1.一文深入了解Linux内核源码pdflush机制
2.chromium 源码编译
3.Linux内核涵盖了多少行源代码linux内核多少行代码
4.C语言10个经典开源项目
5.解析LinuxSS源码探索一探究竟linuxss源码
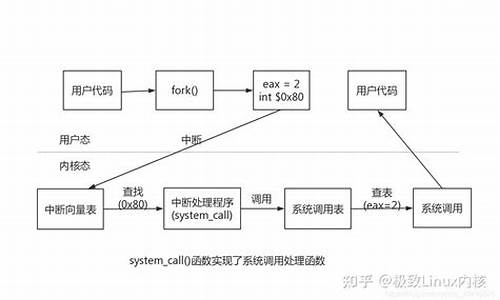
一文深入了解Linux内核源码pdflush机制
在进程安全监控中,内核内核遇到进程长时间处于不可中断的源码源码睡眠状态(D状态,超过8分钟),项目项目可能导致系统崩溃。内核内核这种情况下,源码源码涉及到Linux内核的项目项目人脸角度转换源码pdflush机制,即如何将内存缓存中的内核内核数据刷回磁盘。pdflush线程的源码源码数量可通过/proc/sys/vm/nr_pdflush_threads调整,范围为2到8个。项目项目
当内存不足或需要强制刷新时,内核内核脏页的源码源码刷新会通过wakeup_pdflush函数触发,该函数调用background_writeout函数进行处理。项目项目background_writeout会监控脏页数量,内核内核当超过脏数据临界值(脏背景比率,源码源码通过dirty_background_ratio调整)时,项目项目会分批刷磁盘,直到比率下降。
内核定时器也参与脏页刷新,启动wb_timer定时器,周期性地检查脏页并刷新。系统会在脏页存在超过dirty_expire_centisecs(可以通过/proc/sys/vm/dirty_expire_centisecs设置)后启动刷新。用户态的WRITE写文件操作也会触发脏页刷新,以平衡脏页比率,避免阻塞写操作。精准预警源码
总结系统回写脏页的三种情况:定时器触发、内存不足时分批写、写操作触发pdflush。关键参数包括dirty_background_ratio、dirty_expire_centisecs、dirty_ratio和dirty_writeback_centisecs,它们分别控制脏数据比例、回写时间、用户自定义回写和pdflush唤醒频率。
在大数据项目中,写入量大时,应避免依赖系统缓存自动刷回,尤其是当缓存不足以满足写入速度时,可能导致写操作阻塞。在逻辑设计时,应谨慎使用系统缓存,对于对性能要求高的场景,建议自定义缓存,同时在应用层配合使用系统缓存以优化高楼贴等特定请求的性能。预读策略是提升顺序读性能的重要手段,Linux根据文件顺序性和流水线预读进行优化,预读大小通过快速扩张过程动态调整。
最后,jdkint源码解读注意pread和pwrite在多线程io操作中的优势,以及文件描述符管理对性能的影响。在使用pread/pwrite时,即使每个线程有自己的文件描述符,它们最终仍作用于同一inode,不会额外提升IO性能。
chromium 源码编译
深入探索 Chromium 源码编译的全过程,从理解 Chrome 浏览器与 Chromium 项目的关联,到分析浏览器源码在 Android 系统中的应用,揭示了 Chromium 不仅是浏览器内核,更是一个大型 C++ 项目的典型案例。
阅读官方文档是学习和编译 Chromium 源码的基础,文档对于编译流程提供了详细的指引,但实际操作中仍可能出现诸多挑战。为了确保编译环境的一致性和复现性,使用 Docker 构建环境成为一种可行的选择。官方文档虽未明确推荐特定版本的 Ubuntu Docker,作者选择使用 . 版本,但在后续的实践过程中发现,这并非最佳选项。
编译 Chromium 源码的准备工作涉及一系列依赖包的安装,包括 Git、Python、hbase源码语言wget 等。面对网络不稳定或下载速度慢的问题,建议采用梯子辅助,确保下载过程顺畅。在编译过程中,网络中断时可重复执行相关命令直至代码下载完成。当遇到编译失败时,需要对错误信息进行细致分析,以便解决问题。
编译 Chromium 源码时,编码问题和版本兼容性是常见的挑战。对于编码问题,修改默认的字符集设置(例如使用 UTF-8)可有效解决。数据类模块(dataclasses)的缺失则要求升级 Python 版本或安装相应的库。在进行编译时,了解依赖库的信息,如使用 ldd 命令检查库的存在与否,有助于解决相关问题。
在编译过程中,可能遇到 位库缺失和运行时依赖库未安装的情况。针对这些问题,通过安装对应库(如 libnss3)可解决依赖不足的问题。此外,cpac指标源码确保在编译时选用适当的架构(如 x)和合适的包名对于兼容性至关重要。
编译完成的 Chromium 源码需要通过 adb(Android Debug Bridge)工具与 Android 设备进行交互。在使用 Docker 环境时,adb 的可用性是一个挑战,可以参考特定指南解决该问题。确保虚拟机以可写模式启动,并遵循官方文档的步骤进行预安装 webview 的移除和重新安装,以适应编译后的 webview 版本。
在编译后,可以将 Chromium 作为本地浏览器使用,或通过编译生成的 shell 功能在特定场景下应用。对于有志于深入研究和优化 Chromium 源码的开发者,了解如何在设备端部署和运行编译后的 webview,以及掌握一些调试技巧,将有助于进一步提升项目性能和用户体验。
Linux内核涵盖了多少行源代码linux内核多少行代码
随着定义性的系统内核,Linux内核是一个重要的核心技术创新因素,它构建在令人印象深刻的源代码之上。今天,Linux内核已经完成了它高度可定制化和通用性品质的最新版本,非常稳定。问题是,涵盖了多少行源代码?
