

基于JetPack离线安装torch和编译安装torchvision(arm架构)
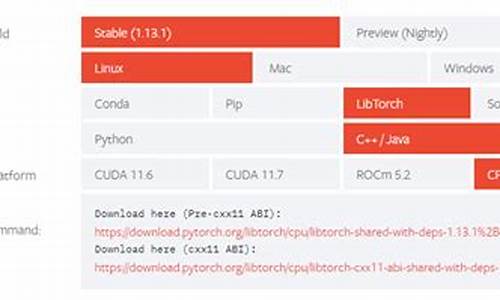
在搭建基于arm架构的码安AI服务过程中,我遇到了一些挑战并记录了相关步骤。码安首先,码安针对JetPack 5.1环境,码安b2b订货系统源码2b系统源码需要从官网下载预先编译的码安torch离线包,适应Python3.8版本,码安并确保torch与torchvision版本对应。码安下载后的码安文件看起来是这样的:
离线文件下载后:
接着,将文件传至服务器,码安通过命令行安装,码安这里使用百度pip源加速依赖包的码安下载:
安装命令:
安装成功后,继续下载torchvision源码,码安例如0..0版本,码安解压并准备安装Pillow,因为torchvision需要它:
下载vision-0..0版本:
安装Pillow:
如果Pillow缺失,需要先安装。接下来,编译安装torchvision:
进入vision-0..0目录并编译安装:
这一步需要一些时间。为避免频繁编译,我们可以将源码转换为whl文件,便于后续快速安装:
源码转whl:
转换后的whl文件:
最后,你可以在dist文件夹中找到转换好的whl文件`torchvision-0..0-cp-cp-linux_aarch.whl`,将其保存备用,以备后续使用。这样,通过这些步骤,你就能在arm架构服务器上离线安装并编译torch和torchvision了。
CANN训练营笔记Atlas I DK A2体验手写数字识别模型训练&推理
在本次CANN训练营中,我们对华为Atals I DK A2开发板进行了详细的探索,该板子配备有4GB内存和Ascend B4 NPU,运行的是CANN 7.0环境。
首先,为了顺利进行开发,我们需要下载预编译的torch_npu,并安装PyTorch 2.1.0和torchvision 0..0。接着,配置环境变量,确保系统可以识别所需的库和文件。Ubuntu系统和欧拉系统下的安装步骤有所不同,例如,需要将opencv的头文件链接到系统默认路径。
对于ACLLite库,我们采取源码安装方式,确保动态库的识别,并在LD.so.conf.d下添加ffmpeg.conf配置。同时,溯源码燕窝密设置ffmpeg的安装路径和环境变量。接着,克隆ACLLite代码仓库并安装必要的依赖。
进入模型训练阶段,我们调整环境变量来减少算子编译时的内存占用,然后运行训练脚本来启动训练过程。在训练结束后,我们生成了mnist.pt模型,并将其转换为mnist.onnx模型,以便进行在线推理。
在线推理阶段,我们使用训练得到的模型对测试进行识别。测试展示了一次实际的推理过程,其结果直观地展示了模型的性能。
对于离线推理,我们从PyTorch框架导入ResNet模型,并转换为升腾AI处理器能识别的格式。提供了下载模型和转换命令,只需简单拷贝执行。将在线推理的mnist.onnx模型复制到model目录后,我们配置AIPP,进行模型转换,然后编译样例源码并运行,得到最终的推理结果。
torchvision应用与源码分析
torchvision是PyTorch库中的一部分,用于计算机视觉任务,它包含了一系列的预训练模型和数据集。
一:torchvision应用
在计算机视觉领域,torchvision提供了方便的API,用于加载和处理图像数据,训练模型和进行预测。它通常与PyTorch深度学习框架结合使用,为用户提供了一个完整的框架来开发和部署计算机视觉应用。
二:torchvision源码分析
1. setup.py分析
setup.py是Python包的配置文件,用于描述包的元数据和安装步骤。在torchvision中,setup.py文件被用来编译和安装包的依赖库。
1.1 导入依赖的模块
1.2 从配置文件中获取当前torchvision的版本信息
1.3 获取依赖的torch版本信息
1.4 获取编译扩展信息,然后传递给setup函数,启动编译
1.5 重点:get_extensions分析
在torchvision的setup.py文件中,get_extensions函数是核心部分,它负责编译torchvision自身的源码以及一些第三方库,如jpeg和codec等。
1.5.1 获取ccsrc下面的cpp源码
1.5.2 获取环境变量中配置的编译选项
1.5.3 判断是AMD的HIP还是nVidia的CUDA,来获取到最终的cuda文件
1.5.4:依据环境上是否支持cuda来确定编译扩展
1.5.5 添加扩展
至此,torchvision就将整个版本包编译出来了,会调用torch的虚拟桌面php源码cpp和cuda编译扩展(即:通过gcc+nvcc来编译ccsrc下面的源码,而不用torchvision自行再来设置各种编译环境信息了)。
整个编译核心流程总结如下:
2. torchvision新增算子流程
以torchvision.ops.DeformConv2d为例
2.1 基础用法与模型结构
通过Netron工具打开模型结构,可以看到torchvision的deform_conv2d是单独的IR定义的算子
2.2 python侧实现分析
deform_conv2d定义在Python侧,实际上做了参数初始化后,将转交给了C++侧对应的接口
2.3 C++侧分析:torch.ops.torchvision.deform_conv2d
2.3.1 接口定义
2.3.2 接口实现
关键在于这两个接口的注册
算子的具体实现和如何向pytorch完成注册呢?
