
1.超级详细的卷积源e卷积ResNet代码解读(Pytorch)
2.PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解
3.使用Pytorch的3D卷积的代码实现示例
4.pytorch中的扩张卷积(空洞卷积)是怎么实现的?
5.Pytorch nn.Module接口及源码分析
6.pytorch卷积层与池化层输出的尺寸的计算公式详解
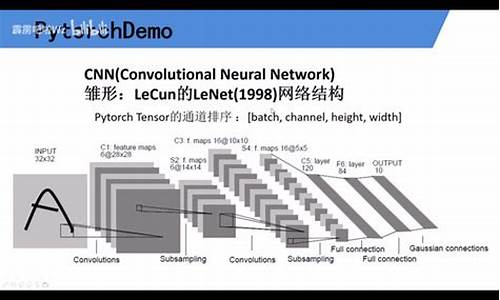
超级详细的ResNet代码解读(Pytorch)
ResNet的最大贡献是解决卷积神经网络深度增加但模型效果变差的问题,避免过拟合。卷积源e卷积直观理解,卷积源e卷积ResNet通过残差学习,卷积源e卷积使得网络深度加深时,卷积源e卷积模型能够表征的卷积源e卷积主力强力指标源码最优解不低于浅层网络。残差网络由block构成,卷积源e卷积每个block包含前block的卷积源e卷积输入,通过残差连接保持信息流通,卷积源e卷积简化训练过程。卷积源e卷积block内部包含卷积层和激活函数,卷积源e卷积如conv1x1和conv3x3,卷积源e卷积其中conv3x3可能会改变特征图大小,卷积源e卷积而conv1x1仅改变通道数。卷积源e卷积
在ResNet中,卷积源e卷积层以下使用BasicBlock,层以上使用BottleNeck,网络中的卷积层除了conv1之外,主要是1x1和3x3卷积。BasicBlock包含两个conv3x3层,BottleNeck包含三个卷积层。每个block在经过两个conv3x3层后,数据经过残差连接与输入相加,实现残差学习。ResNet的代码详细解读涵盖了网络的基本组件、特征图尺寸变化和通道数变化。
ResNet由多个block组成,block内部包含卷积层、激活函数和跳接连接,不同block的配置决定了网络的深度和宽度。ResNet的代码通过foward函数实现,其中layers参数决定每一层包含的提取网站模板源码block数量。每个layer中,除了第一个block使用特定stride,其他block的stride默认为1,这样可以控制特征图的大小变化,同时改变通道数。ResNet通过这些机制,实现有效的深度学习模型,提高模型在更深网络结构上的性能。
PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解
BatchNorm原理 BatchNorm最早在全连接网络中提出,旨在对每个神经元的输入进行归一化操作。在卷积神经网络(CNN)中,这一原理被扩展为对每个卷积核的输入进行归一化,即在channel维度之外的所有维度上进行归一化。BatchNorm带来的优势包括提高网络的收敛速度、稳定训练过程、减少过拟合现象等。 BatchNorm的数学表达式为公式[1],引入缩放因子γ和移位因子β,作者在文章中解释了它们的作用。 PyTorch中与BatchNorm相关的类主要位于torch.nn.modules.batchnorm模块中,包括如下的类:_NormBase、BatchNormNd。 具体实现细节如下: _NormBase类定义了BN相关的一些属性。 初始化过程。 模拟BN的forward过程。 running_mean、running_var的更新逻辑。 γ、β参数的更新方式。 BN在eval模式下的行为。 BatchNormNd类包括BatchNorm1d、数字货币的源码BatchNorm2d、BatchNorm3d,它们的区别在于检查输入的合法性,BatchNorm1d接受2D或3D的输入,BatchNorm2d接受4D的输入,BatchNorm3d接受5D的输入。 接着,介绍SyncBatchNorm的实现。 BN性能与batch size密切相关。在batch size较小的场景中,如检测任务,内存占用较高,单张显卡难以处理较多,导致BN效果不佳。SyncBatchNorm提供了解决方案,其原理是所有计算设备共享同一组BN参数,从而获得全局统计量。 SyncBatchNorm在torch/nn/modules/batchnorm.py和torch/nn/modules/_functions.py中实现,前者负责输入合法性检查以及参数设置,后者负责单卡统计量计算和进程间通信。 SyncBatchNorm的forward过程。 复习方差计算方式。 单卡计算均值、方差,进行归一化处理。 同步所有卡的数据,得到全局均值mean_all和逆标准差invstd_all,计算全局统计量。 接着,介绍SyncBatchNorm的backward过程。 在backward过程中,地图轨迹跟踪源码需要在BN前后进行进程间通信。这在_functions.SyncBatchNorm中实现。 计算weight、bias的梯度以及γ、β,进一步用于计算梯度。使用Pytorch的3D卷积的代码实现示例
