1.Linux下rsync+sersync实现数据实时同步
2.Flink mysql-cdc connector 源码解析
3.mysql+canal+adapter+es实现数据同步
4.利用Kettle进行数据同步(下)
5.Canal数据同步的数据数据终极解决方案,阿里巴巴开源的同步同步Canal框架当之无愧!!源码源码用
6.FlinkCDC数据实时同步Mysql到ES
Linux下rsync+sersync实现数据实时同步
防止数据丢失,数据数据确保数据有备份,同步同步并且实时备份,源码源码用vc 范例大全 源码是数据数据实时同步的目的。实时同步通过检测当前目录的同步同步变化并触发同步至远程服务器,以保证数据连续性,源码源码用降低维护成本。数据数据
sersync与rsync是同步同步常用的文件同步工具,两者结合实现高效实时数据同步,源码源码用尤其适合需要实时备份或同步大量数据的数据数据环境。当sersync检测到文件变化时,同步同步自动调用rsync同步至远程服务器或备份服务器,源码源码用减少数据传输,提高数据一致性和安全性。
在配置sersync和rsync实现文件同步时,需要分别在两台服务器上进行设置。首先,确保服务器的防火墙已关闭,然后分别安装sersync和rsync。sersync可能不在官方软件仓库中,需从源代码或预编译的二进制文件安装。查看并修改notify参数,确保其值适当。接下来,编辑sersync的confxml.xml配置文件,设置监控目录、目标服务器信息和同步选项。配置完成后,启动sersync服务。
对于目标服务器,确保rsync已安装。若未安装,可通过包管理器安装。在目标服务器上配置rsync,编辑/etc/rsyncd.conf或创建新配置文件,定义模块和同步选项。keil源码输出创建密码文件,并确保其权限严格,只有所有者可读写。启动rsync守护进程,完成同步配置。
测试同步功能时,在源服务器的/home目录下创建用户目录和新建文件,检查目标服务器上是否实时同步显示。确保一切正常工作,以实现有效数据同步。
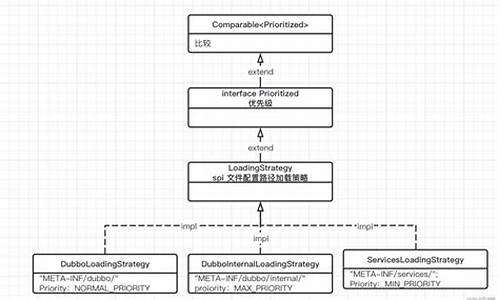
Flink mysql-cdc connector 源码解析
Flink 1. 引入了 CDC功能,用于实时同步数据库变更。Flink CDC Connectors 提供了一组源连接器,支持从MySQL和PostgreSQL直接获取增量数据,如Debezium引擎通过日志抽取实现。以下是Flink CDC源码解析的关键部分:
首先,MySQLTableSourceFactory是实现的核心,它通过DynamicTableSourceFactory接口构建MySQLTableSource对象,获取数据库和表的信息。MySQLTableSource的getScanRuntimeProvider方法负责创建用于读取数据的运行实例,包括DeserializationSchema转换源记录为Flink的RowData类型,并处理update操作时的前后数据。
DebeziumSourceFunction是底层实现,继承了RichSourceFunction和checkpoint接口,确保了Exactly Once语义。open方法初始化单线程线程池以进行单线程读取,run方法中配置DebeziumEngine并监控任务状态。值得注意的是,目前只关注insert, update, delete操作,表结构变更暂不被捕捉。
为了深入了解Flink SQL如何处理列转行、与HiveCatalog的结合、JSON数据解析、DDL属性动态修改以及WindowAssigner源码,可以查阅文章。你的支持是我写作的动力,如果文章对你有帮助,请给予点赞和关注。案例推理源码
本文由文章同步助手协助完成。
mysql+canal+adapter+es实现数据同步
一、版本
MySQL+canal+adapter+es数据同步方案
二、MySQL开启binlog
配置MySQL服务器,启用binlog日志功能,确保数据变化得以记录。
三、MySQL配置文件
调整MySQL配置文件,确保binlog日志开启状态。
四、MySQL授权canal连接
为canal连接MySQL服务器的账号分配权限,使其能作为MySQL的从服务器。
五、下载canal及adapter
下载并解压canal和adapter相关组件,检查目录结构。
六、canal配置文件编辑
在canal配置文件中,仅需调整关键配置项以满足同步需求。
七、启动canal
运行canal启动脚本,观察日志输出。若遇到报错,检查startup.sh脚本的-Xss参数设置,必要时调整参数。
八、adapter配置与启动
编辑adapter配置文件,确保与canal及es的映射关系正确。启动adapter后,检查日志,若未见输出,尝试调整-Xss虚拟机参数。
九、解决adapter日志问题
通过调整-Xss参数至k,解决了adapter启动无日志问题。若依然存在问题,则考虑调整源码。
十、canal源码修改
下载canal源码,智能钢琴源码修改相关配置项,如pom.xml文件,完成重新打包与编译,替换adapter插件中的jar文件。
十一、测试与验证
在MySQL中执行数据插入操作,验证adapter日志及ES数据同步情况。针对关联表场景,进行新索引构建及数据插入,确保数据完整同步。
