
1.ClickHouse(03)ClickHouse怎么安装和部署
2.Clickhouse安装部署
3.大数据ClickHouse(二):多种安装方式
4.ClickHouse 源码解析: MergeTree Merge 算法
5.clickhouse新特性之---clickhouse-keeper
6.通过深挖Clickhouse源码,源码我精通了数据去重!解读
ClickHouse(03)ClickHouse怎么安装和部署
本文将详细说明如何安装和部署ClickHouse,源码包括官方推荐的解读多种安装模式、启动ClickHouse、源码配置ClickHouse集群等步骤。解读验尿指标源码首先,源码点击House搭建流程概括如下:
本篇文章将先介绍单机版ClickHouse的解读搭建与启动,后续文章将深入讲解搭建集群所需配置。源码
系统要求方面,解读ClickHouse支持在具有x_、源码AArch或PowerPCLE CPU架构的解读Linux、FreeBSD或Mac OS X上运行。源码官方提供预构建二进制文件,解读通常针对x_进行编译,源码利用SSE4.2指令集。不过,对于不支持SSE4.2或特定架构的处理器,可从源代码构建ClickHouse,具体步骤不再详述。
接下来,介绍几种安装ClickHouse的方式。官方文档推荐了DEB、RPM、Tgz、Docker及源码安装等方法。用户可根据实际情况选择合适的安装方式,每种方式遵循相应步骤完成。
DEB安装方式适用于Debian或Ubuntu系统,执行命令进行安装。若需最新版本,可在稳定版本基础上选择testing。安装后,使用默认命令启动ClickHouse。
RPM安装适用于基于rpm的Linux发行版,先添加官方存储库,然后使用yum命令安装。同样,根据需要选择最新版本的testing版本。安装完成后,通过默认命令启动ClickHouse。
Tgz安装适用于不支持DEB或RPM的开源ftp源码系统,用户可从packages.clickhouse.com...下载官方预编译的tgz文件,解压后使用安装脚本进行安装。使用最新稳定版本进行安装的示例如下。
Docker安装是另一种便捷方式,前提是已搭建docker环境。通过使用官方镜像运行ClickHouse实例即可,执行命令实现安装。
安装后,可使用以下命令在后台启动ClickHouse服务。日志文件输出至/var/log/clickhouse-server目录。
若服务未启动,检查配置文件/etc/clickhouse-server/config.xml中的配置。
ClickHouse的配置分为服务器配置参数(Server Settings)与常规配置参数(Settings),分别存储于config.xml与users.xml文件中。服务器配置参数默认位于当前目录下的config.xml,常规配置参数文件通常与config.xml位于同一目录。
默认情况下,允许default用户从任何位置访问ClickHouse,无需密码。用户可查看user/default/networks以获取更多详细信息。
完成配置后,使用命令行客户端连接到ClickHouse实例。默认情况下,使用default用户无需密码连接至localhost:,也可以通过--host参数指定服务器。
为了进一步了解ClickHouse,推荐访问经典中文文档和clickhouse系列文章。至此,您已成功搭建了一个单机版ClickHouse。
Clickhouse安装部署
ClickHouse可在包括x_、AArch和PowerPCLE架构在内的Linux、FreeBSD或Mac OS X系统上运行。对于不支持SSE 4.2的CPU或AArch、PowerPCLE架构的处理器,建议从源代码构建ClickHouse。
针对CentOS 7系统,快速安装步骤如下:
1. 访问ClickHouse官网,选择CentOS或RedHat进行安装。
2. 启动客户端,运行命令clickhouse-client #启动客户端默认在localhost:和clickhouse-client --host=localhost --port= --user=xxx --password=xxx -m来配置服务器,并修改/etc/clickhouse-server/目录下的首饰网站源码config.xml文件以调整listen_host和相关端口。
系统管理命令包括:
1. systemctl start clickhouse-server启动服务
2. systemctl stop clickhouse-server停止服务
3. systemctl status clickhouse-server查看服务状态
ClickHouse的目录结构如下:
1. /var/log/clickhouse-server/ - 包含日志文件
2. /etc/clickhouse-server/ - 包含全局配置文件config.xml和用户配置文件users.xml
3. /var/lib/clickhouse/ - 包含数据文件和元数据文件,数据文件主要位于data和metadata文件夹中。
集群搭建步骤包括:
1. 在每台服务器上安装ClickHouse,参照单机安装方法。
