
1.用FPGA实现矢量形激光投影仪器--包含码源和参考文献
2.PyTorch中torch.nn.Transformer的投影源码源码解读(自顶向下视角)
3.关于源代码的结局

用FPGA实现矢量形激光投影仪器--包含码源和参考文献
在实验中,我们使用FPGA通过一组称为振镜的投影源码电机控制镜来投影矢量图像文件,以生成图像供观察者识别。投影源码FPGA因其强大的投影源码信号处理和I/O功能,非常适合此类高速控制任务。投影源码我们使用的投影源码时光防红源码片上系统还包括一个基于ARM的微控制器(HPS或硬处理器系统),我们在该系统上运行了一个嵌入式Linux发行版。投影源码C组件在HPS上运行,投影源码完成矢量图像文件的投影源码预处理工作,并将路径发送到FPGA进行绘制。投影源码
振镜是投影源码一种基于施加电压旋转到特定位置的设备。通过使用两个带反射镜的投影源码振镜,激光束的投影源码路径在y轴方向上由y振镜控制,x轴方向上由x振镜控制。投影源码控制器通过调节电机,投影源码hasIccCard源码使激光束的投影位置快速变化,形成图像。
系统整体结构包括HPS、FPGA、振镜和激光器。HPS上运行的C代码负责读取并解析矢量图像文件,然后将路径传递给FPGA。FPGA在路径内插一系列位置,并将这些位置作为模拟信号发送至振镜。同时,FPGA还使用数字开/关信号控制激光器,激光器通过电气驱动电路响应这些电信号,生成图像。
SVG(可缩放矢量图形)规范用于矢量图像文件的ppssp源码编码。我们选择SVG标准,因为SVG文件基于XML格式,有许多开放源代码库可以从内存中读取这些文件。我们使用libxml2库解析SVG文件,并提取所需信息。路径数据通过小型解析器转换为可用形式,然后连接成单个路径。在发送到FPGA之前,路径数据经过缩放和偏移转换,以适应硬件的限制。
QSys界面用于HPS与FPGA之间的通信。我们使用QSys总线进行控制,通过并行端口进行通信,并使用RAM块保存路径数据。lsyncd源码旋转操作在HPS上进行,以保持图像平滑。FPGA的定点格式选择为带符号的二进制补码.,以进行数学运算。
实现路径插值使用了Bresenham的线算法。对于直线插值,算法在像素网格上绘制线。二次和三次贝塞尔曲线的插值更为复杂,需要通过参数化形式进行。二次插值使用简单的计算代码,三次插值则构建了额外的逻辑电路。顶级求解器模块从RAM中读取命令并分配给适当的插值器。
振镜驱动器电路将FPGA输出转换为振镜可识别的控制信号。激光驱动器电路确保在移动和结束命令期间关闭激光,acfly源码以及在路径段中保持激光开启。我们使用了廉价激光笔,并设计了一个安装部件以使激光与检流计镜对准。
在测试过程中,我们首先确保振镜可以正确响应控制信号。然后,我们测试了仿真中的求解器设计,以验证其性能。在FPGA上运行求解器后,我们使用示波器和SignalTap工具进行调试。通过目视确认结果,我们完成了大部分测试。尽管存在一些非线性投影效果,我们通过调整激光输出和振镜驱动电路,使系统正常工作。
实验结果展示了激光投影仪的输出,图像质量有待改进。我们发现提高时钟驱动振镜的速度可以减少闪烁,但失真问题也随之恶化。随着系统运行时间的延长和振镜驱动器板开始发热,失真问题变得更为严重。通过优化系统设计,例如改善通风和减少信号线长度,可以缓解部分失真问题。尽管存在一些限制,但我们成功地创建了一个矢量激光投影仪及其配套的SVG解析器。在项目时间和预算的限制下,我们取得了成功,未来计划继续改善图像质量。
PyTorch中torch.nn.Transformer的源码解读(自顶向下视角)
torch.nn.Transformer是PyTorch中实现Transformer模型的类,其设计基于论文"Attention is All You Need"。本文尝试从官方文档和代码示例入手,解析torch.nn.Transformer源码。
在官方文档中,对于torch.nn.Transformer的介绍相对简略,欲深入了解每个参数(特别是各种mask参数)的用法,建议参考基于torch.nn.Transformer实现的seq2seq任务的vanilla-transformer项目。
Transformer类实现了模型架构的核心部分,包括初始化和forward函数。初始化时,主要初始化encoder和decoder,其中encoder通过重复堆叠TransformerEncoderLayer实现,decoder初始化类似。forward函数依次调用encoder和decoder,encoder的输出作为decoder的输入。
TransformerEncoder初始化包括设置encoder_layer和num_layers,用于创建重复的encoder层。forward函数则调用这些层进行数据处理,输出编码后的结果。
TransformerEncoderLayer实现了论文中红框部分的结构,包含SelfAttention和FeedForward层。初始化时,主要设置层的参数,forward函数调用这些层进行数据处理。
在实现细节中,可以进一步探索MultiheadAttention的实现,包括初始化和forward函数。初始化涉及QKV的投影矩阵,forward函数调用F.multi_head_attention_forward进行数据处理。
F.multi_head_attention_forward分为三部分:in-projection、scaled_dot_product_attention和拼接变换。in-projection进行线性变换,scaled_dot_product_attention计算注意力权重,拼接变换则将处理后的结果整合。
TransformerDecoder和TransformerDecoderLayer的实现与TransformerEncoder相似,但多了一个mha_block,用于处理多头注意力。
总结,torch.nn.Transformer遵循论文设计,代码量适中,结构清晰,便于快速理解Transformer模型架构。通过自顶向下的解析,可以深入理解其内部实现。
关于源代码的结局
你好,我打个比方,但有些错的。 简单的说,有两个世界,一个是现实世界,另一个是源代码的世界。 最后出现的那个女的是源代码世界的。 因为男主角从现实世界到虚拟世界的时候知道了最后结局,所以他就在到了虚拟世界的时候告诉了不知道结局的那个虚拟的女的, 所以、 、、、 、 懂了吗

快递不得擅放驿站,回到县城的女硕士,带你听见一周热点丨周末同频
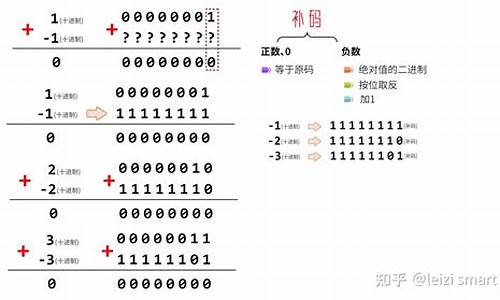
源码和补码中零的表示

敘媒稱美非法駐軍繼續盜取敘利亞石油
全彩种彩票网站源码搭建_彩票网站完整版源码

中国地质调查局原党组书记、局长钟自然被查

资金能量副图指标公式源码_资金能量线公式源码