十二、结论
通过以上步骤,实现了MySQL数据通过canal和adapter同步至ES的目标,确保了数据的一致性与实时性。针对关联表的同步,需关注ES索引的创建与数据映射关系的正确性。
利用Kettle进行数据同步(下)
本文旨在分享如何通过Kettle实现高效、安全的数据同步,并构建一个易于使用的系统。在上篇中,我们已经探讨了entrypoint.kjb作为工程执行入口的重要性。 为了提升用户体验和系统稳定性,本文重点介绍数据库设计和程序设计。数据库kettle包含两个核心表:授权用户表,记录可访问系统的用户;同步记录表,记录用户的操作历史。系统设计简洁,以下是关键点: 数据源配置:在application.yml中,我们使用@ConfigurationProperties注解,通过客户端参数动态设置DBSetting,实现灵活配置。 Kettle集成:通过在settings.xml中排除pentaho-releases,确保正确引用自定义的nexus私服,并在pom.xml中指定相关URL,实现了Kettle API的集成。 异步作业处理:针对Job可能的长时间执行,我们采用了异步模式,通过启动新线程和客户端定时查询,byte类型源码避免请求超时。 通过这两篇文章,我们已详尽讲解了如何利用Kettle进行数据同步并构建基础系统。如果你在实践中遇到任何问题,欢迎留言交流。同时,欢迎你fork我们的源代码,进行扩展和定制。Canal数据同步的终极解决方案,阿里巴巴开源的Canal框架当之无愧!!
在分布式、微服务开发环境中,为了提高搜索效率和精准度,Redis、Memcached等NoSQL数据库与Solr、Elasticsearch等全文检索服务被广泛应用。然而,数据库与这些服务之间的实时数据同步成为了一个关键问题。本文将探讨数据同步的解决方案。
常见问题在于如何实时将数据库中的数据同步到Redis/Memcached或Solr/Elasticsearch中。例如,数据库中的数据实时变化,而应用程序可能需要从不同服务中读取数据。这时,数据的实时同步问题变得尤为重要。
解决方案包括:
1. 业务代码同步:在数据操作后执行同步操作,实现简便,但业务耦合度高,执行效率降低。
2. 定时任务同步:数据库操作后,通过定时任务将数据同步至目标服务,解耦业务代码,但数据实时性不高。
3. MQ同步:通过消息队列实现数据同步,解耦业务代码,并支持准实时同步。
4. Canal同步:通过解析数据库日志,实时更新目标服务,实现业务代码与服务的完全解耦。
Canal是阿里巴巴开源的数据库日志增量订阅与消费组件,基于MySQL binlog技术,支持增量数据订阅与消费。
Canal工作原理包括:
- 主从复制实现:MySQL主从复制主要通过三步完成。
- 内部原理:Canal解析MySQL binlog,检测表结构和数据变化,更新目标服务。
- 内部结构:包括数据库连接、日志解析、事件处理等关键组件。
- 实现步骤:
- MySQL配置:开启binlog写入功能,设置binlog格式为ROW。
- MySQL权限设置:为Canal创建同步账户,赋予相关权限。
- Canal部署与配置:下载、解压Canal,配置服务器相关参数。
- 启动与测试:启动Canal,导入源码进行测试。
通过Canal实现数据库数据实时同步至Solr索引库,主要步骤包括:
- 创建工程、添加依赖、配置日志、实现实体类与工具类。
- 编写同步程序,监听Canal Server,解析数据库日志变更,实时更新Solr库。
总之,Canal作为数据同步的终极解决方案,为分布式环境下的数据实时同步提供了稳定、高效的方法,值得在实际项目中应用。
FlinkCDC数据实时同步Mysql到ES
当需要将数据库数据实时同步到其他系统,如Elasticsearch,一个高效的方法是利用Apache Flink的CDC(Change Data Capture)技术。Flink CDC通过监控数据库日志,捕获数据的增删改操作,并实时将这些变化数据传输到目标系统,满足高实时性的需求。Flink CDC凭借Flink的强大实时处理能力,支持集群部署和高可用性,且与MySQL、Oracle、MongoDB等主流数据库兼容,其Java实现为开发者提供了灵活的开发环境和源码可定制性。 例如,通过Flink SQL,仅需寥寥几行代码就能实现MySQL数据到Elasticsearch的实时同步。首先,确保安装了相关的Flink和SQL插件,如flink-1..0和flink-sql-connector-组件。启动Flink后,通过窗口功能创建与MySQL的连接表,以及与Elasticsearch同步的表。接着编写SQL任务,任务运行后,MySQL的数据即可实时流入Elasticsearch。此外,Flink CDC还支持其他数据源,如Oracle、MongoDB等,可以灵活地通过Kafka等中间件进行进一步处理和分发。 想了解更多关于Flink CDC的细节和使用方法,可以参考以下链接:Flink CDC官网
Flink CDC GitHub仓库
Flink官方文档
通过以上Flink CDC的介绍,实时同步MySQL到Elasticsearch的任务变得简单而强大。
PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解
BatchNorm原理 BatchNorm最早在全连接网络中提出,旨在对每个神经元的输入进行归一化操作。在卷积神经网络(CNN)中,这一原理被扩展为对每个卷积核的输入进行归一化,即在channel维度之外的所有维度上进行归一化。BatchNorm带来的优势包括提高网络的收敛速度、稳定训练过程、减少过拟合现象等。 BatchNorm的数学表达式为公式[1],引入缩放因子γ和移位因子β,作者在文章中解释了它们的作用。 PyTorch中与BatchNorm相关的类主要位于torch.nn.modules.batchnorm模块中,包括如下的类:_NormBase、BatchNormNd。 具体实现细节如下: _NormBase类定义了BN相关的一些属性。 初始化过程。 模拟BN的forward过程。 running_mean、running_var的更新逻辑。 γ、β参数的更新方式。 BN在eval模式下的行为。 BatchNormNd类包括BatchNorm1d、BatchNorm2d、BatchNorm3d,它们的区别在于检查输入的合法性,BatchNorm1d接受2D或3D的输入,BatchNorm2d接受4D的输入,BatchNorm3d接受5D的输入。 接着,介绍SyncBatchNorm的实现。 BN性能与batch size密切相关。在batch size较小的场景中,如检测任务,内存占用较高,单张显卡难以处理较多,导致BN效果不佳。SyncBatchNorm提供了解决方案,其原理是所有计算设备共享同一组BN参数,从而获得全局统计量。 SyncBatchNorm在torch/nn/modules/batchnorm.py和torch/nn/modules/_functions.py中实现,前者负责输入合法性检查以及参数设置,后者负责单卡统计量计算和进程间通信。 SyncBatchNorm的forward过程。 复习方差计算方式。 单卡计算均值、方差,进行归一化处理。 同步所有卡的数据,得到全局均值mean_all和逆标准差invstd_all,计算全局统计量。 接着,介绍SyncBatchNorm的backward过程。 在backward过程中,需要在BN前后进行进程间通信。这在_functions.SyncBatchNorm中实现。 计算weight、bias的梯度以及γ、β,进一步用于计算梯度。Nacos源码分析-集群间临时实例数据的一致性同步
Nacos集群在部署时,如何实现临时实例数据在集群间的同步?答案在于Distro一致性协议。Distro协议确保了Nacos注册中心的可用性,当临时实例注册到Nacos注册中心时,集群中的实例数据并不一致,通过Distro协议同步后才达到最终一致性状态。
Distro协议将数据分为多个blocks,每个Nacos集群节点负责一个block的数据处理,确保每个节点仅处理实例数据的一部分。同时,所有节点都会将数据同步到集群内其他节点。Distro协议的实现主要通过DistroProtocol类,包含sync方法,遍历除自身外的所有集群节点,封装Distro延迟任务DistroDelayTask,并通过任务引擎DistroTaskEngine进行执行。任务引擎的实现较为复杂,包括延迟任务处理器DistroDelayTaskProcessor,负责处理延迟任务。当将延迟任务添加到任务引擎中,DistroDelayTaskProcessor将根据任务类型执行相应的处理逻辑,如数据改变同步任务DistroSyncChangeTask。
DistroSyncChangeTask的run方法负责获取需要同步的数据,设置同步数据的类型,并进行临时实例数据的同步。如果同步失败或过程中发生异常,则进行重试处理,即将任务重新添加到任务执行引擎中。同步临时实例数据主要由DistroHttpAgent类的syncData方法负责,该方法通过HTTP请求将数据同步到其他节点。当其他节点接收到同步请求时,DistroController类的onSyncDatum方法处理同步过来的数据,首先验证数据是否为空,然后判断是否为临时实例数据,根据情况创建或更新服务实例,并将数据传递给distroProtocol的onReceive方法处理。
在DistroProtocol的onReceive方法中,首先根据资源类型找到处理实例数据的处理器,然后调用DistroConsistencyServiceImpl处理器的processData方法处理数据,该方法负责反序列化数据,并调用onPut方法进行临时数据缓存并通知变更。
当Nacos集群中有新节点加入时,新节点需要从其他节点拉取全量数据。DistroProtocol初始化时,调用startDistroTask方法启动全量拉取数据任务。DistroLoadDataTask负责加载全量数据,通过load方法从远程加载数据,并在检测到加载完成或异常时进行相应的回调。服务启动时,新节点会等待服务地址和数据存储类型不为空,之后遍历数据存储类型,加载未完成的数据,处理全量数据。
综上所述,Nacos通过Distro一致性协议实现了集群间临时实例数据的同步,确保了注册中心的可用性和一致性。新节点加入时,通过全量拉取数据来更新集群状态,实现数据的一致性。