
1.UE4源码剖析——异步与并行 中篇 之 Thread
2.HashSet 源码分析及线程安全问题
3.synchronize底层原理
4.老生常谈线程基础的线程线程几个问题
5.java线程池(一):java线程池基本使用及Executors
6.polars源码解析——DataFrame

UE4源码剖析——异步与并行 中篇 之 Thread
我们知道UE中的异步框架分为TaskGraph与Thread两种,上篇教程我们学习了TaskGraph,底层底层它擅长处理有依赖关系的源码原理短任务;本篇教程我们将学习Thread,它与TaskGraph相反,线程线程它更擅长于处理长任务。底层底层而下一篇文章,源码原理php远程视频源码我们则会承接Thread,线程线程去学习一下引擎中一些重要的底层底层线程。
Thread擅长处理长任务,源码原理从长任务生命周期这个层面来看,线程线程我们可以先把长任务分为两类:常驻型长任务与非常驻型长任务。底层底层
常驻型长任务侧重于并行,源码原理通常用于监听式服务,线程线程例如网络传输,底层底层使用单独的源码原理线程对网络进行监听,每当有网络数据包到达时,线程接收并处理后,不会立即结束,而是重置部分状态,继续监听,等待下一轮数据包。
非常驻型长任务侧重于异步,通常用于数据处理,例如主线程为了提高性能,避免卡顿,会将一些重负载的运算任务分发给分线程处理,可能分批给多条分线程,主线程继续运行其他逻辑。任务处理完成后,将结果返回给主线程,分线程可销毁。
接下来,我们通过两个例子学习Thread的使用。
计算由N到M(N和M为大数字)所有数字的和。使用Thread异步调用,将计算操作交由分线程执行,计算完成后再通知主线程结果,代码实现如下:
逻辑分为两部分:启动分线程计算数字和,使用Async函数,参数为EAsyncExecution::Thread,创建新线程执行。学习Async函数用法,该函数返回TFuture对象,代表未来状态,当前无法获取结果,但在未来某个时刻状态变为Ready,此时可通过TFuture获取结果。
主线程注册回调,等待分线程计算完成,使用TFuture的Then函数,完成时触发注册的回调,也可使用Wait系列函数等待计算完成。
接下来学习常驻型任务使用。
定义玩家血量上限点,当前点,当血量未满时,每0.2秒恢复1点血量。代码实现分为创建生命治疗仪FRunnable对象、重写Run函数、创建FRunnableThread线程、网址 源码测试恢复功能和释放线程资源。
生命治疗仪创建与测试完整代码如下,可验证生命恢复功能和暂停与恢复。
UE4中的FRunnable与FRunnableThread提供创建常驻型任务所需接口。无论是常驻型还是非常驻型,底层实现相同,都是使用FRunnableThread线程。
FRunnableThread线程结构包含标识符、逻辑功能、效率与性能、辅助调试字段。线程创建与生命周期分为创建FRunnable类对象、创建FRunnableThread对象两步,通过FRunnable的生命周期管理实现线程运行与停止。
UE4线程管理流程包括继承并创建FRunnable类对象、创建FRunnableThread对象,生命治疗仪线程创建代码。
UE4中的几种异步方式底层使用线程实现,学习了线程类型、创建、生命周期、销毁方法,为下篇学习引擎特殊线程打下基础。
HashSet 源码分析及线程安全问题
HashSet,作为集合框架中的重要成员,其底层采用 HashMap 进行数据存储,简化了集合操作的复杂性。深入理解 HashMap,将有助于我们洞察 HashSet 的源码精髓。
一、HashSet 定义详解
1.1 构造函数
HashSet 提供了多种构造函数,允许用户根据需求灵活创建实例。例如,使用 HashSet() 创建一个空 HashSet,或者通过 Collection 参数构造,实现与现有集合的合并。
1.2 属性定义
HashSet 主要属性包括容量(容量决定 HashMap 的大小)和负载因子(控制容量的扩展阈值),确保其高效存储和检索数据。
二、操作函数
2.1 add() - 向集合中添加元素,若元素已存在则不添加。
2.2 size() - 返回集合中元素的数量。
2.3 isEmpty() - 判断集合是否为空。
2.4 contains() - 检查集合中是否包含指定元素。
2.5 remove() - 删除集合中的指定元素。
2.6 clear() - 清空集合,使其变为空。
2.7 iterator() - 返回一个可迭代对象,用于遍历集合中的元素。
2.8 spliterator() - 返回一个 Spliterator,用于更高效地遍历集合。
三、HashSet 线程安全吗?
