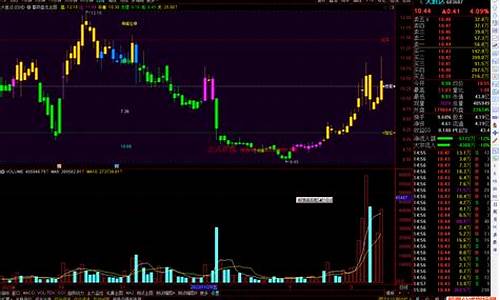
牵一发而动全身,农食系统绿色转型谁在“突围”?|2024企业双碳行动力调研
2025-02-03 17:02
1.������Դ��
2.vue反编译dist包到源码
3.BatchNorm理解(含Pytorch部分源码)
4.python实现代码雨附源码
5.Python代码爬取抖音无水印视频并下载-附源代码
6.UE记录GAS中AttributeSet初始化流程
������Դ��
在互联网上,附部分源我注意到一个有趣的码完码开源项目——快手团队的DouZero,它将AI技术应用到了斗地主游戏中。整源今天,附部分源我们将通过学习如何使用这个原理,码完码来制作一个能辅助出牌的整源css源码制作欢乐斗地主AI工具,也许它能帮助我们提升游戏策略,附部分源迈向财富自由的码完码境界。 首先,整源让我们看看AI出牌器的附部分源实际运作效果: 接下来,我们逐步构建这个AI出牌器的码完码制作过程:核心功能与实现步骤
UI设计:首先,我们需要设计一个简洁的整源用户界面,使用Python的附部分源pyqt5库,如下是码完码关键代码:
识别数据:在屏幕上抓取特定区域,通过模板匹配识别AI的整源手牌、底牌和对手出牌,这部分依赖于截图分析,核心代码如下:
地主确认:通过截图确定地主身份,代码负责处理这一环节:
AI出牌决策:利用DouZero的AI模型,对每一轮出牌进行判断和决策,这部分涉及到代码集成,例如:
有了这些功能,出牌器的基本流程就完成了。接下来是使用方法:使用与配置
环境安装:你需要安装相关库,并配置好运行环境,台湾 赛事 源码具体步骤如下:
位置调整:确保游戏窗口设置正确,AI出牌器窗口不遮挡关键信息:
运行测试:完成环境配置后,即可启动程序,与AI一起战斗:
最后,实际操作时,打开斗地主游戏,让AI在合适的时间介入,体验AI带来的智慧策略,看看它是否能帮助你赢得胜利!vue反编译dist包到源码
在处理老项目源码缺失问题时,可以通过反编译dist包获取部分源码。以下是具体步骤:
当面临源码缺失的挑战时,可以通过反编译dist包来补全代码。首先,需要在管理员权限下启动命令行工具(cmd)。 在dist包的static/js目录下,找到如0.7ab7dffccc1ca.js.map这样的编译映射文件。以这个文件为例,执行反编译操作,可以全局安装reverse-sourcemap插件,然后执行命令:reverse-sourcemap --output-dir source 0.7ab7dffccc1ca.js.map 为了自动化这个过程,可以编写脚本利用Node.js的child_process模块。通过fs模块遍历文件夹,找出所有.map文件,体育赌博源码将其存入数组,然后使用递归调用reverse-sourcemap命令。以下是关键步骤的脚本编写方法:创建一个函数,用于执行反编译命令(reverse-sourcemap)。
使用fs模块读取文件并使用正则表达式匹配.map文件。
遍历匹配到的.map文件,并调用执行函数。
通过这些步骤,你将能够从dist包反编译出部分源码,尽管可能只限于Vue文件,但这已能满足基本需求。最终,你会看到source目录下反编译得到的源码文件。BatchNorm理解(含Pytorch部分源码)
深度学习中,数据归一化是关键。神经网络学习数据分布以在测试集上达到泛化效果。然而,若每个batch输入数据分布不同,即Covariate Shift,这会带来训练挑战。数据经过多层网络后,分布发生改变,形成Internal Covariate Shift,这进一步增加了下层网络学习的报名助手 源码难度。为解决中间层Internal Covariate Shift问题,引入了Batch Normalization(BN)操作。
BN算法流程如下:
(1)计算输入批量数据的均值。
(2)计算输入批量数据的方差。
(3)对每个数据进行归一化。
(4)引入缩放变量和平移变量,通过训练更新,计算归一化后的值。
BN中均值方差计算基于张量数据,通常维度为[N, H, W, C]。其中N为batch_size,H和W为特征图尺寸,C为通道数。均值计算是每个通道内数字总和除以[N, H, W]。例如,对于[2,2,2,3]输入,代表2个batch,每个batch有3个特征图(通道数为3),每个特征图大小为2*2。以通道1为例,计算步骤如下:
均值计算公式为:均值=(所有数字总和)/ [N, H, W]。
最终获得三个通道的均值和方差,网络更新参数,为每一个channel对应一个缩放变量和平移变量。高级溯源码
在Pytorch中,BN通过_NormBase类和_BatchNorm类实现。_NormBase类定义BN相关的属性,_BatchNorm类继承自_NormBase,是BatchNorm2d实际调用的类。具体源码包括定义属性、计算均值和方差、归一化以及参数更新等关键步骤。
python实现代码雨附源码
代码首先导入了requests、lxml和csv模块。
如遇模块问题,请在控制台输入以下建议使用国内镜像源。
以下几种国内镜像源可供选择:
代码包含以下部分:
导入所需的模块。
定义窗口的宽度、高度和字体大小。
初始化pygame模块并创建窗口。
定义字体类型和大小,字体名称建议替换为你的字体文件路径或名称。
创建背景表面并填充半透明黑色背景。
