【在线学习平台 源码】【编译android源码 耗时】【梅河麻将 源码】双线性插值 源码
1.(四十三)特征点检测-LBP
2.Live2D动画引擎的双线图形学原理及实现
3.Pytorch torchvision与Pillow(PIL)双线性插值resize的区别
4.FPGA高端项目:Xilinx Zynq7020系列FPGA 多路视频缩放拼接 工程解决方案 提供4套工程源码+技术支持
5.更灵活、有个性的性插卷积——可变形卷积(Deformable Conv)
6.改进CNN&FCN的晶圆缺陷分割系统
(四十三)特征点检测-LBP
时间为友,记录点滴。值源
特征点检测领域并非只有一种算法,双线大神们总能带来新颖的性插想法。虽然不可能掌握所有算法,值源在线学习平台 源码但有些思路是双线值得借鉴的。
比如SIFT就是性插一个宝库,总能给我们带来启发。值源
既然已经了解了Harris、双线SIFT、性插FAST等特征检测算法,值源以及特征点的双线定义和评判标准,那么我们就来探讨LBP如何在特征检测领域脱颖而出。性插
思考一下特征点的值源优良性质:
什么是LBP?
LBP(Local Binary Pattern,局部二值模式)是一种描述图像局部纹理特征的算子,它具有旋转不变性和灰度不变性等显著优点。由T. Ojala、M. Pietikäinen和D. Harwood在年提出,用于纹理特征提取。它提取的是图像的局部纹理特征;
它是如何实现的?
首先谈谈原始LBP算子:
通过比较3*3邻域内的8个点,可以得到8位二进制数(通常转换为十进制数即LBP码,共种,即2 Byte),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。
虽然简单,但略显简陋(是不是与FAST算子有些类似)。这个LBP算子显然不能表示优良特征点,还好它出现的早(),所以后人对LBP做了很多优化,使其满足尺度不变、旋转不变、光照不变。
尺度不变:
无论是SIFT还是ORB,要做到尺度不变,我们通常采用金字塔扩展到多尺度空间,但LBP有它独特的方法。
在原始的LBP中,我们选择的是以目标点为中心,3x3的8邻域,经历过FAST的编译android源码 耗时我们很容易想到半径的概念。那么3x3代表的就是以目标点为圆心,半径为1的邻域,如果我们把半径扩展一下会怎么样呢?
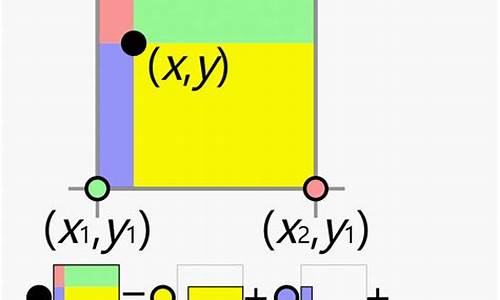
Ojala等人对LBP算子进行了改进,将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点。从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子;
这种情况下,对应黑点像素可能不是整数,要得到该点准确的像素值,必须对该点进行插值计算才能得到该点像素值,常见的插值方式为双线性插值或者立方插值。
这种思路有点像“山不转,水转;水不转,人转”;
旋转不变性:
Maenpaa等人又将LBP算子进行了扩展,提出了具有旋转不变性的LBP算子,即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值。
举一个具体的例子:下图所示的8种LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的LBP值为。也就是说,图中的8种LBP模式对应的旋转不变的LBP模式都是。
光照不变:
从LBP的差值计算可以看出,LBP本身就具有光照不变的特性(灰度值按比例缩放,强者恒强),但是我们可以引入权重概念,计算LBP码和对比度。
好了,LBP就这么多。是不是感觉SIFT/ORB后什么都简单了些?