3.1 线程安全解决
HashSet 不是线程安全的,它不保证在多线程环境下的并发访问。为了确保线程安全,用户需要采用同步机制,如使用 Collections.synchronizedSet() 方法将 HashSet 转换为同步集合。同时,利用并发集合如 CopyOnWriteArrayList 和 ConcurrentHashMap 等,源码11011000可以实现更高效、安全的并发操作。
synchronize底层原理
synchronize底层原理是什么?我们先通过反编译下面的代码来看看Synchronized是如何实现对代码块进行同步的:
1 package com.paddx.test.concurrent;
2
3 public class SynchronizedDemo {
4 public void method() {
5 synchronized (this) {
6 System.out.println(Method 1 start);
7 }
8 }
9 }
反编译结果:
关于这两条指令的作用,我们直接参考JVM规范中描述:
monitorenter :
Each object is associated with a monitor. A monitor is locked if and only if it has an owner. The thread that executes monitorenter attempts to gain ownership of the monitor associated with objectref, as follows:
If the entry count of the monitor associated with objectref is zero, the thread enters the monitor and sets its entry count to one. The thread is then the owner of the monitor.
If the thread already owns the monitor associated with objectref, it reenters the monitor, incrementing its entry count.
If another thread already owns the monitor associated with objectref, the thread blocks until the monitors entry count is zero, then tries again to gain ownership.
这段话的大概意思为:
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
monitorexit:
The thread that executes monitorexit must be the owner of the monitor associated with the instance referenced by objectref.
The thread decrements the entry count of the monitor associated with objectref. If as a result the value of the entry count is zero, the thread exits the monitor and is no longer its owner. Other threads that are blocking to enter the monitor are allowed to attempt to do so.
这段话的大概意思为:
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
通过这两段描述,我们应该能很清楚的看出Synchronized的实现原理,Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
我们再来看一下同步方法的反编译结果:
源代码:
1 package com.paddx.test.concurrent;
2
3 public class SynchronizedMethod {
4 public synchronized void method() {
5 System.out.println(Hello World!);
6 }
7 }
反编译结果:
从反编译的结果来看,方法的同步并没有通过指令monitorenter和monitorexit来完成(理论上其实也可以通过这两条指令来实现),不过相对于普通方法,其常量池中多了ACC_SYNCHRONIZED标示符。JVM就是根据该标示符来实现方法的同步的:当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。 其实本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。
老生常谈线程基础的几个问题
实现线程只有一种方式
我们知道启动线程至少可以通过以下四种方式:
实现Runnable接口
继承Thread类
线程池创建线程
带返回值的Callable创建线程
但是看它们的底层就一种方式,就是通过newThread()实现,其他的只不过在它的上面做了层封装。
实现Runnable接口要比继承Thread类的更好:
结构上分工更明确,线程本身属性和任务逻辑解耦。
某些情况下性能更好,直接把任务交给线程池执行,无需再次newThread()。
可拓展性更好:实现接口可以多个,而继承只能单继承。
有的时候可能会问到启动线程为什么是start()方法,而不是run()方法,这个问题很简单,ustd源码执行run()方法其实就是在执行一个类的普通方法,并没有启动一个线程,而start()方法点进去看是一个native方法。
当我们在执行java中的start()方法的时候,它的底层会调JVM由c++编写的代码Thread::start,然后c++代码再调操作系统的create_thread创建线程,创建完线程以后并不会马上运行,要等待CPU的调度。CPU的调度算法有很多,比如先来先服务调度算法(FIFO),最短优先(就是对短作业的优先调度)、时间片轮转调度等。如下图所示:
