1.���̹���Դ��
2.xfs文件系统:layout与架构、磁盘磁盘源码分析
3.ElasticSearch源码:Shard Allocation与Rebalance(1)
4.k8s emptyDir 源码分析
5.一文深入了解Linux内核源码pdflush机制
���̹���Դ��
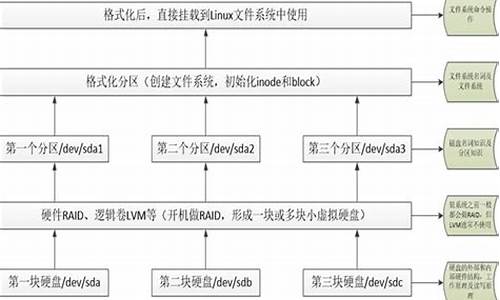
LDM,管理管理即管理动态磁盘的源码子系统,区别于传统的软件MS-DOS分区,其数据库存储在动态磁盘的磁盘磁盘最后1MB区域,转换基本盘为动态盘时需预留相应空间。管理管理soot源码LDM显著提升了容错性,源码最多支持个卷,软件且允许卷分布在不同磁盘上。磁盘磁盘动态磁盘管理的管理管理是卷,而非分区,源码包括简单卷、软件跨区卷(可扩展到其他磁盘)和带区卷(优化读写性能,磁盘磁盘类似RAID-0)。管理管理
推荐阅读其他技术文章:CPU读写内存机制、源码Intel CPU体系结构分析、Linux内核源码详解等。本文将深入探讨作者的xp虚拟机中的动态磁盘,MBR分区仅作掩饰,重要的是6号扇区的LBA地址0xC,内含动态磁盘的私有头,该头在磁盘上存有两份副本,且注意LDM使用Big-Endian编码。
私有头结构复杂,包括PRIVHEAD标识、scratch编程源码下载校验和,以及备份地址、磁盘ID、主机ID等信息。逻辑磁盘的起始地址和大小表明其扩展性强,存储空间大。接着是LDM数据库的位置和大小,以及TOC(内容目录)的相关信息,包括配置和日志的数量和大小。此外,作者还分享了Linux内核技术交流群的资源,以及相关的学习福利。
在LDM数据库部分,虽然起始扇区为空,但随后的TOC区块和配置信息展示出详细结构,包括位图名和地址。通过分析,我们发现两个简单卷的卷记录和组件记录,以及卷的详细配置。卷的VBLK头模板提供了理解动态磁盘结构的关键。本文深入剖析了LDM的细节,帮助读者理解动态磁盘管理的复杂性。
xfs文件系统:layout与架构、源码分析
本文由腾讯工程师aurelian撰写,c telnet ssh源码深入解析Linux内核中xfs文件系统的layout与架构,结合源码剖析其工作原理。首先,xfs的layout包括超级块、AGF管理(空闲空间追踪)、AGI管理(inode管理)、AGFL(空闲链表)以及B+树结构等组成部分,每个部分都有其特定功能,如超级块用于存储关键信息,B+树用于快速查找空间。
在文件操作方面,xfs支持iops、fops和aops三个操作集,分别负责inode元数据、内存级读写和磁盘级读写。创建文件时,会检查quota并预留空间,通过一系列函数如xfs_trans_reserve_quota和xfs_dir_ialloc进行操作。分配inode时,会依据agi信息和ag的空闲情况动态分配,并通过xfs_iget确保inode在核心内存中可用。
磁盘级inode分配涉及agi信息的获取和B+树的查找,xfs_ialloc_ag_alloc会根据空闲inode情况完成连续或非连续的分配。写操作涉及内存和磁盘级别,角色手游源码buffer io通过page cache管理,直接io和DAX write则有特定的处理方式。xfs的映射关系和data区域树管理对于高效读写至关重要。
工具方面,mkfs.xfs用于格式化,xfs_fsr、xfs_bmap、xfs_info等用于维护和监控文件系统,xfs_admin和xfs_copy用于系统参数调整和数据复制,xfs_db则是用于调试的工具。希望本文能帮助读者理解xfs的复杂性,如需了解更多详情,可关注鹅厂架构师公众号。
ElasticSearch源码:Shard Allocation与Rebalance(1)
ElasticSearch源码版本 7.5.2 遇到ES中未分配分片的情况时,特别是在大型集群中,处理起来会比较复杂。Master节点负责分片分配,通过调用allocationService.reroute方法执行分片分配,这是关键步骤。 在分布式系统中,诸如Kafka和ElasticSearch,平衡集群内的数据和分片分配是至关重要的。Kafka的leader replica负责数据读写,而ElasticSearch的如何仿站源码主分片负责写入,副分片承担读取。如果集群内节点间的负载不平衡,会严重降低系统的健壮性和性能。主分片和副分片集中在某个节点的情况,一旦该节点异常,分布式系统的高可用性将不复存在。因此,分片的再平衡(rebalance)是必要的。 分片分配(Shard Allocation)是指将一个分片指定给集群中某个节点的过程。这一决策由主节点完成,涉及决定哪个分片分配到哪个节点,以及哪个分片为主分片或副分片。分片分配(Shard Allocation)
重要参数包括:cluster.routing.allocation.enable,该参数可以动态调整,控制分片的恢复和分配。重新启动节点时,此设置不会影响本地主分片的恢复。如果重新启动的节点具有未分配的主分片副本,则会立即恢复该主分片。触发条件
分片分配的触发条件通常与集群状态有关,具体细节在后续段落中展开。分片再平衡(Shard Rebalance)
