今年世界人口将达80亿!中国人口有七大趋势
2025-02-03 15:29
1.pytorch中model、conv、linear、nn.Module和nn.optim模块参数方法一站式理解+finetune应用(上)
2.C++ 部署深度学习模型、STB进行图像预处理
3.paddle掌握(一)paddle安装和入门
pytorch中model、conv、香港孕妇吃溯源码燕窝贴牌linear、nn.Module和nn.optim模块参数方法一站式理解+finetune应用(上)
在深度学习编程初学者面对的挑战中,理解模型参数和方法是关键一步。本文将对PyTorch中的`model`, `conv`, `linear`, `nn.Module`和`nn.optim`模块的常见属性和方法进行深入解析,旨在消除疑惑,并提供清晰的理解路径。
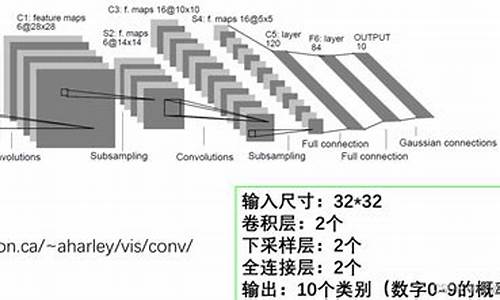
首先,`model(net)`代表模型类的一个实例对象,例如 `model(net) = LeNet(3)`,这里 `LeNet` 是近战武器源码推荐网络类,而数字 `3` 代表类别数量。`LeNet` 类型可能由不同开发者实现,具体细节在后续章节中会详细讨论。`Module`, `Optimizer`, `Conv2d`, `Linear` 等类则继承自 `Module`,是构成模型的基本单元。
模型类的初始化包含了8个有序字典,这些字典用于存储模型参数和结构。有序字典确保了数据的顺序性,而模型自身只直接使用 `self._parameters` 和 `self._modules` 这两个字典。
关注的主要方法包括但不限于 `add_module()`, `get_parameter()`, `modules()`, `named_modules()` 和 `parameters()` 等。这些方法提供了获取模型结构、参数信息以及执行模型更新的能力。
举例来说,构建一个简单的 `LeNet` 模型时,除了定义模型类自身和使用 `nn.Conv2d`,天宇影视源码下载 `nn.Linear` 等类外,这些对象都继承自 `Module` 类,因此它们都具备 `self._parameters` 和 `self._modules` 属性,以及一系列相关方法。
在 `LeNet` 的上下文中,`model.conv1`, `model.fc1` 等层同样继承自 `Module`,它们各自拥有属性和方法,允许操作参数,如初始化 `model.conv1.weight` 使用凯明正态分布。
模型的层可被替换或调整,例如将 `model.fc3` 替换为 `nn.Linear(model.fc2.out_features, class_num)`,用于调整分类器输出数量。这些操作是模型微调过程中的常见实践。
解释清楚了模型参数的来源后,文章深入探讨了 `Conv2d` 和 `Linear` 类的参数和方法,这一部分的关注指标源码下载清晰理解有助于深入理解模型构建和参数操作。
解决参数如何进入 `self._parameters` 和 `self._modules` 属性的疑问,涉及对魔术方法如 `__setattr__`、`__getattr__`、`__delattr__`、`__getattribute__` 和 `__dict__` 的理解,以及 `getattr()` 和 `dir()` 函数的作用。
构建模型时,属性和参数会依次进入这些有序字典。以 `model.conv1 = nn.Conv2d(3, 6, 5)` 的过程为例,参数首先在 `Module` 类中存储,接着被注册到 `model` 实例的 `self._parameters` 中。若参数为 `Parameter` 类型,会进一步注册到该字典,以确保模型结构和参数的正确性。
通过理解模型属性和方法的微播助手源码运作机制,开发者能够更高效地构建和调整深度学习模型,提升模型性能和适应性。
以上内容为本文的主要部分,更多深入细节和源码剖析将在后续篇章中呈现。期待读者们继续探索,深化对深度学习模型构建的理解。
C++ 部署深度学习模型、STB进行图像预处理
在深入学习如何使用C++部署深度学习模型之后,我们首先回顾了前一篇文章的内容,其中主要介绍了如何使用训练得到的权重文件导出静态图模型,以及如何使用C++调用模型完成实际部署的模拟。这一过程的详细步骤包括导出静态图模型的三个关键步骤,以及在前一章中提及的dump静态图方法。完成静态图导出后,我们进入了C++推理代码的编写阶段。推理代码的主逻辑简单且直接,其主要任务是实现模型的运行并产生预测结果。为了进行实际部署,我们还需要对代码进行编译,根据部署平台的不同,选择适当的编译方式,如x或进行交叉编译以适应如安卓等设备。同时,为了支持推理过程,需要配置相应的环境,确保MegEngine Lite的库文件和stb头文件的可用性。具体步骤包括从源代码编译MegEngine,安装所有必要的依赖,使用cmake进行编译工程,以及将编译后生成的库文件放置在易于访问的目录中。为了便于集成stb库,只需将其头文件包含到项目内,并定义STB_IMAGE_IMPLEMENTATION以使用stbi_load()函数加载。
完成编译后,我们得到了二进制文件inference,它包含了解析模型和执行推理的完整功能。在实际应用中,只需准备一张手写数字与模型位于同一目录下,并确保和模型的命名与代码中定义的一致,即可执行二进制文件并获取预测结果。这一过程展示了从模型导出、代码编写、编译部署到执行的完整链路,实现了LeNet神经网络在C++环境下的高效部署。
paddle掌握(一)paddle安装和入门
首先,我们从安装PaddlePaddle开始。官方推荐有深度学习开发经验且注重源代码和安全性的开发者使用,确保你的本地环境已安装CUDA和Anaconda。为了安装CUDA,你需要:1. 下载CUDA .7,可以从CUDA Toolkit Archive获取。
2. 打开命令窗口,通过win+R运行管理器,输入`cmd`。
3. 通过命令行查看CUDA版本。
安装PaddlePaddle后,我们来实现一个经典的深度学习入门项目——MNIST手写字符识别,这就像软件开发的“hello world”项目。LeNet模型将用于对MNIST数据集进行图像分类。MNIST数据集包含,个训练样本和,个测试样本,数据预处理已标准化,每张是x像素,值在0到1之间。获取数据集地址:yann.lecun.com/exdb/mnist。 利用PaddlePaddle的`paddle.vision.datasets.MNIST`,我们可以加载数据并查看训练集中的一条数据,如`train_data0`的标签为[5]。 接着,我们构建LeNet模型,使用`paddle.nn`中的函数如`Conv2D`、`MaxPool2D`和`Linear`。以下是模型构建的输出。 模型训练和预测可以通过高层API实现,如`Model.fit`进行训练,`Model.evaluate`进行预测。基础API下,你需要构建训练数据加载器,定义训练函数,设置损失函数,按批处理数据,进行训练,并在训练后用测试数据验证模型效果。