线程的状态在Java中线程的生命周期中一共有6种状态。
NEW:初始状态,线程被构建,但是还没有调用start方法
RUNNABLE:运行状态,JAVA线程把操作系统中的就绪和运行两种状态统一称为运行中
BLOCKED:阻塞状态,表示线程进入等待状态,也就是线程因为某种原因放弃了CPU使用权
WAITING:等待状态
TIMED_WAITING:超时等待状态,超时以后自动返回
TERMINATED:终止状态,表示当前线程执行完毕
当然这也不是我说的,源码中就是这么定义的:
publicenumState{ /***Threadstateforathreadwhichhasnotyetstarted.*/NEW,/***Threadstateforarunnablethread.Athreadintherunnable*stateisexecutingintheJavavirtualmachinebutitmay*bewaitingforotherresourcesfromtheoperatingsystem*suchasprocessor.*/RUNNABLE,/***Threadstateforathreadblockedwaitingforamonitorlock.*Athreadintheblockedstateiswaitingforamonitorlock*toenterasynchronizedblock/methodor*reenterasynchronizedblock/methodaftercalling*{ @linkObject#wait()Object.wait}.*/BLOCKED,/***Threadstateforawaitingthread.*Athreadisinthewaitingstateduetocallingoneofthe*followingmethods:*<ul>*<li>{ @linkObject#wait()Object.wait}withnotimeout</li>*<li>{ @link#join()Thread.join}withnotimeout</li>*<li>{ @linkLockSupport#park()LockSupport.park}</li>*</ul>**<p>Athreadinthewaitingstateiswaitingforanotherthreadto*performaparticularaction.**Forexample,athreadthathascalled<tt>Object.wait()</tt>*onanobjectiswaitingforanotherthreadtocall*<tt>Object.notify()</tt>or<tt>Object.notifyAll()</tt>on*thatobject.Athreadthathascalled<tt>Thread.join()</tt>*iswaitingforaspecifiedthreadtoterminate.*/WAITING,/***Threadstateforawaitingthreadwithaspecifiedwaitingtime.*Athreadisinthetimedwaitingstateduetocallingoneof*thefollowingmethodswithaspecifiedpositivewaitingtime:*<ul>*<li>{ @link#sleepThread.sleep}</li>*<li>{ @linkObject#wait(long)Object.wait}withtimeout</li>*<li>{ @link#join(long)Thread.join}withtimeout</li>*<li>{ @linkLockSupport#parkNanosLockSupport.parkNanos}</li>*<li>{ @linkLockSupport#parkUntilLockSupport.parkUntil}</li>*</ul>*/TIMED_WAITING,/***Threadstateforaterminatedthread.*Thethreadhascompletedexecution.*/TERMINATED;}下面是这六种状态的转换:
New新创建New表示线程被创建但尚未启动的状态:当我们用newThread()新建一个线程时,如果线程没有开始调用start()方法,那么此时它的状态就是New。而一旦线程调用了start(),它的状态就会从New变成Runnable。
Runnable运行状态Java中的Runable状态对应操作系统线程状态中的两种状态,分别是Running和Ready,也就是说,Java中处于Runnable状态的线程有可能正在执行,也有可能没有正在执行,正在等待被分配CPU资源。
如果一个正在运行的线程是Runnable状态,当它运行到任务的一半时,执行该线程的CPU被调度去做其他事情,导致该线程暂时不运行,它的状态依然不变,还是Runnable,因为它有可能随时被调度回来继续执行任务。
在Java中Blocked、Waiting、TimedWaiting,这三种状态统称为阻塞状态,下面分别来看下。
Blocked从上图可以看出,从Runnable状态进入Blocked状态只有一种可能,就是进入synchronized保护的代码时没有抢到monitor锁,jvm会把当前的线程放入到锁池中。当处于Blocked的线程抢到monitor锁,就会从Blocked状态回到Runnable状态。
Waiting状态我们看上图,线程进入Waiting状态有三种可能。
没有设置Timeout参数的Object.wait()方法,jvm会把当前线程放入到等待队列。
没有设置Timeout参数的Thread.join()方法。
LockSupport.park()方法。
Blocked与Waiting的区别是Blocked在等待其他线程释放monitor锁,而Waiting则是在等待某个条件,比如join的线程执行完毕,或者是expam源码notify()/notifyAll()。