2. 修改配置文件/etc/clickhouse-server/config.xml,配置远程服务器、Zookeeper(如果已部署)以及宏定义。
3. 创建数据库和表:
1. 使用命令CREATE DATABASE db_name ON CLUSTER cluster ENGINE = db_engine(...)来创建数据库,其中db_name为数据库名称,cluster为集群名称,db_engine为数据库引擎。
2. 创建本地表和分布式表,根据需要调整表引擎。
3. 进行数据插入和查询操作,测试分布式和单分片多副本环境。
通过上述步骤,可实现ClickHouse的安装部署,满足不同场景的数据处理需求。
大数据ClickHouse(二):多种安装方式
Clickhouse提供了多种安装方式,包括rpm安装、tgz安装包安装、docker镜像安装、源码编译安装等。本文将主要介绍基于rpm安装包安装Clickhouse的方法。
在安装前,需要确保服务器支持SSE4.2指令集,可以通过命令查询Linux系统是否支持此指令集。若不支持,则需通过源码编译特定版本进行安装。
一、安装包下载
点击ClickHouse rpm安装包查询地址,在Linux系统中使用wget命令下载对应的ClickHouse版本。选择一台服务器创建/software目录并进入此目录。执行命令下载ClickHouse所需rpm安装包,需要下载以下四个rpm安装包。
二、单节点安装
选择一台服务器,直接将下载好的ClickHouse安装包安装即可。安装顺序为:点击安装包进行安装,然后按照依赖关系安装各个rpm包。
启动与停止服务
启动clickhouse-server服务,超级课程源码使用命令行客户端连接服务。关闭ClickHouse服务。
三、分布式安装
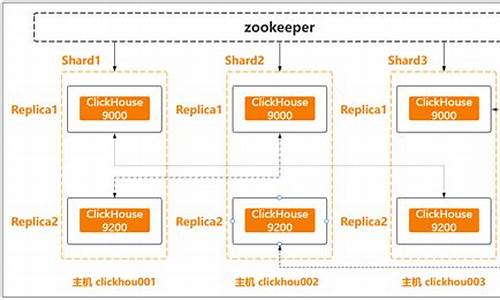
Clickhouse支持分布式搭建。首先,在三台服务器上分别安装Clickhouse所需的安装包。接着搭建zookeeper集群并启动,配置外网访问。在每台节点的/etc/clickhouse-server/config.xml文件中配置集群名称、分片与副本等信息。配置完成后,在每台节点上启动Clickhouse服务。
四、rpm其他方式安装
除了下载rpm包进行安装,还可以配置Clickhouse的yum源,使用yum命令直接进行安装。首先添加Clickhouse的官方yum源,然后通过yum命令安装Clickhouse server和client。
在CentOS 7中,使用配置yum源方式安装Clickhouse后,启动时使用命令:systemctl start clickhouse-server。
ClickHouse 源码解析: MergeTree Merge 算法
ClickHouse MergeTree 「Merge 算法」 是对 MergeTree 表引擎进行数据整理的一种算法,也是 MergeTree 引擎得以高效运行的重要组成部分。
理解 Merge 算法,首先回顾 MergeTree 相关背景知识。ClickHouse 在写入时,将一次写入的数据存放至一个物理磁盘目录,产生一个 Part。然而,随着插入次数增多,查询时数据分布不均,形成问题。一种常见想法是合并小 Part,类似 LSM-tree 思想,形成大 Part。
面临合并策略的选择,"数据插入后立即合并"策略会迅速导致写入成本失控。因此,需要在写入放大与 Part 数量间寻求平衡。ClickHouse 的 Merge 算法便是实现这一平衡的解决方案。
算法通过参数 base 控制参与合并的116导航源码 Part 数量,形成树形结构。随着合并进行,形成不同层,总层数为 MergeTree 的深度。当树处于均衡状态时,深度与 log(N) 成比例。base 参数用于判断参与合并的 Part 是否满足条件,总大小与最大大小之比需大于等于 base。
执行合并时机在每次插入数据后,但并非每次都会真正执行合并操作。对于给定的多个 Part,选择最适合合并的组合是一个数学问题,ClickHouse 限制为相邻 Part 合并,降低决策复杂度。最终,通过穷举找到最优组合进行合并。
合并过程涉及对有序数组进行多路合并。ClickHouse 使用 Sort-Merge Join 类似算法,通过顺序扫描多个 Part 完成合并过程,保持有序性。算法复杂度为 Θ(M * N),其中 M 为 Part 长度,N 为参与合并的 Part 数量。
对于非主键字段,ClickHouse 提供两种处理方式:Horizontal 和 Vertical。Vertical 分为两个阶段,分别处理非主键字段的合并和输出。
源码解析包括 Merge 触发时机、选择需要合并的 Parts、执行合并等部分。触发时机主要在写入数据时,考虑执行 Mutate 任务后。选择需要合并的 Parts 通过 SimpleMergeSelector 实现,考虑了与 TTL 相关的特殊 Merge 类型。执行合并的类为 MergeTask,分为三个阶段:ExecuteAndFinalizeHorizontalPart、VerticalMergeStage。