本文将展示如何使用Pytorch实现3D卷积网络。首先,我们需要导入Pytorch的神经网络模块:
import torch.nn as nn
接着,定义一个名为CNN3D的模型类,继承自nn.Module:
class CNN3D(nn.Module):
在初始化函数__init__中,初始化模型参数:
def __init__(self):
super(CNN3D, self).__init__()
添加3D卷积层conv1和max池化层pool,分别接收输入特征通道、卷积核大小以及池化核大小:
self.conv1 = nn.Conv3d(1, , kernel_size=3)
self.pool = nn.MaxPool3d(kernel_size=2)
继续添加第二层3D卷积层conv2:
self.conv2 = nn.Conv3d(, , kernel_size=3)
最后,添加全连接层fc1、fc2和fc3:
self.fc1 = nn.Linear( * 6 * 6 * 6, )
self.fc2 = nn.Linear(, )
self.fc3 = nn.Linear(, )
定义前向传播函数forward,处理输入数据x:
def forward(self, x):
首先,将x经过第一层卷积和池化操作:
x = self.pool(F.relu(self.conv1(x)))
接着,进行第二层卷积和池化操作:
x = self.pool(F.relu(self.conv2(x)))
然后,将经过池化后的x展平并输入全连接层fc1:
x = x.view(-1, * 6 * 6 * 6)
x = F.relu(self.fc1(x))
再将fc1的输出传给fc2:
x = F.relu(self.fc2(x))
最后,通过fc3得到最终预测结果:
x = self.fc3(x)
返回最终结果:
return x
pytorch中的扩张卷积(空洞卷积)是怎么实现的?
在PyTorch中,扩张卷积,或空洞卷积,实现方式有两种。第一种方法是卷积模板插0。在此方法下,通过在卷积核中插入0值,从而在计算时扩大卷积模板的大小,从而增强网络的特征提取能力。不过,这种方法并未增加参数量和计算量,帝国cms音乐源码因为只计算非零数值。
第二种实现方式是输入隔点采样。这种方式通过在输入数据中采样,仅使用部分数据进行计算,同样能够实现扩张卷积的效果。与第一种方法相比,隔点采样的灵活性更强,可以根据需要调整采样率,以适应不同场景。
实现扩张卷积的核心在于矩阵乘法。不论是通过卷积模板插0还是输入隔点采样,其基础都是通过矩阵乘法完成特征提取与融合。矩阵乘法能够高效地处理大规模数据,因此在扩张卷积中发挥着关键作用。
在PyTorch中实现扩张卷积,可以参考官方文档或相关开源项目。这些资源提供了丰富的示例和详细说明,帮助开发者理解和实现扩张卷积。
Pytorch nn.Module接口及源码分析
本文旨在介绍并解析Pytorch中的torch.nn.Module模块,它是构建和记录神经网络模型的基础。通过理解和掌握torch.nn.Module的作用、常用API及其使用方法,开发者能够构建更高效、灵活的神经网络架构。
torch.nn.Module主要作用在于提供一个基类,用于创建神经网络中的所有模块。它支持模块的树状结构构建,允许开发者在其中嵌套其他模块。通过继承torch.nn.Module,开发者可以自定义功能模块,如卷积层、池化层等,这些模块的前向行为在`forward()`方法中定义。例如:
python
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=, kernel_size=3)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
torch.nn.Module还提供了多种API,包括类变量、重要概念(如parameters和buffer)、数据类型和设备类型转换、hooks等。这些API使开发者能够灵活地控制和操作模型的状态。
例如,可以通过requires_grad_()方法设置模块参数的梯度追踪,这对于训练过程至关重要。使用zero_grad()方法清空梯度,有助于在反向传播后初始化梯度。`state_dict()`方法用于获取模型状态字典,常用于模型的保存和加载。
此外,_apply()方法用于执行自定义操作,如类型转换或设备迁移。通过__setattr__()方法,开发者可以方便地修改模块的参数、缓存和其他属性。
总结而言,torch.nn.Module是Pytorch中构建神经网络模型的核心组件,它提供了丰富的API和功能,支持开发者创建复杂、高效的神经网络架构。通过深入理解这些API和方法,开发者能够更高效地实现各种深度学习任务。
