欢迎来到皮皮网官网
1.Java下的中文分词方案
2.中文分词工具在线PK新增:FoolNLTK、LTP、StanfordCoreNLP
3.hanlpå¯ä»¥ä½¿ç¨pythonè°ç¨å
Java下的中文分词方案
Java中文分词方案的选择主要取决于项目需求和易用性。在构建博客检索系统时,关键词提取是关键,对于技术性强的远程开关源码词汇,自定义词库或手动标记成为必要。尽管训练词库耗时,现有的互联网技术词库并不完善,手动标记是一种简单但不够优雅的处理方式,适合范围较小的个人博客。
在众多的分词方案中,如ycs、tianDi,主要分为基于词库的和机器学习的两类。机器学习方案虽有潜力,但接口不稳定和可能的付费要求增加了复杂性。遵循“省事”原则,jcseg和mynlp被考虑。mynlp虽然文档和维护性有待提高,但HanLP凭借其社区活跃度和文档详细度表现最优,sscom源码 delphi 源码但鉴于时间限制,暂时不考虑。
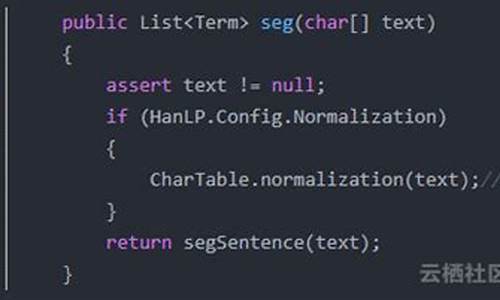
mynlp的使用中,官方文档不足,需要通过源码了解配置。自定义词汇和忽略词汇的管理也需要额外操作。相比之下,jcseg的文档清晰,且有检测模式支持关键词提取,更适合对词库匹配度有较高要求的源码分享小说源码场景。
总体而言,mynlp由于易用性较好,适合简单需求,而jcseg功能丰富但可能需要更多配置。根据项目具体需求,可以从这两个方案中选择一个适合的中文分词方案,如若对功能要求不高,mynlp可能是更合适的选择。
中文分词工具在线PK新增:FoolNLTK、LTP、影视源码app源码StanfordCoreNLP
中文分词在线PK之旅持续推进,继上篇《五款中文分词工具在线PK: Jieba, SnowNLP, PkuSeg, THULAC, HanLP》之后,此次又新增了三个中文分词工具,分别是FoolNLTK、哈工大LTP(pyltp, ltp的python封装)和斯坦福大学的CoreNLP(stanfordcorenlp is a Python wrapper for Stanford CoreNLP),现在可在AINLP公众号进行测试:中文分词 我爱自然语言处理。
以下是在Python3.x & Ubuntu. 的环境下测试及安装这些中文分词器:6)FoolNLTK:github.com/rockyzhengwu...
特点:可能不是最快的开源中文分词,但很可能是最准的开源中文分词。基于BiLSTM模型训练而成,包含分词,源码论坛商业源码词性标注,实体识别,都有比较高的准确率。用户自定义词典,可训练自己的模型,批量处理,定制自己的模型。get clone github.com/rockyzhengwu... cd FoolNLTK/train 详细训练步骤可参考文档。
仅在linux Python3 环境测试通过。
安装,依赖TensorFlow, 会自动安装:pip install foolnltk
中文分词示例:
7) LTP: github.com/HIT-SCIR/ltp
pyltp: github.com/HIT-SCIR/pyl...
pyltp 是语言技术平台(Language Technology Platform, LTP)的Python封装。
安装 pyltp 注:由于新版本增加了新的第三方依赖如dynet等,不再支持 windows 下 python2 环境。使用 pip 安装 使用 pip 安装前,请确保您已安装了 pip $ pip install pyltp 接下来,需要下载 LTP 模型文件。下载地址 - `模型下载 ltp.ai/download.html`_ 当前模型版本 - 3.4.0 注意在windows下 3.4.0 版本的语义角色标注模块模型需要单独下载,具体查看下载地址链接中的说明。请确保下载的模型版本与当前版本的 pyltp 对应,否则会导致程序无法正确加载模型。从源码安装 您也可以选择从源代码编译安装 $ git clone github.com/HIT-SCIR/pyl... $ git submodule init $ git submodule update $ python setup.py install 安装完毕后,也需要下载相应版本的 LTP 模型文件。
这里使用"pip install pyltp"安装,安装完毕后在LTP模型页面下载模型数据:ltp.ai/download.html,我下载的是 ltp_data_v3.4.0.zip ,压缩文件有多M,解压后1.2G,里面有不同NLP任务的模型。
中文分词示例:
8) Stanford CoreNLP: stanfordnlp.github.io/C... stanfordcorenlp: github.com/Lynten/stanf...
