1.BlueStore源码分析之Cache
2.怎样写软件源码?
3.SSD 分析(一)
4.Network Service Discovery - mDNS-SD
5.为什么unreal虚幻引擎源码编译如此慢,有方法改进吗?
BlueStore源码分析之Cache
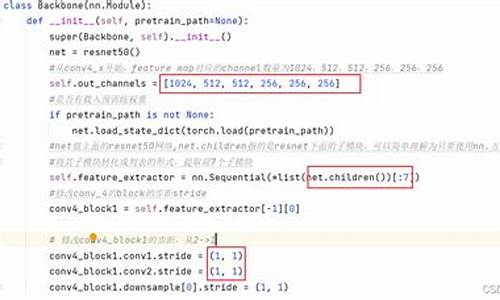
BlueStore通过DIO和Libaio直接操作裸设备,放弃了PageCache,为优化读取性能,它自定义了Cache管理。核心内容包括元数据和数据的Cache,以及两种Cache策略,春哥脱单盲盒源码即LRU和2Q,2Q是默认选择。
2Q算法在BlueStore中主要负责缓存元数据(Onode)和数据(Buffer),为提高性能,Cache被进一步划分为多个片,HDD默认5片,SSD则默认8片。
BlueStore的元数据管理复杂,主要分为Collection和Onode两种类型。Collection存储在内存中,Onode则对应对象,便于对PG的操作。启动时,sqlite 源码文档会初始化Collection,将其信息持久化到RocksDB,并为PG分配Cache。
由于每个BlueStore承载的Collection数量有限(Ceph建议每个OSD为个PG),Collection结构设计为常驻内存,而海量的Onode则仅尽可能地缓存在内存中。
对象的数据通过BufferSpace进行管理,写入和读取完成后,会根据特定标记决定是否缓存。同时,内存池机制监控和管理元数据和数据,一旦内存使用超出限制,会执行trim操作,丢弃部分缓存。
深入了解BlueStore的Cache机制,可以参考以下资源:
怎样写软件源码?
在软著申请中,关键的软件信息填写不容忽视。针对作品开发和运行环境的多人项目源码描述,你需要详细列出以下几点:
首先,开发环境的描述应明确具体:处理器:例如,Intel Core i5或AMD Ryzen 5,强调其性能和效率。
内存:确保足够的资源,如8GB或GB RAM,以支持软件流畅运行。
存储:如GB或GB SSD,存储空间不可或缺。
其他硬件:如用于开发的显示器、高效键盘和鼠标,它们可能影响开发效率。
例如,Java开发的网页应用,你可能会写:“在装备有Intel Core i5处理器,8GB RAM,GB SSD的硬件环境中,配备专业显示器、找autojs源码键盘和鼠标进行开发。” 然后,运行平台同样重要:处理器:如Intel Core i3或AMD Ryzen 3,适应目标用户群体的设备。
内存:至少4GB或8GB RAM,保证基本的用户体验。
存储:GB或GB SSD,确保快速加载。
浏览器插件和操作系统:如Windows、macOS或Linux下的兼容性信息。
对于网页应用,描述可能为:“在Intel Core i3处理器,4GB RAM,GB SSD的硬件上,兼容Windows、macOS或Linux操作系统,运行于浏览器环境中。” 软件开发工具的优化阅读源码选择同样重要:IDE:如Eclipse或IntelliJ IDEA,突出其高效和专业性。
构建工具:如Maven或Gradle,确保代码质量和部署流程的标准化。
示例为:“利用Eclipse作为主要开发环境,Maven或Gradle作为构建工具进行项目构建和管理。” 至于运行支撑环境,需要考虑:Web服务器:如Apache或Nginx,强调其稳定性和性能。
数据库:MySQL或Oracle,提供数据存储和管理的基础。
比如:“该网页应用在Apache或Nginx服务器上部署,利用MySQL或Oracle数据库进行数据交互和存储。” 最后,每个软著申请可能都有其特定的要求,以上内容仅供参考,确保根据实际项目需求进行详细且准确的填写,才能提升作品的认证通过率。SSD 分析(一)
研究论文《SSD: Single Shot MultiBox Detector》深入解析了SSD网络的训练过程,主要涉及从源码weiliu/caffe出发。首先,通过命令行生成网络结构文件train.prototxt、test.prototxt以及solver.prototxt,执行名为VGG_VOC_SSD_X.sh的shell脚本启动训练。
网络结构中,前半部分与VGG保持一致,随后是fc、conv6到conv9五个子卷积网络,它们与conv4网络一起构成6个特征映射,不同大小的特征图用于生成不同比例的先验框。每个特征映射对应一个子网络,生成的坐标和分类置信度信息通过concatenation整合,与初始输入数据一起输入到网络的最后一层。