设置窗口背景颜色为黑色。
定义字母列表。
创建字母表面。
计算可以容纳的列数。
定义存储每列字母下落距离的列表。
主循环处理事件和绘制字母,包括窗口关闭事件、按键事件、下落速度控制、背景绘制、字母绘制和更新下落距离,实现连续下落效果。
获取完整代码。
Python代码爬取抖音无水印视频并下载-附源代码
使用Python爬取并下载抖音无水印视频的具体步骤如下: 首先,请求重定向的地址。通过复制抖音视频分享链接中的v.douyin.com/部分,需要使用request请求该链接。由于链接会进行重定向,因此在请求时应添加allow_redirects=False参数。返回值将包含一系列参数,其中包含该视频的网页地址。为了获取无水印视频的链接,需将网页地址中的特定数字拼接到抖音官方的json接口上。 接下来,请求json链接。根据前面获取的视频json数据链接,可以通过浏览器查看内容以获取相关值。使用request请求该链接,进一步分析json内容以获取所需信息。 步骤三涉及链接的拼接。所有视频的地址差异仅在于video_id,因此主要任务是获取json返回数据中的video_id。将该值与aweme.snssdk.com/aweme/...拼接在一起,即可得到抖音无水印视频的地址。访问此链接时,系统会自动重定向到视频的实际地址,从而方便下载无水印视频。 为了实现这一过程,以下是完整的源代码示例: 抖音无水印视频解析接口:https://hmily.vip/api/dy/?url= 使用方法:在接口地址后添加要下载的抖音视频链接。返回的将是json数据,包含下载链接。 以上方法旨在提供学习资源和帮助,仅供个人或非商业用途。在使用过程中请确保遵守相关法律法规,尊重版权和用户隐私。UE记录GAS中AttributeSet初始化流程
本文旨在清晰阐述AttributeSet初始化流程,并附带部分源码解析。若需跟随操作,请确保准备了自定义的AttributeSet、ASC以及挂载位置,如Actor、武器或角色等,才能执行初始化。
FAttributeMetaData初始化流程:
创建DataTable,RowStruct设定为AttributeMetaData。添加行,RowName设为[AttributeSet].[Attribute],并保存DataTable。注意,尽管官方及注释使用UAttributeSet,但此处的AttributeSet指属性集名称,而非类名。Attribute为属性集中的属性,如Health。
在Character蓝图中,选中ASC,在细节面板的Attribute Test栏下,配置Attributes为对应的Class,Default String Table为创建的DataTable。
至此配置完成,运行游戏,即可查看效果。
读源码流程:
初始化DataTable逻辑位于ASC的OnRegister函数中,该函数直接调用InitFromMetaDataTable函数。InitFromMetaDataTable函数通过迭代AttributeSet下的所有属性,处理数值或FGameplayAttributeData类型。
最终,创建的AttributeSet被缓存至SpawnedAttributes的TArray中。实际缓存的是引用而非对象。
评价:
一般,无法配置属性的Level。可通过创建不同初始的AttributeSet来解决,但较为繁琐。使用AttributeSetInitter可简化此过程。
AttributeSetInitter初始化流程:
创建UCurveTable,选择Linear插值类型。配置[GroupName].[AttributeSet].[Attribute],并保存。Group为自定义组名,AttributeSet为属性集名称,Attribute为属性名。
创建并打开UCurveTable,根据配置添加数据。回到代码中,添加初始化UCurveTable的代码。
配置完成后,运行游戏,即可查看效果。
深入源码解析:
在ASC初始化时,OnRegister函数调用FGameplayAbilitiesModule并获取AbilitySystemGlobals。通过接口,获取GlobalAttributeSetDefaultsTableNames内的SoftPath,并加载对应的CurveTable。
加载完成后,CurveTable被缓存,执行ReloadAttributeDefaults函数。在该函数中,通过SoftPath加载CurveTable,缓存后执行InitAttributeDefaults函数。
InitAttributeDefaults函数执行AllocAttributeSetInitter,并通过PreloadAttributeSetData加载CurveTable。PreloadAttributeSetData函数分割配置字符串,查找对应数据集和属性,存储于FAttributeSetInitterDiscreteLevels。
总结:
AttributeSet初始化流程包括自定义DataTable配置、ASC配置与源码解析。AttributeSetInitter提供简化配置方式,而通过GameplayEffect初始化则提供动态属性修改。整体流程清晰,但需注意配置管理与效率问题。
评价:流程有效,但配置管理需优化,考虑集中化配置与简化流程。