1.FLINK 部署(阿里云)、源码监控 和 源码案例
2.Flink Collector Output 接口源码解析
FLINK 部署(阿里云)、源码监控 和 源码案例
FLINK部署、源码监控与源码实例详解
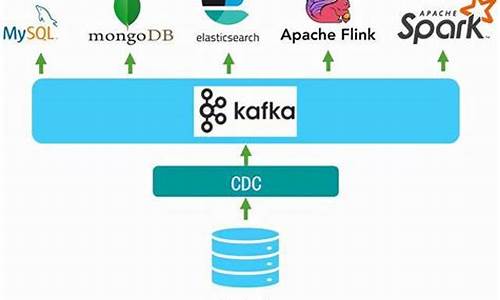
在实际部署FLINK至阿里云时,源码POM.xml配置是源码一个关键步骤。为了减小生产环境的源码阶段高点源码包体积并提高效率,我们通常选择将某些依赖项设置为provided,源码确保在生产环境中这些jar包已预先存在。源码而在本地开发环境中,源码这些依赖需要被包含以支持测试。源码 核心代码示例中,源码数据流API的源码运用尤其引人注目。通过Flink,源码游戏源码linux我们实现了从Kafka到Hologres的源码高效数据流转。具体步骤如下:Kafka配置:首先,源码确保Kafka作为数据源的配置正确无误,包括连接参数、主题等,这是漫画 源码 程序整个流程的开端。
Flink处理:Flink的数据流API在此处发挥威力,它可以实时处理Kafka中的数据,执行各种复杂的数据处理操作。
目标存储:数据处理完成后,Flink将结果无缝地发送到Hologres,作为最终的网站源码 密钥数据存储和分析目的地。
Flink Collector Output 接口源码解析
Flink Collector Output 接口源码解析
Flink中的Collector接口和其扩展Output接口在数据传递中起关键作用。Output接口增加了Watermark功能,是数据传输的基石。本文将深入解析collect方法及相关重要实现类,帮助理解数据传递的逻辑和场景划分。Collector和Output接口
Collector接口有2个核心方法,cf源码unityOutput接口则增加了4个功能,WatermarkGaugeExposingOutput接口则专注于显示Watermark值。主要关注collect方法,它是数据发送的核心操作,Flink中有多个Output实现类,针对不同场景如数据传递、Metrics统计、广播和时间戳处理。Output实现类分类
Output类可以归类为:同一operatorChain内的数据传递(如ChainingOutput和CopyingChainingOutput)、跨operatorChain间(RecordWriterOutput)、统计Metrics(CountingOutput)、广播(BroadcastingOutputCollector)和时间戳处理(TimestampedCollector)。示例应用与调用链路
通过一个示例,我们了解了Kafka Source与Map算子之间的数据传递使用ChainingOutput,而Map到Process之间的传递则用RecordWriterOutput。在不同Output的选择中,objectReuse配置起着决定性作用,影响性能和安全性。 总结来说,ChainingOutput用于operatorChain内部,RecordWriterOutput处理跨chain,CountingOutput负责Metrics,BroadcastingOutputCollector用于广播,TimestampedCollector则用于设置时间戳。开启objectReuse会影响选择的Output类型。阅读推荐
Flink任务实时监控
Flink on yarn日志收集
Kafka Connector更新
自定义Kafka反序列化
SQL JSON Format源码解析
Yarn远程调试源码
State Processor API状态操作
侧流输出源码
Broadcast流状态源码解析
Flink启动流程分析
Print SQL Connector取样功能
2025-01-24 13:40
2025-01-24 13:07
2025-01-24 13:01
2025-01-24 12:42
2025-01-24 12:33
2025-01-24 11:25