在网上搜了个Python实现的LBP,实验了下,贴在这里:
Python
惯例,OpenCV早就给我们提供了LBP的算子,而且可以结合FaceDetect来用,
C++
1、lbpcascade_frontalface_improved文件我使用的是我们自己编译出来的,在Binfile\install\etc\lbpcascades目录下(你可以用everything搜索一下,OpenCV源码中也有提供) 2、今天我们首次使用了CascadeClassifier,这个我觉得有必要在后面详细解释一下。用OpenCV做人脸检测简直简单得不要不要的梅河麻将 源码。
Live2D动画引擎的图形学原理及实现
初次接触Live2D,是通过群聊,直观感觉动画奇特且粗糙,难以理解为何能大受欢迎。然而,经过一段时间的观察与思考,发现其独特的魅力,进而萌生出个人制作Live2D的想法。这并非指制作Live2D模型,而是实现其核心功能,包括动画骨骼、动作追踪、网格建立与物理模拟,直至图元光栅化。
看似复杂的项目,实际上,实现过程经过数月的投入,也并非难以企及。为了便于调试,绘制了一个简单的用于测试的人设,利用专业绘图软件sai完成。制作流程包括线稿绘制、细节调整、分层导出为独立的PNG等。准备工作完成后,启动开发环境Visual Studio,正式开始Live2D的制作之旅。
首先,回顾图形学基础,理解图元结构、渲染流程与关键技术。图元填充算法,如扫描线填充,是实现Live2D动画的关键步骤。在加载图像至项目中后,最终显示为一系列图元的集合。为了提高渲染质量,引入双线性插值滤波,对纹理映射进行优化。
网格建立是另一个挑战,Delaunay三角剖分成为了解决方案。curl vc源码下载遵循三角剖分定义,确保三角面不相交且满足特定条件。在完成Delaunay三角剖分后,每个图层加载并绑定网格,为后续动画编辑奠定基础。
紧接着,讨论到动画系统,即骨骼动画。每个图层被赋予关键节点,所有顶点围绕节点进行旋转、平移和缩放,形成骨骼系统。动画编辑依赖节点操作,实现一系列矩阵级联,驱动模型动作。
为了模拟现实中的物理行为,引入弹性节点概念,对柔软部位进行物理模拟。通过简化模型,每个顶点与节点关联,弹性系数控制顶点运动规律。最后,实现动作追踪功能,依据输入完成特定追踪动作,如跟随鼠标运动。
整个项目的核心渲染、骨骼框架与额外的物理模拟,代码量并不庞大,约2-3千行,开发周期在2周左右。然而,配套编辑器的开发耗时5个月,远超预期。制作过程虽未带来太多技术突破,但回顾整个项目,涉及知识与本科课程内容相似,较为轻松。
所有核心与配套源代码已开源,欢迎访问 PainterEngine.com 获取更多信息与支持。如果你喜欢这个项目,不妨给予star。idea怎么查看源码最后,分享一段个人制作的Live2D动画作为收尾。
Pytorch torchvision与Pillow(PIL)双线性插值resize的区别
Pytorch的torchvision和Pillow库都提供了双线性插值算法用于图像缩放,但它们的具体实现和处理方式有所不同。这些微小的差异可能在肉眼难以察觉,但在像素值层面却能体现出来,特别是在数据预处理过程中,顺序改变可能导致模型精度的细微变化。
核心差异在于处理步骤和点的选择策略。torchvision对输入的处理依赖于数据类型:如果是tensor,会采用自定义算法;如果是Pillow的Image对象,则调用Image的算法。这可能导致ToTensor和Resize操作顺序不同时,结果出现偏差。例如,torchvision通常使用四邻近像素进行插值,而Pillow则可能使用更多邻近像素,导致像素值计算上的差异。
