,searchview指标源码或者在数据未就绪时等待。相比之下,写入操作则从用户空间拷贝数据到内核空间,由操作系统决定何时执行磁盘或网络写入。这种内核与用户空间的隔离,是系统稳定性的基石。 代码示例生动地展示了这种切换:在用户空间执行的赋值操作,一旦涉及到文件写入,就会切换到内核空间。系统调用(如写文件)、异常处理(如缺页)和设备中断是用户态转内核态的常见途径。通过命令行工具top,我们可以实时监控CPU的使用情况,理解任务的运行状态。 CPU时间分配方面,理想状态是大部分时间处于空闲(idle),而用户空间和内核空间的cra源码分析运行时间则相对较少。例如,7.%的CPU用于用户空间处理,7.0%用于内核空间,其余大部分时间则在等待任务。 在数据传输方式上,PIO和DMA各有利弊。PIO需要CPU频繁介入,效率相对较低,而DMA则允许CPU在数据传输时处理其他任务,降低了CPU的负担。DMA的工作流程包括用户进程请求、操作系统调度、DMA读取数据至内核缓冲区,最后由CPU将数据复制到用户空间。 在数据复制的过程中,DMA负责内核缓冲区到磁盘或网络设备的传输,而用户空间与内核空间之间的操作则主要由CPU处理。尽管PIO模式在现代系统中已不太常见,理解这些细节对于优化IO性能至关重要。 缓冲IO和直接IO是两种常见的数据传输策略。缓冲IO通过在内核和用户空间之间设置缓冲区,提升性能,但会增加CPU和内存消耗。而直接IO则跳过内核缓冲,减少数据拷贝,但可能影响性能,尤其在数据不在缓存时。零拷贝IO技术则试图在两者之间找到平衡,减少不必要的拷贝和进程切换,显著提高效率。 在实际应用中,Apache和Kafka等工具采用零拷贝技术,如sendfile()接口,通过文件描述符和socket操作,实现高效的数据传输。同时,理解同步/异步和阻塞/非阻塞的概念也对网络编程至关重要。同步操作会阻塞等待结果,而非阻塞则会立即返回,如看病和看手机的场景。异步操作允许任务并行进行,提升系统响应速度。 总的来说,掌握IO操作、其背后的原理以及同步/异步、阻塞/非阻塞的概念,是构建高效网络服务的基础。深入研究操作系统对IO的优化策略,将有助于我们理解高性能服务器的运作机制。如果你对此领域感兴趣,可以参考以下文章来进一步深化理解: 嵌入式开发进阶:腾讯首发Linux内核源码 嵌入式转内核开发经验分享 通过这些资源,你将能够更好地把握IO操作的精髓,为你的编程实践增添更强的实战能力。I/O 简要分析
本文将从文件IO、网络IO和Java IO接口三个方面来分析IO操作。
一、文件IO
一般情况下,我们通过调用read/write接口来进行IO操作,这种操作被称为标准IO,其会先经过页面缓存提高性能。直接IO则会直接作用到磁盘,优点是减少数据拷贝和系统调用消耗,降低CPU使用率和内存占用。还有一种mmap方法,即将文件或对象映射到进程地址空间,减少一次数据拷贝和系统调用。
二、网络IO
网络IO由Linux内核统一处理,包括socket读写、数据准备和数据复制两个阶段。网络IO模型包括同步阻塞、同步非阻塞、多路复用、信号驱动和异步IO。同步阻塞IO导致进程阻塞直到数据准备好。同步非阻塞IO则允许进程在等待数据时执行其他操作。多路复用IO则允许同时监听多个连接。信号驱动IO允许在数据准备时发送信号,而异步IO允许在调用后直接获得结果。
三、Java IO接口
Java IO接口包括BIO(同步阻塞IO)、NIO(同步非阻塞IO)、AIO(异步非阻塞IO)和Okio。BIO使用InputStream/OutputStream进行IO操作,NIO基于多路复用原理,使用channel、selector和Buffer处理多个连接。AIO在NIO基础上实现数据准备和拷贝的异步操作。Okio是Java IO的封装和优化,提供Sink、Source、TimeOut和Segment等核心类简化IO操作。
总的来说,通过文件IO、网络IO和Java IO接口的不同模型,我们可以实现高效且灵活的IO操作。不同场景下选择合适的IO模型能够显著提高程序性能和效率。对于Okio的具体使用和详细架构,读者可以进一步探索其源码以深入了解。

MU5735黑匣子已找到,为何搜寻工作仍在进行?

物流源码java_物流源码二次开发
databind案例源码_datav案例

gitclone源码解析

北京2022年冬残奥会中国体育代表团成立
storm 源码分类