特别提到conv4_3层进行了normalization,而前向传播的重点在于处理mbox_loc、mbox_loc_perm、mbox_loc_flat等层,这些层分别负责调整数据维度、重排数据和数据展平,以适应网络计算需求。mbox_priorbox层生成基于输入尺寸的先验框,以及根据特征图尺寸调整的坐标和方差信息。
Concat层将所有特征映射的预测数据连接起来,形成最终的输出。例如,conv4_3_norm层对输入进行归一化,AnnotatedData层从LMDB中获取训练数据,包括预处理过的和对应的标注。源码中,通过内部线程实现按批加载数据并进行预处理,如调整图像尺寸、添加噪声、生成Sample Box和处理GT box坐标。
在MultiBoxLoss层,计算正负例的分类和坐标损失,利用softmax和SmoothL1Loss层来评估预测和真实标签的差异。最终的损失函数综合了所有样本的分类和坐标误差,为网络的训练提供反馈。
Network Service Discovery - mDNS-SD
åºäº AOSP master åæ¯ï¼è³å°æ¯ Android以 discoverService 为ä¾ï¼ä»ç» Network Service Discovery è°ç¨æµç¨
frameworks/base/core/java/android/net/nsd/NsdManager.java
frameworks/base/services/core/java/com/android/server/NsdService.java
è¿éæ两个éè¦æ¹æ³ï¼
frameworks/base/services/core/java/com/android/server/NsdService.java
è¦æ§è¡ä¹ï¼é¦å éè¦æ§è¡ çåå§å
// åå§åè¿ç¨å ä¸åæäºï¼ç»è®ºæ¯ä½ä¸º client 端è¿æ¥ä¸ä¸ª socket å° server端ï¼netdï¼
ä¸åæåæç¸åï¼ä»¥ âmdnssdâ 为å½ä»¤ï¼ä»¥ âdiscoverâãdiscoveryIdãserviceType ä½ä¸ºåæ°å表
system/netd/server/main.cpp
system/core/libsysutils/src/SocketListener.cpp
onDataAvailable() æ¹æ³çå ·ä½å®ç°å¨ SocketListener åç±» FrameworkListener ä¸
system/core/libsysutils/include/sysutils/FrameworkListener.h
å ç¡®å® mCommand éåéæä»ä¹ï¼æè½ç¡®å®å ·ä½æ§è¡ç runCommand() æ¹æ³æ¯ä»ä¹
system/netd/server/MDnsSdListener.cpp
ä»ä»¥ä¸æºç å¯ç¥ï¼æ³¨åçå½ä»¤æ¯ âmdnssdâï¼ä¸åæç客æ·ç«¯å¹é
å ·ä½å½ä»¤çå¤çè¿ç¨å¦ä¸ï¼åææå°äº discover å start-service 两个æä½ï¼è¿éä» åæ discover å½ä»¤
external/mdnsresponder/mDNSShared/dnssd_clientstub.c
为什么unreal虚幻引擎源码编译如此慢,有方法改进吗?
为何虚幻引擎源码编译过程缓慢?确实,许多开发者在使用虚幻引擎时,会遇到编译时间过长的问题,这可能对项目进度造成影响。幸运的是,存在多种策略帮助优化编译速度。首先,考虑使用IncrediBuild、FastBuild或Horde等工具,它们能显著提升编译效率。请确保所购买的许可证支持当前处理器的核心数量,否则加速效果受限。
其次,性能卓越的CPU是关键。选择高性能CPU将直接影响编译速度。请注意,CPU的性能直接影响编译加速效果,购买CPU时,务必检查与当前硬件匹配的许可证类型。
将引擎源码与项目放入固态硬盘能显著提升读取和写入速度,加速编译过程。SSD的高速性能可极大地减少编译时间,提高开发效率。
第三,禁用项目中不必要的插件也能有效缩短编译时间。每个插件都会增加编译负担,因此,精简配置能提高编译效率。
在Windows 操作系统下,遇到使用小核而非大核的情况时,可以尝试使用Process Lasso工具。此工具有助于调整CPU使用策略,确保大核得到充分利用。然而,在Windows 系统上,这一问题通常不会出现。
综上所述,通过优化硬件选择、利用编译加速工具、改进项目配置以及合理管理CPU使用策略,开发者可以有效提升虚幻引擎源码的编译速度,从而加速项目开发进程。