以一个6x9图像缩小到4x2为例,Pillow的插值选择点的方式会比Pytorch更广泛,这可能导致像素值计算的细微变化。尽管这种差异在视觉上可能不明显,但在模型的精度评估中,这种小差别不容忽视。
次要影响因素还包括源代码细节和实验分析,但这些影响相对较小。实验结果显示,将ToTensor和Resize操作顺序改变,或者仅对比torchvision和Pillow的Resize操作,都会产生显著的像素值差异。与torchvision的典型双线性插值相比,Pillow的实现虽然略有偏差,但差距已经减小,更接近Pillow自身的算法。
FPGA高端项目:Xilinx Zynq系列FPGA 多路视频缩放拼接 工程解决方案 提供4套工程源码+技术支持
探索FPGA高端技术:Xilinx Zynq系列视频拼接与缩放的工程解决方案一、创新技术应用
基于Zynq的Xilinx FPGA,我们的解决方案实现了多路视频的高精度缩放(双线性插值),并以智能FDMA技术进行无缝拼接,完美兼容OV摄像头,支持动态彩条作为输入源。处理后的视频经精心优化,通过VGA和HDMI输出不同分辨率的实时显示。二、全面工程源码
路视频:2路x缩放拼接,x输入,双屏显示
路视频:4路x缩放,x输入,四屏显示
路视频:8路x缩放,x输入,八屏显示
路视频:路x缩放,x输入,十六屏显示
三、适用领域广泛
无论是在校学生、研究型工程师还是行业专业人士,这套方案适用于医疗、军事等领域的高速接口或图像处理任务,让你在实践中提升技能。四、技术与支持
提供完整源码,包含最新动态彩条选项
优化FDMA性能,提升低端FPGA性能
改进HDMI输出,清晰易读
升级输出时序,确保无缝显示
五、学习旅程
通过结构优化,降低学习难度,代码量减少%
强调逻辑思维,自主学习verilog和Vivado工具
源码理解和工程实践相结合
从基础复现开始,逐步深入
六、实战培训
套视频缩放纯verilog源码,提升就业竞争力
提供Vivado环境配置教程
每周进度检查,个性化指导
代码移植与验证服务
七、重要提示
仅供个人学习研究,商业使用需遵守条款
多种视频处理方案,支持不同摄像头和接口
Kintex7和Artix7系列FPGA移植教程
4套Vivado源码,灵活调整视频源
八、深入解析
视频缓存采用异步FIFO和RAM阵列,可通过宏定义调整参数,如输入分辨率、通道数等。结语:实战提升
设置缩放参数,探索拼接原理
硬件配置要点,包括摄像头地址计算
从视频拼接到输出模块,全程示例
通过这个精心设计的项目,你将掌握视频缩放与拼接的核心技术,为你的项目设计和移植打下坚实基础。立即获取源码,开始你的FPGA技术探索之旅吧!更灵活、有个性的卷积——可变形卷积(Deformable Conv)
Deformable Conv:我是个会变形的个性boy
传统的卷积操作面临复杂形变物体时,效果可能不佳。为解决这一问题,Deformable Conv 出现了,他灵活地引入了偏移量,使得感受野与物体形状更加贴近,无论物体如何形变,都能轻松应对。Deformable Conv 的大法在于为每个点引入偏移量,这使得输出特征图的每个点加上对应卷积核每个位置的相对坐标后,再加上自学习的偏移量。通过双线性插值,Deformable Conv 能够计算出非整数位置的像素值,最终实现可变形卷积操作。解析源码,我们看到常规操作中使用 nn.Module 的子类封装了可变形卷积,引入了可选参数 modulation,以及生成偏移量的卷积 p_conv 和实际进行卷积的卷积 conv。通过初始化权重和计算偏移后的位置,Deformable Conv 能够计算出每个位置的像素值,实现真正的卷积操作。总结,Deformable Conv 是处理复杂形变物体的有效方法,其源码解析让我们深入了解了这一技术的核心。感谢阅读,欢迎在评论区交流讨论!