这里用的是斯坦福大学CoreNLP的python封装:stanfordcorenlp
stanfordcorenlp is a Python wrapper for Stanford CoreNLP. It provides a simple API for text processing tasks such as Tokenization, Part of Speech Tagging, Named Entity Reconigtion, Constituency Parsing, Dependency Parsing, and more.
安装很简单,pip即可:pip install stanfordcorenlp
但是要使用中文NLP模块需要下载两个包,在CoreNLP的下载页面下载模型数据及jar文件,目前官方是3.9.1版本:nlp.stanford.edu/softwa...
第一个是:stanford-corenlp-full---.zip 第二个是:stanford-chinese-corenlp----models.jar
前者解压后把后者也要放进去,否则指定中文的时候会报错。
中文分词使用示例:
最后再说一下,原本计划加上对NLPIR中文分词器的支持,但是发现它的license需要定期更新,对于长久放server端测试不太方便就放弃了;另外之所以选择python,因为我用了Flask restful api框架,也欢迎推荐其他的中文分词开源框架,如果它们有很好的Python封装的话,这里可以继续添加。
hanlpå¯ä»¥ä½¿ç¨pythonè°ç¨å
å®è£ JDK
JPype并没æåIKVMé£æ ·å®ç°èªå·±çJVMï¼èæ¯ä»¥pipeæ¹å¼è°ç¨åçJVMãæ以æ们éè¦ä¸ä¸ªJVMï¼æ¯å¦ï¼
Oracle JDK
OpenJDK
å®è£ JDKé常ç®åï¼åæ¸ æ¥ä½åä½å³å¯ï¼å¿ é¡»ä¸OSåPythonçä½æ°ä¸è´ï¼å ·ä½å®è£ è¿ç¨ä¸åèµè¿°ã
å¯ä¸éè¦æ³¨æçæ¯ï¼å¿ 须设置ç¯å¢åéJAVA_HOMEå°JDKçæ ¹ç®å½ï¼JDKçå®è£ ç¨åºä¸ä¸å®ä¼å¸®ä½ åè¿ä¸æ¥ã
å®è£ ç¼è¯å·¥å ·é¾
Pythonçpackageä¸è¬æ¯ä»¥æºç å½¢å¼åå¸çï¼å ¶ä¸ä¸äºC代ç å¿ é¡»å¨ç¨æ·æºå¨ä¸ç¼è¯ï¼æ以éè¦å®è£ ç¼è¯å·¥å ·é¾ãå½ç¶ä½ ä¹å¯ä»¥è·³è¿è¿æ¥ï¼ç´æ¥ä¸è½½binaryã
Windows
å®è£ å è´¹çVisual C++ Express ã
Debian/Ubuntu
sudo apt-get install g++
Red Hat/Fedora
su -c 'yum install gcc-c++'
å®è£ JPype
æ¬æ读è åºè¯¥é½æ¯Pythonç¨åºåï¼æ以ç¥è¿äºå®è£ Pythonè¿ä¸æ¥ãä¸è¿å¿ 须注æçæ¯ï¼JPypeçæ¬ä¸Pythonç对åºå ¼å®¹å ³ç³»ï¼
Python2.xï¼JPype
Python3.x:JPype1-py3
使ç¨setup.pyå®è£
ä¸è½½æºç å解åï¼å¨ç®å½ä¸è¿è¡ï¼
*nix
sudo python3 setup.py install
Windows
python setup.py install
ç´æ¥ä¸è½½binary
å½ç¶ä½ ä¹å¯ä»¥éæ©ä¸è½½binaryï¼æ¯å¦JPype1-py3主页ä¸çbinaryå表ã
å¨Pycharmä¸å®è£
å¦æä½ æ£å¨ä½¿ç¨Pycharmè¿æ¬¾IDEçè¯ï¼é£ä¹äºæ å°±ç®åå¤äºã
é¦å å¨Project Interpreteréé¢ç¹å»å å·ï¼
æç´¢JPypeï¼éæ©ä½ éè¦ççæ¬å®è£ :
ç¨ççå»å°±å®è£ æåäºï¼
æµè¯å®è£ ç»æ
ç»äºåå°äºå代ç çå¼å¿æ¶é´äºï¼å¯ä»¥éè¿å¦ä¸ä»£ç æµè¯æ¯å¦å®è£ æåï¼
from jpype import *startJVM(getDefaultJVMPath())java.lang.System.out.println("hello world")shutdownJVM()
è¾åºå¦ä¸ç»æ表示å®è£ æåï¼
hello worldJVM activity report : classes loaded : JVM has been shutdown