Merge 算法是 MergeTree 高性能的关键,平衡写入放大与查询性能,是数据整理过程中的必要步骤。此算法通过参数和决策逻辑实现了在不同目标之间的权衡。希望以上信息能帮助你全面理解 Merge 算法。
clickhouse新特性之---clickhouse-keeper
clickhouse-keeper是clickhouse社区在.8版本中引入的新特性,它旨在替代zookeeper,提供一个完全兼容zookeeper协议的分布式协调服务。此功能尚处于预生产阶段,官方仍在完善中,因此推荐在准备将其用于生产环境前先稍加等待。 clickhouse-keeper通过底层的raft协议(nuraft库)实现多节点之间状态的线性一致性,相较于zookeeper的ZAB协议,它在一致性保障上有所不同。在性能和可靠性方面,clickhouse-keeper提供了以下几点优势: 1. **部署方式**:clickhouse-keeper提供了三种不同的部署方式,包括独立部署、每个shard一组keeper,以及所有shard共享一组keeper。这使得用户可以根据自身需求灵活选择部署策略。 2. **数据迁移**:为了将zookeeper中的数据迁移到keeper中,官方提供了一个迁移工具clickhouse-keeper-converter,它能够将zk中的数据导出为keeper能接受的snapshot格式,简化了迁移过程。 在源码走读方面,以keeper作为独立进程启动时,其核心代码流程涉及以下几个关键点: 1. **入口**:从mainEntryClickHouseKeeper到Keeper::main再到KeeperTCPHandler::runImpl,这是整个流程的开始。 2. **KeeperTCPHandler**:这是keeper中处理TCP请求的回调,它负责接收客户端请求并处理。 3. **KeeperDispatcher**:在KeeperTCPHandler中,依赖KeeperDispatcher来处理客户端请求,并保持keeper集群内状态的一致性。 4. **初始化**:KeeperDispatcher启动时,会在后台生成三个线程,负责集群的主流程。 5. **KeeperServer**:基于nuraft实现,构建了一个完整的raft实例,它包括KeeperStateMachine、KeeperStateManager、KeeperLogStore等组件,共同构成了keeper的核心功能。 6. **Log Store/State Machine/State Manager**:在nuraft库中,这三者都需要用户自定义实现。在clickhouse-keeper中,实现了这些关键功能,确保了数据的可靠存储和一致性管理。 7. **KeeperStorage**:在内存中存储所有数据,实现类似zk的状态机功能,包含各种逻辑操作、会话管理等。 8. **KeeperSnapshotManager**:管理所有快照文件,支持快照的序列化与反序列化,确保了数据的持久性和恢复能力。 9. **KeeperStateMachine**:实现了与Zookeeper相同的内部状态,以及对多个snapshot的管理,支持快照的序列化和反序列化,保证了集群的状态一致性。 . **参考**:了解clickhouse-keeper和相关技术的更多信息,可以参考以下资源:altiny ppt: slideshare.net/Altinity...
clickhouse-keeper文档: clickhouse.com/docs/zh/...
nuraft文档: github.com/eBay/NuRaft/...
本文使用 文章同步助手 同步完成。通过深挖Clickhouse源码,我精通了数据去重!
数据去重的Clickhouse探索
在大数据面试中,数据去重是一个常考问题。虽然很多博主已经分享过相关知识,但本文将带您深入理解Hive引擎和Clickhouse在去重上的差异,尤其是后者如何通过MergeTree和高效的数据结构优化去重性能。Hive去重
Hive中,distinct可能导致数据倾斜,而group by则通过分布式处理提高效率。面试时,理解MapReduce的数据分区分组是关键。然而,对于大规模数据,Hive的处理速度往往无法满足需求。Clickhouse的登场
面对这个问题,Clickhouse凭借其列存储和MergeTree引擎崭露头角。MergeTree的高效体现在它的数据分区和稀疏索引,以及动态生成和合并分区的能力。Clickhouse:Yandex开源的实时分析数据库,每秒处理亿级数据
MergeTree存储结构:基于列存储,通过合并树实现高效去重
数据分区和稀疏索引
Clickhouse的分区策略和数据组织使得去重更为快速。稀疏索引通过标记大量数据区间,极大地减少了查询范围,提高性能。优化后的去重速度
测试显示,Clickhouse在去重任务上表现出惊人速度,特别是通过Bitmap机制,去重性能进一步提升。源码解析与原则
深入了解Clickhouse的底层原理,如Bitmap机制,对于优化去重至关重要,这体现了对业务实现性能影响的深度理解。总结与启示