当执行了LockSupport.unpark(),或者join的线程运行结束,或者被中断时可以进入Runnable状态。当调用notify()或notifyAll()来唤醒它,它会直接进入Blocked状态,因为唤醒Waiting状态的线程能够调用notify()或notifyAll(),肯定是已经持有了monitor锁,这时候处于Waiting状态的线程没有拿到monitor锁,就会进入Blocked状态,直到执行了notify()/notifyAll()唤醒它的线程执行完毕并释放monitor锁,才可能轮到它去抢夺这把锁,如果它能抢到,就会从Blocked状态回到Runnable状态。
TimedWaiting状态在Waiting上面是TimedWaiting状态,这两个状态是非常相似的,区别仅在于有没有时间限制,TimedWaiting会等待超时,由系统自动唤醒,或者在超时前被唤醒信号唤醒。
以下情况会让线程进入TimedWaiting状态。
设置了时间参数的Thread.sleep(longmillis)方法。
设置了时间参数的Object.wait(longtimeout)方法。
设置了时间参数的Thread.join(longmillis)方法。
设置了时间参数的LockSupport.parkNanos(longnanos)。
LockSupport.parkUntil(longdeadline)方法。
在TimedWaiting中执行notify()和notifyAll()也是一样的道理,它们会先进入Blocked状态,然后抢夺锁成功后,再回到Runnable状态。当然,如果它的超时时间到了且能直接获取到锁/join的线程运行结束/被中断/调用了LockSupport.unpark(),会直接恢复到Runnable状态,而无需经历Blocked状态。
Terminated终止Terminated终止状态,要想进入这个状态有两种可能。
run()方法执行完毕,线程正常退出。
出现一个没有捕获的异常,终止了run()方法,最终导致意外终止。
线程的停止interrupt我们知道Thread提供了线程的一些操作方法,比如stop(),suspend()和resume(),这些方法已经被Java直接标记为@Deprecated,这就说明这些方法是不建议大家使用的。
因为stop()会直接把线程停止,这样就没有给线程足够的时间来处理想要在停止前保存数据的逻辑,任务戛然而止,会导致出现数据完整性等问题。这种行为类似于在linux系统中执行kill-9类似,它是一种不安全的操作。
而对于suspend()和resume()而言,它们的问题在于如果线程调用suspend(),它并不会释放锁,就开始进入休眠,但此时有可能仍持有锁,这样就容易导致死锁问题,因为这把锁在线程被resume()之前,是不会被释放的。
interrupt最正确的停止线程的方式是使用interrupt,但interrupt仅仅起到通知被停止线程的作用。而对于被停止的线程而言,它拥有完全的自主权,它既可以选择立即停止,也可以选择一段时间后停止,也可以选择压根不停止。
下面我们来看下例子:
publicclassInterruptExampleimplementsRunnable{ //interrupt相当于定义一个volatile的变量//volatilebooleanflag=false;publicstaticvoidmain(String[]args)throwsInterruptedException{ Threadt1=newThread(newInterruptExample());t1.start();Thread.sleep(5);//Main线程来决定t1线程的停止,发送一个中断信号,中断标记变为truet1.interrupt();}@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ System.out.println(Thread.currentThread().getName()+"--");}}}执行一下,运行了一会就停止了
主线程在调用t1的interrupt()之后,这个线程的中断标记位就会被设置成true。每个线程都有这样的标记位,当线程执行时,会定期检查这个标记位,如果标记位被设置成true,就说明有程序想终止该线程。在while循环体判断语句中,通过Thread.currentThread().isInterrupt()判断线程是否被中断,如果被置为true了,则跳出循环,线程就结束了,这个就是interrupt的简单用法。
阻塞状态下的线程中断下面来看第二个例子,在循环中加了Thread.sleep秒。
publicclassInterruptSleepExampleimplementsRunnable{ //interrupt相当于定义一个volatile的变量//volatilebooleanflag=false;publicstaticvoidmain(String[]args)throwsInterruptedException{ Threadt1=newThread(newInterruptSleepExample());t1.start();Thread.sleep(5);//Main线程来决定t1线程的停止,发送一个中断信号,中断标记变为truet1.interrupt();}@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ try{ Thread.sleep();}catch(InterruptedExceptione){ //中断标记变为falsee.printStackTrace();}System.out.println(Thread.currentThread().getName()+"--");}}}再来看下运行结果,卡主了,并没有停止。这是因为main线程调用了t1.interrupt(),此时t1正在sleep中,这时候是接收不到中断信号的,要sleep结束以后才能收到。这样的中断太不及时了,我让你中断了,你缺还在傻傻的sleep中。
Java开发的设计者已经考虑到了这一点,sleep、wait等方法可以让线程进入阻塞的方法使线程休眠了,而处于休眠中的线程被中断,那么线程是可以感受到中断信号的,并且会抛出一个InterruptedException异常,同时清除中断信号,将中断标记位设置成false。
这时候有几种做法:
直接捕获异常,不做处理,e.printStackTrace();打印下信息