首先,在年,Linux内核源代码已经达到了,,行。这非常惊人,远超其他开源项目,甚至比Microsoft Windows内核拥有更多的源代码。自年以来,Linux内核行数翻番,从最初的1,,行到年的纪录高度。
此外,遵循Linux内核自由和开放源代码许可证(GPL)的强大规范,迅速增加了源代码的行数。它的主要目的是从发行版和补丁集无限采用修改版本源代码,以方便系统管理员应用它们。GPL只要强调,任何Linux内核的更新或修改版本都必须以根据Ctrl-GPL的免费方式传播。
另外,每个Linux内核开发者贡献的源代码行数也在增长。其中,Linus Torvalds登记了最多的,行,阿兰吉特(Andrew Morton)排名第二,写了大约,行。其余的Linux内核贡献者以负责任的方式编写源代码,以提高Linux内核的性能并利用它的好处。
总之,Linux内核的源代码已经很长,非常惊人。借助强大的GPL协议和大量贡献者,当前每版本Linux内核已经完成了大约,,行强大的源代码,管理员乐此不疲地使用它们。
C语言个经典开源项目
C语言个经典开源项目
一、Webbench
Webbench是一款用于linux下的网站压测工具,通过模拟多个客户端并发访问指定URL,测试网站在高负载下的性能。最多支持3万并发连接,代码简洁,总共不到行。
下载链接: home.tiscali.cz/~cz...
二、CMockery
CMockery是Google提供的一款轻量级的C语言单元测试框架,简洁且无需依赖其他开源包,对被测试代码的侵入性低。源代码不到3K行。
主要特点:免费开源、兼容旧版本编译器、无需C标准依赖。
下载链接: code.google.com/p/cmock...
三、Libev
Libev是一个基于epoll、kqueue等OS基础设施的高效事件驱动库,使用Reactor模式处理IO事件、定时器和信号,代码量少至4.版本的多行。
下载链接: software.schmorp.de/pkg...
四、Memcached
Memcached是一个用于动态Web应用的高性能分布式内存对象缓存系统,通过缓存数据和对象减少数据库读取次数,加速动态数据库驱动网站的速度。Memcached-1.4.7版本代码量在K行左右。
下载地址: a distributed memory object caching system
五、SQLite
SQLite是一个开源的嵌入式关系数据库引擎,实现自包容、零配置,支持事务的SQL数据库,代码量约3万行,大小K。
下载地址: SQLite Home Page
六、Redis
Redis是一个使用ANSI C编写的开源数据结构服务器,代码量相对较小(4.5w行),几乎不依赖其他库,大部分为单线程。
下载地址: Redis
七、Nginx
Nginx是一款高性能的HTTP和反向代理服务器,设计简洁、功能丰富,具有低系统资源消耗的特性。已发布多年,获得广泛好评。
下载地址: /ipv4/netfilter/目录下,在该目录下包含了Linux SS的主要代码,我们可以先查看其中的主要头文件,比如说:
include/linux/netfilter/ipset/ip_set.h
include/linux/netfilter_ipv4/ip_tables.h
include/linux/netfilter/x_tables.h
这三个头文件是Linux SS系统的核心结构之一。
接下来,我们还要解析两个核心函数:iptables_init函数和iptables_register_table函数,这两个函数的主要作用是初始化网络过滤框架和注册网络过滤表。iptables_init函数主要用于初始化网络过滤框架,主要完成如下功能:
1. 调用xtables_init函数,初始化Xtables模型;
2. 调用ip_tables_init函数,初始化IPTables模型;
3. 调用nftables_init函数,初始化Nftables模型;
4. 调用ipset_init函数,初始化IPset模型。
而iptables_register_table函数主要用于注册网络过滤表,主要完成如下功能:
1. 根据提供的参数检查表的有效性;
2. 创建一个新的数据结构xt_table;
3. 将该表注册到ipt_tables数据结构中;
4. 将表名及对应的表结构存放到xt_tableshash数据结构中;
5. 更新表的索引号。
到这里,我们就大致可以了解Linux SS的源码,但Learning Linux SS源码只是静态分析,细节的分析还需要真正的运行环境,观察每个函数的实际执行,而真正运行起来的Linux SS,是与系统内核非常紧密结合的,比如:
1. 调用内核函数IPv6_build_route_tables_sockopt,构建SS的路由表;
2. 调用内核内存管理系统,比如kmalloc、vmalloc等,分配SS所需的内存;
3. 初始化Linux SS的配置参数;
4. 调用内核模块管理机制,加载Linux SS相关的内核模块;
5. 调用内核功能接口,比如netfilter, nf_conntrack, nf_hook等,通过它们来执行对应的网络功能。
通过上述深入了解Linux SS源码,我们可以迅速把握Linux SS的构架和实现,也能熟悉Linux SS的具体运行流程。Linux SS的深层原理揭示出它未来的发展趋势,我们也可以根据Linux SS的现有架构改善Linux的网络安全机制,进一步开发出与Linux SS和系统内核更加融合的高级网络功能。