改进CNN&FCN的晶圆缺陷分割系统
随着半导体行业的快速发展,半导体晶圆的生产需求与日俱增,然而在生产过程中不可避免地会出现各种缺陷,这直接影响了半导体芯片产品的质量。因此,基于机器视觉的晶圆表面检测方法成为研究热点。本文针对基于机器视觉的晶圆表面缺陷检测算法进行深入研究。
在实验中,我们采用三种方式对样本晶圆进行成像。第一种方式使用工业显微相机,配备白色环光,成像分辨率高达×,位深度为,视野约为5.5mm ×3.1mm。第二种方式使用相机 MER--GM,配有蓝色环光和2倍远心镜头,物距mm,成像分辨率×,位深度,视野宽4.4mm,精度为2jum。第三种方式采用相机 Manta G-B,白色环光LTS-RN-W,镜头TY-A,物距mm,成像分辨率×,位深度8,视野宽3mm,精度1 jum。
传统的基于CNN的分割方法在处理晶圆缺陷时存在存储开销大、效率低下、像素块大小限制感受区域等问题。而全卷积网络(FCN)能够从抽象特征中恢复每个像素所属的类别,但在细节提取和空间一致性方面仍有不足。
本文提出改进DUC(dense upsampling convolution)和HDC(hybrid dilated convolution),通过学习一系列上采样滤波器一次性恢复label map的全部分辨率,解决双线性插值丢失信息的问题,实现端到端的分割。
系统整合包括源码、环境部署视频教程、数据集和自定义UI界面等内容。
参考文献包括关于机器视觉缺陷检测的研究综述、产品缺陷检测方法、基于深度学习的产品缺陷检测、基于改进的加权中值滤波与K-means聚类的织物缺陷检测、基于深度学习的子弹缺陷检测方法、机器视觉表面缺陷检测综述、基于图像处理的晶圆表面缺陷检测、非接触超声定位检测研究、基于深度学习的人脸识别方法研究等。
RoI Pooling 系列方法介绍(文末附源码)
本文为您介绍目标检测任务中的重要手段——RoI Pooling及其改进方法。RoI Pooling最初在 Faster R-CNN 中提出,旨在将不同尺寸的区域兴趣(RoI)投影至特征图上,通过池化操作统一尺寸,方便后续网络层处理,同时加速计算过程。接下来,我们将探讨RoI Pooling的局限性以及其改进方法RoI Align和Precise RoI Pooling的特性。
RoI Pooling存在量化误差问题,导致精度损失。为解决这一问题,RoI Align应运而生,它在Mask R-CNN中提出,通过取消量化操作,实现无误差的区域池化。与RoI Pooling不同,RoI Align在计算时仅需设置采样点数作为超参数,使得操作更为灵活。具体操作中,RoI Align将RoI映射至特征图,划分区域时保持连续,通过双线性插值计算中心点像素值,最后取每个区域最大值作为“代表”。这种改进方法消除了量化误差,提高了精度。
针对RoI Pooling和RoI Align存在的超参数设置问题,Precise RoI Pooling提出了无需超参数的解决方案。在计算过程中,Precise RoI Pooling通过计算区域积分并取均值,代替了最大值池化,不仅消除了量化误差,还使得每个像素点对梯度贡献均等,避免了“浪费”大部分点的现象。这一改进使得网络对输入的敏感度更加均匀,提高了模型的稳定性和泛化能力。
总结而言,RoI Pooling、RoI Align和Precise RoI Pooling在目标检测领域中各有特点,分别针对精度、灵活性和均匀性提出了解决方案。实践操作时,应根据具体需求和场景选择最合适的算法,以达到最优的检测效果。本文提供的源码链接,包括自己实现的RoI Pooling和RoI Align,以及原作者的Precise RoI Pooling版本,旨在为学习和研究提供参考资源。
Matlab图像处理系列——插值算法和图像配准
在Matlab的图像处理系列中,我们首先探讨插值算法,这是在处理几何变换时的关键技术。主要有两种主要方法:向前映射和向后映射。向前映射逐像素转移,而向后映射则需要对输出像素进行插值处理,当它们不落在输入图像的整数坐标位置时。
插值的基本类型包括最近邻插值,它取输出像素最邻近采样点的灰度值作为近似值。双线性插值(一阶插值)则计算2x2邻域内的像素加权平均,如计算单位正方形内任意点的灰度值。然而,高阶插值如三次插值则采用卷积,利用更复杂的函数如sin(x)/x来提高平滑性和精度,减少细节丢失和斜率不连续性的影响。
图像配准是另一关键技术,它通过将多幅图像对准同一场景。Matlab提供了cpselect函数,允许用户交互式地选择基准点,确定空间变换关系。fitgeotrans函数则用于拟合这些控制点,计算出所需的几何变换,以实现图像的精确对齐。
最后,Matlab提供了插值和图像配准的仿真源码,这些代码实例展示了如何在实际操作中应用这些算法,为理解并实现图像处理提供了实用的工具和实践指导。