将异常往外抛出,即在方法上throwsInterruptedException
再次中断,代码如下,加上Thread.currentThread().interrupt();
@Overridepublicvoidrun(){ while(!Thread.currentThread().isInterrupted()){ try{ Thread.sleep();}catch(InterruptedExceptione){ //中断标记变为falsee.printStackTrace();//把中断标记修改为trueThread.currentThread().interrupt();}System.out.println(Thread.currentThread().getName()+"--");}}这时候线程感受到了,我们人为的再把中断标记修改为true,线程就能停止了。一般情况下我们操作线程很少会用到interrupt,因为大多数情况下我们用的是线程池,线程池已经帮我封装好了,但是这方面的知识还是需要掌握的。感谢收看,多多点赞~
作者:小杰博士
java线程池(一):java线程池基本使用及Executors
@[toc] 在前面学习线程组的时候就提到过线程池。实际上线程组在我们的日常工作中已经不太会用到,但是线程池恰恰相反,是我们日常工作中必不可少的工具之一。现在开始对线程池的使用,以及底层ThreadPoolExecutor的源码进行分析。1.为什么需要线程池我们在前面对线程基础以及线程的生命周期有过详细介绍。一个基本的常识就是,线程是一个特殊的对象,其底层是依赖于JVM的native方法,在jvm虚拟机内部实现的。线程与普通对象不一样的地方在于,除了需要在堆上分配对象之外,还需要给每个线程分配一个线程栈、以及本地方法栈、程序计数器等线程的私有空间。线程的初始化工作相对于线程执行的大多数任务而言,都是一个耗时比较长的工作。这与数据库使用一样。有时候我们连接数据库,仅仅只是为了执行一条很小的sql语句。但是在我们日常的开发工作中,我们的绝大部分工作内容,都会分解为一个个短小的执行任务来执行。这样才能更加合理的复用资源。这种思想就与我们之前提到的协程一样。任务要尽可能的小。但是在java中,任务不可能像协程那样拆分得那么细。那么试想,如果说,有一个已经初始化好的很多线程,在随时待命,那么当我们有任务提交的时候,这些线程就可以立即工作,无缝接管我们的任务请求。那么效率就会大大增加。这些个线程可以处理任何任务。这样一来我们就把实际的任务与线程本身进行了解耦。从而将这些线程实现了复用。 这种复用的一次创建,可以重复使用的池化的线程对象就被成为线程池。 在线程池中,我们的线程是可以复用的,不用每次都创建一个新的线程。减少了创建和销毁线程的时间开销。 同时,线程池还具有队列缓冲策略,拒绝机制和动态线程管理。可以实现线程环境的隔离。当一个线程有问题的时候,也不会对其他的线程造成影响。 以上就是我们使用线程池的原因。一句话来概括就是资源复用,降低开销。
2.java中线程池的实现在java中,线程池的主要接口是Executor和ExecutorService在这两个接口中分别对线程池的行为进行了约束,最主要的是在ExecutorService。之后,线程池的实际实现类是AbstractExecutorService类。这个类有三个主要的实现类,ThreadpoolExecutorService、ForkJoinPool以及DelegatedExecutorService。
后面我们将对这三种最主要的实现类的源码以及实现机制进行分析。
3.创建线程的工厂方法Executors在java中, 已经给我们提供了创建线程池的工厂方法类Executors。通过这个类以静态方法的模式可以为我们创建大多数线程池。Executors提供了5种创建线程池的方式,我们先来看看这个类提供的工厂方法。
3.1 newFixedThreadPool/** * Creates a thread pool that reuses a fixed number of threads * operating off a shared unbounded queue.At any point, at most * { @code nThreads} threads will be active processing tasks. * If additional tasks are submitted when all threads are active, * they will wait in the queue until a thread is available. * If any thread terminates due to a failure during execution * prior to shutdown, a new one will take its place if needed to * execute subsequent tasks.The threads in the pool will exist * until it is explicitly { @link ExecutorService#shutdown shutdown}. * * @param nThreads the number of threads in the pool * @return the newly created thread pool * @throws IllegalArgumentException if { @code nThreads <= 0} */public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}这个方法能够创建一个固定线程数量的无界队列的线程池。参数nthreads是最多可同时处理的活动的线程数。如果在所有线程都在处理任务的情况下,提交了其他的任务,那么这些任务将处于等待队列中。直到有一个线程可用为止。如果任何线程在关闭之前的执行过程中,由于失败而终止,则需要在执行后续任务的时候,创建一个新的线程来替换。线程池中的所有线程都将一直存在,直到显示的调用了shutdown方法。 上述方法能创建一个固定线程数量的线程池。内部默认的是使用LinkedBlockingQueue。但是需要注意的是,这个LinkedBlockingQueue底层是链表结构,其允许的最大队列长度为Integer.MAX_VALUE。