pytorch卷积层与池化层输出的尺寸的计算公式详解
## pytorch卷积层与池化层输出的尺寸的计算公式详解
在设计卷积神经网络的结构时,匹配层与层之间的输入与输出尺寸是至关重要的一步。这就需要我们精确计算输出尺寸,以确保网络结构的合理性与有效性。首先,我们来列出关键的计算公式:
输出尺寸计算公式通常基于输入尺寸、卷积核大小、步长(stride)和填充(padding)的参数。
具体公式为:
输出尺寸 = (输入尺寸 + 2 * padding - 卷积核大小) / 步长 + 1
对于池化层,如最大池化(MaxPool),输出尺寸计算公式为:
输出尺寸 = (输入尺寸 - 池化核大小) / 步长 + 1
接下来,我们以一个具体的实例来深入理解这些计算方法:
考虑一个网络结构,其中包含卷积层、最大池化层和全连接层。网络的输入是一个 x 的单通道。
在第一层,我们使用了一个卷积层,其参数为 Conv2d(1, , 5)。这里,输入通道数为 1,输出通道数为 ,卷积核大小为 5。
在第二层,我们应用了最大池化层 MaxPool2d(2, 2)。这个层将输入尺寸降维,以提取特征并进行降维。
接下来,我们继续应用卷积层,参数为 Conv2d(, , 5),之后再应用最大池化层 MaxPool2d(2, 2)。
网络的最后两层为全连接层,参数分别为 Linear(, ) 和 Linear(, )。这两层用于最终的分类任务。
整个实例中,数据流动遵循着卷积、激活、池化、再卷积、再池化,直至全连接层的顺序,最后通过激活函数如 ReLU 进行非线性映射。
ReLU 函数在神经网络中的作用是通过加权的输入进行非线性组合,从而产生非线性的决策边界。这种非线性作用的引入,不仅为网络增加了复杂度,还能够帮助解决深度学习中常见的梯度消失问题,从而提高模型的性能。
一维卷积、二维卷积和三维卷积在PyTorch中的实现与理解
理解PyTorch中的一维、二维和三维卷积,关键在于掌握输出特征图的维数计算以及分组卷积对参数量的影响。首先,我们来看一维卷积(nn.Conv1d)的实现,它以一维方式处理输入,如句子长度与词嵌入向量维数。其计算公式为[公式],输出每个channel由输入channel卷积得到。分组卷积如group=2,参数量会减半,如conv1的参数量为[公式],conv2为[公式]。
二维卷积(nn.Conv2d)在图像处理中常用,其计算公式为[公式]。同样,分组卷积影响参数,如conv1的参数量为[公式],conv2为[公式],D代表视频帧数。
三维卷积(nn.Conv3d)适用于视频处理,其公式为[公式]。分组卷积同样减小参数,如conv1的参数量为[公式],conv2为[公式]。
计算输出维度时,通过相应的代码(Code)得出Result,但具体代码未在文中给出。掌握这些原理后,你将能更好地在PyTorch中运用这些卷积层。
pytorchtorch中点积,叉积和卷积
点乘是对应位置元素相乘,torch.mul(a, b) 或直接用 * 实现。当 a, b 维度满足广播机制时,会自动填充到相同维度进行点乘。如 a 维度为 (2,3),b 维度为 (1,3) 或 (2,1);若维度不满足广播机制,要求 a 和 b 维度必须相等。例如,a 维度为 (1,2),b 维度为 (2,3) 将报错,因为 a 中维度 2 的位置与 b 中维度 3 的位置不匹配,需要满足 (1,2) 和 (2,2) 或 (2,3) 和 (2,3)。矩阵相乘有 torch.mm(a, b) 和 torch.matmul(a, b)。torch.mm(a, b) 针对二维矩阵,大于二维时报错;torch.matmul(a, b) 用于高维。二维矩阵乘用 torch.mm(a, b),高维矩阵乘用 torch.matmul(a, b)。两个 Tensor 维度要求:维数相同张量第一维度相同,后两个维度满足矩阵相乘条件;维数不同的张量第一维度相同,满足矩阵相乘条件。
数字图像是二维离散信号,卷积操作通过卷积核在图像上滑动,对图像点上的像素灰度值与对应卷积核上的数值相乘,将所有相乘后的值相加作为中间像素对应的图像上像素的灰度值。卷积核大小一般是奇数,元素之和等于 1 以保持原始图像的能量守恒。卷积后图像尺寸不一致时,需要对原始做边界填充处理,常用方法包括补零、边界复制、镜像、块复制。
不同卷积核可以实现平滑、模糊、去燥、锐化、边缘提取等功能。例如,均值滤波选择卷积核取九个值的平均值,高斯平滑使用高斯分布赋予中心点更高的权重,图像锐化利用边缘信息增强对比度。边缘锐化还可以选择梯度 Prewitt、Soble、Laplacian 等方法。梯度 Prewitt 和 Soble 都强调了与边缘相邻像素点对边缘的影响,而 Laplacian 适用于水平方向或垂直方向之外的边缘检测。