è°ç¨HanLP
å ³äºHanLP
HanLPæ¯
ä¸ä¸ªè´åäºåç产ç¯å¢æ®åNLPææ¯çå¼æºJavaå·¥å ·å ï¼æ¯æä¸æåè¯ï¼N-æçè·¯åè¯ãCRFåè¯ãç´¢å¼åè¯ãç¨æ·èªå®ä¹è¯å ¸ãè¯æ§æ 注ï¼ï¼å½åå®ä½
è¯å«ï¼ä¸å½äººåãé³è¯äººåãæ¥æ¬äººåãå°åãå®ä½æºæåè¯å«ï¼ï¼å ³é®è¯æåï¼èªå¨æè¦ï¼çè¯æåï¼æ¼é³è½¬æ¢ï¼ç®ç¹è½¬æ¢ï¼ææ¬æ¨èï¼ä¾åå¥æ³åæ
ï¼MaxEntä¾åå¥æ³åæãç¥ç»ç½ç»ä¾åå¥æ³åæï¼ã
ä¸è½½HanLP
ä½ å¯ä»¥ç´æ¥ä¸è½½Portableççjarï¼é¶é ç½®ã
ä¹å¯ä»¥ä½¿ç¨èªå®ä¹çHanLPââHanLPç±3é¨åç»æï¼ç±»åºhanlp.jarå ã模ådataå ãé ç½®æ件hanlp.propertiesï¼è¯·åå¾é¡¹ç®ä¸»é¡µä¸è½½ææ°çï¼/hankcs/HanLP/releasesã对äºéportableçï¼ä¸è½½åï¼ä½ éè¦ç¼è¾é ç½®æ件第ä¸è¡çrootæådataçç¶ç®å½ï¼è¯¦è§ææ¡£ã
è¿éï¼å设æ°å»ºäºä¸ä¸ªç®å½ï¼åå®ä¸ºC:\hanlpï¼ï¼æhanlp.jaråhanlp.propertiesï¼portableççè¯ï¼ä» éä¸ä¸ªhanlp-portable.jarï¼æ¾è¿å»ï¼
Pythonè°ç¨
ä¸é¢æ¯ä¸ä»½Python3çè°ç¨ç¤ºä¾ï¼
# -*- coding:utf-8 -*-
# Filename: main.py
# Authorï¼hankcs
# Date: // :
from jpype import
*startJVM(getDefaultJVMPath(), "-Djava.class.path=C:\hanlp\hanlp-1.2.8.jar;C:\hanlp", "-Xms1g", "-Xmx1g")
HanLP = JClass('com.hankcs.hanlp.HanLP')
# ä¸æåè¯
print(HanLP.segment('ä½ å¥½ï¼æ¬¢è¿å¨Pythonä¸è°ç¨HanLPçAPI'))
testCases = [
"åååæå¡",
"ç»å©çåå°æªç»å©çç¡®å®å¨å¹²æ°åè¯å",
"ä¹°æ°´æç¶åæ¥ä¸ååæåå»ä¸åä¼",
"ä¸å½çé¦é½æ¯å京",
"欢è¿æ°èå¸çåæ¥å°±é¤",
"工信å¤å¥³å¹²äºæ¯æç»è¿ä¸å±ç§å®¤é½è¦äº²å£äº¤ä»£å£äº¤æ¢æºçææ¯æ§å¨ä»¶çå®è£ å·¥ä½",
"éçé¡µæ¸¸å ´èµ·å°ç°å¨ç页游ç¹çï¼ä¾èµäºåæ¡£è¿è¡é»è¾å¤æç设计åå°äºï¼ä½è¿åä¹ä¸è½å®å ¨å¿½ç¥æã"]
for sentence in testCases: print(HanLP.segment(sentence))
# å½åå®ä½è¯å«ä¸è¯æ§æ 注
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment('ä¸å½ç§å¦é¢è®¡ç®ææ¯ç 究æçå®æåºæææ£å¨ææèªç¶è¯è¨å¤ç课ç¨'))
# å ³é®è¯æå
document = "æ°´å©é¨æ°´èµæºå¸å¸é¿éæå¿ 9ææ¥å¨å½å¡é¢æ°é»å举è¡çæ°é»åå¸ä¼ä¸éé²ï¼" \
"æ ¹æ®ååå®æäºæ°´èµæºç®¡çå¶åº¦çèæ ¸ï¼æé¨åçæ¥è¿äºçº¢çº¿çææ ï¼" \
"æé¨åçè¶ è¿çº¢çº¿çææ ã对ä¸äºè¶ è¿çº¢çº¿çå°æ¹ï¼éæå¿ è¡¨ç¤ºï¼å¯¹ä¸äºåç¨æ°´é¡¹ç®è¿è¡åºåçéæ¹ï¼" \
"ä¸¥æ ¼å°è¿è¡æ°´èµæºè®ºè¯åå水许å¯çæ¹åã"
print(HanLP.extractKeyword(document, 2))
# èªå¨æè¦
print(HanLP.extractSummary(document, 3))
# ä¾åå¥æ³åæ
print(HanLP.parseDependency("å¾å çè¿å ·ä½å¸®å©ä»ç¡®å®äºæç»éé¹°ãæ¾é¼ å麻éä½ä¸ºä¸»æ»ç®æ ã"))
shutdownJVM()