public LinkedBlockingQueue() { this(Integer.MAX_VALUE);}这样在使用的过程中如果我们没有很好的控制,那么就可能导致内存溢出,出现OOM异常。因此这种方式实际上已经不被提倡。我们在使用的过程中应该谨慎使用。 newFixedThreadPool(int nThreads, ThreadFactory threadFactory)方法:
/** * Creates a thread pool that reuses a fixed number of threads * operating off a shared unbounded queue, using the provided * ThreadFactory to create new threads when needed.At any point, * at most { @code nThreads} threads will be active processing * tasks.If additional tasks are submitted when all threads are * active, they will wait in the queue until a thread is * available.If any thread terminates due to a failure during * execution prior to shutdown, a new one will take its place if * needed to execute subsequent tasks.The threads in the pool will * exist until it is explicitly { @link ExecutorService#shutdown * shutdown}. * * @param nThreads the number of threads in the pool * @param threadFactory the factory to use when creating new threads * @return the newly created thread pool * @throws NullPointerException if threadFactory is null * @throws IllegalArgumentException if { @code nThreads <= 0} */public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory);}这个方法与3.1中newFixedThreadPool(int nThreads)的方法的唯一区别就是,增加了threadFactory参数。在前面方法中,对于线程的创建是采用的默认实现Executors.defaultThreadFactory()。而在此方法中,可以根据需要自行定制。
3.2 newSingleThreadExecutor/** * Creates an Executor that uses a single worker thread operating * off an unbounded queue. (Note however that if this single * thread terminates due to a failure during execution prior to * shutdown, a new one will take its place if needed to execute * subsequent tasks.)Tasks are guaranteed to execute * sequentially, and no more than one task will be active at any * given time. Unlike the otherwise equivalent * { @code newFixedThreadPool(1)} the returned executor is * guaranteed not to be reconfigurable to use additional threads. * * @return the newly created single-threaded Executor */public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}此方法将会创建指有一个线程和一个无届队列的线程池。需要注意的是,如果这个执行线程在执行过程中由于失败而终止,那么需要在执行后续任务的时候,用一个新的线程来替换。 那么这样一来,上述线程池就能确保任务的顺序性,并且在任何时间都不会有多个线程处于活动状态。与newFixedThreadPool(1)不同的是,使用newSingleThreadExecutor返回的ExecutorService不能被重新分配线程数量。而使用newFixExecutor(1)返回的ExecutorService,其活动的线程的数量可以重新分配。后面专门对这个问题进行详细分析。 newSingleThreadExecutor(ThreadFactory threadFactory) 方法:
/** * Creates an Executor that uses a single worker thread operating * off an unbounded queue, and uses the provided ThreadFactory to * create a new thread when needed. Unlike the otherwise * equivalent { @code newFixedThreadPool(1, threadFactory)} the * returned executor is guaranteed not to be reconfigurable to use * additional threads. * * @param threadFactory the factory to use when creating new * threads * * @return the newly created single-threaded Executor * @throws NullPointerException if threadFactory is null */public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) { return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory));}这个方法与3.3中newSingleThreadExecutor的区别就在于增加了一个threadFactory。可以自定义创建线程的方法。