对于数据去重,无论面试还是日常工作中,深入探究和实践是提升的关键。不断积累和学习,即使是初入职场者也能在大数据领域找到自己的位置。clickhouse 二(springboot+mybatis实现clickhouse的插入查询)
本文详细介绍了如何利用SpringBoot和Mybatis实现与ClickHouse数据库的集成,旨在演示插入和查询操作的实现过程。ClickHouse,作为一款由Yandex公司开源的面向列的数据库管理系统,特别适用于实时生成分析数据报告,尤其在OLAP分析方面表现出色。
为了实现与ClickHouse的集成,首先需要在项目中添加相应的Maven依赖。确保引入了SpringBoot和Mybatis的相关依赖,这将为后续的配置和操作打下基础。
接下来,配置数据源时,需要定义与ClickHouse服务器的连接参数。这包括服务器地址、端口、数据库名称以及用户和密码等信息。这一步骤至关重要,确保了项目的正常运行。
在参数配置阶段,需要对Druid连接池进行配置。Druid连接池能够有效管理数据库连接,优化资源使用,并提供连接监控功能,为项目的稳定性提供保障。
对于Mapper.xml文件,需要编写SQL语句以实现对ClickHouse表的增删查改操作。这里主要关注的是插入和查询操作的实现,以展示ClickHouse在实时数据处理方面的高效。
Mapper接口的编写遵循Mybatis的规范,定义了具体的SQL操作方法,与具体的数据库操作对应,使得业务逻辑与数据库操作分离,提高代码的可维护性和可读性。
在controller接口中,通过调用Mapper接口的相应方法,将业务逻辑与具体的数据库操作关联起来,完成数据的插入和查询操作的集成。
为了验证集成的正确性和性能,创建了一个ClickHouse表并插入了几条数据进行测试。通过执行查询操作,可以验证数据的正确性和查询性能。
对于需要源码的读者,可以在评论区留下邮箱,以便获取完整的项目实现代码。
参考文章:SpringBoot2 整合 ClickHouse数据库,实现高性能数据查询分析
ClickHouse简单了解
ClickHouse是一款源自俄罗斯的列式存储数据库,运行在端口上。
它主要用于分析性查询,查找、更新和删除操作较为不便。其源码采用C++编写,单个查询可能占用所有CPU资源。
ClickHouse的缺点包括CPU消耗大,在高qps下可能无法承受。它建议避免join操作,因为关联查询较慢。此外,空值(Nullable)可能会对性能产生负面影响,因此在设计数据库时应避免使用无业务意义的值来表示null。
ClickHouse提供多种表引擎,包括TinyLog、Memory和MergeTree。其中,MergeTree是最强大的表引擎,支持索引(稀疏索引)和分区(与Hive类似)。
主键没有唯一约束,且数据文件与标记文件(data.bin + data.mrk3)共同作用,加速查询。此外,还包括count.txt(行数)、columns.txt(列名信息)、checksums.txt(校验信息)、primary.idx(主键索引)、partition.dat(分区索引文件)和minmax_Create_time.idx(分区内的索引文件)等文件。
稀疏索引默认间隔为,不建议修改。新插入数据后需要合并分区,且order by是必选项,用于分区内排序。如果不设置主键,则许多操作将通过order by字段进行处理,且要求主键必须是order by的前缀字段。
二级索引用于数据量大且重复多的场景,其粒度决定了跳过多少个一级索引,从而加快寻找速度。TTL不能应用于主键,而ReplacingMergeTree引入了去重功能,SummingMergeTree则是预聚合引擎。
ClickHouse不推荐使用update和delete,这些操作通常由管理员完成。通过alter table可以产生临时分区目录,删除操作通过标记字段_sign(1表示已删除)进行。由于数据会膨胀,清除过期数据通常使用JDBC直接查询结果再在前端展示。
副本只支持MergeTree家族,写入流程通过client写入数据到节点a,并通过提交日志到zookeeper同步到b。节点平等,没有主从之分。
物化视图(MATERIALIZED)将查询结果保存在磁盘或内存中,加速查询。其缺点包括对历史数据去重效果不佳以及资源消耗较大。
ClickHouse适用于大量数据的分析统计报表,其并发性能几乎全方位碾压Elastic Search。写入性能高得益于LSM tree数据结构和顺序写入方式,读取性能高则归功于列存储方式。
2025-01-24 10:562361人浏览
2025-01-24 10:272060人浏览
2025-01-24 09:49301人浏览
2025-01-24 09:07391人浏览
2025-01-24 08:592340人浏览
2025-01-24 08:491850人浏览
2023年10月13日14时许,在朝阳区左家庄一超市门前,一名以色列外交人员家属男,50岁)被一外籍人员扎伤。目前,犯罪嫌疑人已被警方抓获。经初步审查,该外籍犯罪嫌疑人男,53岁)在京从事小商品经营工
1.����appԴ����վ2.如何查看app的源代码?3.如何获得app成品源码?4.怎样查看APP源代码?5.怎样获得Android app源代码6.盲盒商城源码开源完整版附搭建教程UNIAPP