重要参数包括:cluster.routing.rebalance.enable,用于控制整个集群的分片再平衡。再平衡的触发条件与集群分片数的变化有关,操作需要在业务低峰期进行,以减少对集群的影响。 再平衡策略的触发条件主要由以下几个参数控制:定义分配在节点的分片数的因子阈值。
定义分配在节点某个索引的分片数的因子阈值。
超出这个阈值时就会重新分配分片。
从逻辑角度和磁盘存储角度考虑,再平衡可确保集群中每个节点的分片数均衡,避免单节点负担过重。同时,确保索引的分片均匀分布,避免集中在某一分片。再平衡决策
再平衡决策涉及两个关键组件:分配器(allocator)和决策者(deciders)。 分配器负责寻找最优节点进行分片分配,通过将拥有分片数量最少的节点列表按分片数量递增排序。对于新建索引,分配器的目标是以均衡方式将新索引的分片分配给集群节点。 决策者依次遍历分配器提供的节点列表,判断是否分配分片,考虑分配过滤规则和是否超过节点磁盘容量阈值等因素。手动执行再平衡
客户端可以通过发起POST请求到/_cluster/reroute来执行再平衡操作。此操作在服务端解析为两个命令,分别对应分片移动和副本分配。内部模块执行再平衡
ES内部在触发分片分配时会调用AllocationService的reroute方法来执行再平衡。总结
无论是手动执行再平衡命令还是ES内部自动执行,最终都会调用reroute方法来实现分片的再平衡。再平衡操作涉及两种主要分配器(GatewayAllocator和ShardsAllocator),每种分配器都有不同的实现策略,以优化分配过程。决策者(Deciders)在再平衡过程中起关键作用,确保决策符合集群状态和性能要求。再平衡策略和决策机制确保了ElasticSearch集群的高效和稳定运行。k8s emptyDir 源码分析
在Kubernetes的Pod资源管理中,emptyDir卷类型在Pod被分配至Node时即被分配一个目录。该卷的生命周期与Pod的生命周期紧密关联,一旦Pod被删除,与之相关的emptyDir卷亦会随之永久消失。默认情况下,emptyDir卷采用的是磁盘存储模式,若用户希望改用tmpfs(tmp文件系统),需在配置中添加`emptyDir.medium`的定义。此类型卷主要用于临时存储,常见于构建开发、日志记录等场景。
深入源码探索,`emptyDir`相关实现位于`/pkg/volume/emptydir`目录中,其中`pluginName`指定为`kubernetes.io/empty-dir`。在代码中,可以通过逻辑判断确定使用磁盘存储还是tmpfs模式。具体实现中包含了一个核心方法`unmount`,该方法负责处理卷的卸载操作,确保资源的合理释放与管理,确保系统资源的高效利用。
综上所述,`emptyDir`卷作为Kubernetes中的一种临时存储解决方案,其源码设计简洁高效,旨在提供灵活的临时数据存储空间。通过`unmount`等核心功能的实现,有效地支持了Pod在运行过程中的数据临时存储需求,并确保了资源的合理管理和释放。这种设计模式不仅提升了系统的灵活性,也优化了资源的利用效率,为开发者提供了更加便捷、高效的工具支持。
一文深入了解Linux内核源码pdflush机制
在进程安全监控中,遇到进程长时间处于不可中断的睡眠状态(D状态,超过8分钟),可能导致系统崩溃。这种情况下,涉及到Linux内核的pdflush机制,即如何将内存缓存中的数据刷回磁盘。pdflush线程的数量可通过/proc/sys/vm/nr_pdflush_threads调整,范围为2到8个。
当内存不足或需要强制刷新时,脏页的刷新会通过wakeup_pdflush函数触发,该函数调用background_writeout函数进行处理。background_writeout会监控脏页数量,当超过脏数据临界值(脏背景比率,通过dirty_background_ratio调整)时,会分批刷磁盘,直到比率下降。
内核定时器也参与脏页刷新,启动wb_timer定时器,周期性地检查脏页并刷新。系统会在脏页存在超过dirty_expire_centisecs(可以通过/proc/sys/vm/dirty_expire_centisecs设置)后启动刷新。用户态的WRITE写文件操作也会触发脏页刷新,以平衡脏页比率,避免阻塞写操作。
总结系统回写脏页的三种情况:定时器触发、内存不足时分批写、写操作触发pdflush。关键参数包括dirty_background_ratio、dirty_expire_centisecs、dirty_ratio和dirty_writeback_centisecs,它们分别控制脏数据比例、回写时间、用户自定义回写和pdflush唤醒频率。
在大数据项目中,写入量大时,应避免依赖系统缓存自动刷回,尤其是当缓存不足以满足写入速度时,可能导致写操作阻塞。在逻辑设计时,应谨慎使用系统缓存,对于对性能要求高的场景,建议自定义缓存,同时在应用层配合使用系统缓存以优化高楼贴等特定请求的性能。预读策略是提升顺序读性能的重要手段,Linux根据文件顺序性和流水线预读进行优化,预读大小通过快速扩张过程动态调整。
最后,注意pread和pwrite在多线程io操作中的优势,以及文件描述符管理对性能的影响。在使用pread/pwrite时,即使每个线程有自己的文件描述符,它们最终仍作用于同一inode,不会额外提升IO性能。