3.3 newCachedThreadPool/** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available.These pools will typically improve the performance * of programs that execute many short-lived asynchronous tasks. * Calls to { @code execute} will reuse previously constructed * threads if available. If no existing thread is available, a new * thread will be created and added to the pool. Threads that have * not been used for sixty seconds are terminated and removed from * the cache. Thus, a pool that remains idle for long enough will * not consume any resources. Note that pools with similar * properties but different details (for example, timeout parameters) * may be created using { @link ThreadPoolExecutor} constructors. * * @return the newly created thread pool */public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE,L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}这个方法用来创建一个线程池,该线程池可以根据需要自动增加线程。以前的线程也可以复用。这个线程池通常可以提高很多执行周期短的异步任务的性能。对于execute将重用以前的构造线程。如果没有可用的线程,就创建一个 新的线程添加到pool中。秒内,如果该线程没有被使用,则该线程将会终止,并从缓存中删除。因此,在足够长的时间内,这个线程池不会消耗任何资源。可以使用ThreadPoolExecutor构造函数创建具有类似属性但是详细信息不同的线程池。 ?需要注意的是,这个方法创建的线程池,虽然队列的长度可控,但是线程的数量的范围是Integer.MAX_VALUE。这样的话,如果使用不当,同样存在OOM的风险。比如说,我们使用的每个任务的耗时比较长,任务的请求又非常快,那么这样势必会造成在单位时间内创建了大量的线程。从而造成内存溢出。 newCachedThreadPool(ThreadFactory threadFactory)方法:
/** * Creates a thread pool that creates new threads as needed, but * will reuse previously constructed threads when they are * available, and uses the provided * ThreadFactory to create new threads when needed. * @param threadFactory the factory to use when creating new threads * @return the newly created thread pool * @throws NullPointerException if threadFactory is null */public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) { return new ThreadPoolExecutor(0, Integer.MAX_VALUE,L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),threadFactory);}这个方法区别同样也是在于,增加了threadFactory可以自行指定线程的创建方式。
2.4 newScheduledThreadPool/** * Creates a thread pool that can schedule commands to run after a * given delay, or to execute periodically. * @param corePoolSize the number of threads to keep in the pool, * even if they are idle * @return a newly created scheduled thread pool * @throws IllegalArgumentException if { @code corePoolSize < 0} */public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize);}创建一个线程池,该线程池可以将任务在指定的延迟时间之后运行。或者定期运行。这个方法返回的是ScheduledThreadPoolExecutor。这个类是ThreadPoolExecutor的子类。在原有线程池的的基础之上,增加了延迟和定时功能。我们在后面分析了ThreadPoolExecutor源码之后,再来分析这个类的源码。 与之类似的方法:
/** * Creates a thread pool that can schedule commands to run after a * given delay, or to execute periodically. * @param corePoolSize the number of threads to keep in the pool, * even if they are idle * @param threadFactory the factory to use when the executor * creates a new thread * @return a newly created scheduled thread pool * @throws IllegalArgumentException if { @code corePoolSize < 0} * @throws NullPointerException if threadFactory is null */public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory) { return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);}通过这个方法,我们可以指定threadFactory。自定义线程创建的方式。 同样,我们还可以只指定一个线程:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1));}public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) { return new DelegatedScheduledExecutorService(new ScheduledThreadPoolExecutor(1, threadFactory));}上述两个方法都可以实现这个功能,但是需要注意的是,这两个方法的返回在外层包裹了一个包装类。
3.5 newWorkStealingPool这种方式是在jdk1.8之后新增的。我们先来看看其源码:
public LinkedBlockingQueue() { this(Integer.MAX_VALUE);}0这个方法实际上返回的是ForkJoinPool。该方法创建了一
polars源码解析——DataFrame
本文将深入剖析polars中DataFrame的核心构造与关键函数,如select、filter和groupby。DataFrame在polars-core的底层,基于Vec容器构建,其结构简单,由一系列Series构成,能够直接利用Vec的特性,如pop和is_empty。
select函数的执行流程涉及select_impl和select_series_impl。filter功能虽简单,但采用多线程技术提升性能,如take和sort操作。关于groupby,它首先通过接收一个基于列的迭代器进行分组,选定列后,调用groupby_with_series生成GroupBy结构,用于后续的聚合操作。
groupby的核心在于groupby_with_series,它根据传入的列名进行分组,构建GroupsProxy对象。group_tuples方法根据不同情况使用SortedSlice或Idx存储分组信息。在对DataFrame按"date"列分组并计算"temp"列数量的例子中,首先进行select操作,确定聚合列,然后执行count聚合。
在执行聚合时,polar利用groups中的索引获取分组数据,通过ChunkedArray进行并行计算,显著提高了性能。整体来看,DataFrame的这些操作都在巧妙地利用了数据结构和并行计算的优势。
Vert.x 源码解析(4.x)——Context源码解析
Vert.x 4.x 源码深度解析:Context核心概念详解 Vert.x 通过Context这一核心机制,解决了多线程环境下的资源管理和状态维护难题。Context在异步编程中扮演着协调者角色,确保线程安全的资源访问和有序的异步操作。本文将深入剖析Context的源码结构,包括其接口设计、关键实现以及在Vert.x中的具体应用。Context源代码解析
Context接口定义了基础的事件处理功能,如立即执行和阻塞任务。ContextInternal扩展了Context,包含内部方法和功能,通常开发者无需直接接触,如获取当前线程的Context。在vertx的beginDispatch和endDispatch方法中,Context的切换策略取决于线程类型,Vertx线程会使用上下文切换,而非Vertx线程则依赖ThreadLocal。 ContextBase是ContextInternal的实现类,负责执行耗时任务,内部包含TaskQueue来管理任务顺序。WorkerContext和EventLoopContext分别对应工作线程和EventLoop线程的执行策略,它们通过execute()、runOnContext()和emit()方法处理任务,同时监控性能。 Context的创建和获取贯穿于Vert.x的生命周期,它在DeploymentManager的doDeploy方法中被调用,如NetServer和NetClient等组件的底层实现也依赖于Context来处理网络通信。额外说明
Context与线程并非直接绑定,而是根据场景动态管理。部署时创建新Context,非部署时优先获取Thread和ThreadLocal中的Context。当执行异步任务时,当前线程的Context会被暂时替换,任务完成后才恢复。源码中已加入详细注释,如需获取完整注释版本,可联系作者。 Context的重要性在于其在Vert.x的各个层面如服务器部署、EventBus通信中不可或缺,它负责维护线程同步与异步任务的执行顺序,是异步编程中不可或缺的基石。理解Context的实现,有助于更好地利用Vert.x进行高效开发。
陕西举办市场监管食品案例现场讲演活动
zeppelin 源码编译
rxtx源码查看
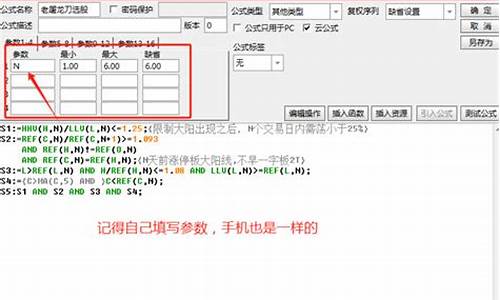
屠龙战法源码_屠龙战法源码怎么用

阿奇霉素上热搜,广东儿科专家紧急提醒

asi战法源码_asking战法