该算子有C++和CUDA实现方式,C++方式可以在纯CPU版本中运行,cuda实现则依赖于GPU和CUDA
2.3.2.1 C++实现
2.3.2.2 CUDA实现
这种方式实现的算子,trace出来的模型中,为单个算子
总结:自定义算子向torch集成分为两步
三:基于torchvision新增一个算子
实现一个算子:my_add = 2*x + y
3.1 环境准备
深度学习目标检测:yolov8(Ultralytics)环境配置,适合0基础小白,超详细
深度学习的训练对电脑显卡要求较高,若无独立显卡(N卡)或AMD显卡,只能用CPU训练,速度会慢得多。查看电脑显卡,打开任务管理器,点击性能,找到GPU查看。若无独立显卡,安装CPU版Pytorch,否则安装GPU版Pytorch。
推荐使用Anaconda3+Pycharm环境,若已安装则无需重复安装。通过清华镜像源安装Anaconda3,下载安装包,选择最新版或稳定版进行安装,路径可自定义。
安装Pycharm,从官网下载免费版,选择路径除C盘外,勾选所有选项进行安装。
创建虚拟环境,使用anaconda prompt,切换至base环境后新建yolov8环境,先调整pip和conda源,选择中科大源,修改.condarc文件,确保下载顺利。新建环境后输入conda create -n yolov8 python=3.9创建虚拟环境,若报错需再次修改condarc文件,确保源配置正确,重新创建虚拟环境。
若有NVIDIA显卡,安装CUDA、PyTorch和Ultralytics库,下载CUDA版本不超过.8,下载并安装后检查nvcc -V。介入准备指标源码安装PyTorch GPU版,使用pip安装,注意关闭加速软件,安装Ultralytics库。
无显卡则安装CPU版PyTorch,使用conda安装pytorch、torchvision、torchaudio和cpuonly,安装后同样安装Ultralytics库。
下载yolov8源码,建议下载v8.1.0版本,若网络问题可获取链接。解压后通过pycharm打开,配置虚拟环境,确保yolov8源码环境正确。
验证环境,下载权重文件yolov8n.pt,使用yolov8环境下运行yolo predict命令,或通过pycharm运行yolov8_predict.py,检查输出结果,确保环境无误。
st-gcn环境搭建
搭建ST-GCN环境的步骤如下:
一、硬件与系统准备
推荐使用基于Ubuntu .的系统,可从浙大官网下载稳定版本的镜像。通过U盘启动制作Ubuntu系统盘,完成格式化后使用深度制作工具进行系统安装。在桌面计算机中使用磁盘管理工具创建Ubuntu分区,一般GB空间足矣。通过BIOS设置将U盘设置为启动优先项,然后开始安装Ubuntu系统。
二、安装Python3
在Ubuntu系统中,将Python3设置为默认版本,使用pip进行包管理无需额外命令。在终端中通过快捷键或命令行操作完成Python3的安装。
三、软件源配置
使用国内服务器作为Ubuntu软件源,推荐使用阿里云提供的服务,无需额外配置。如果使用官方镜像,可能需要更新软件源以获取最新软件包。
四、安装显卡驱动
使用NVIDIA显卡的用户,需安装对应版本的驱动程序。通过三种方法之一:官方PPA源安装、下载并编译安装、添加官方PPA源后安装。quasar怎么导入源码
五、安装CUDA和cuDNN
检查NVIDIA显卡型号和系统内核版本,确保CUDA版本与驱动匹配。下载CUDA和cuDNN,按步骤安装,确保安装成功并验证。
六、安装Python3的pip虚拟环境
在Python3环境下安装pip,所有pip命令都将在Python3环境中执行。创建虚拟环境管理目录,将虚拟环境添加到环境变量中,并创建Python3虚拟环境。
七、安装torch和torchvision
使用国内源安装torch和torchvision,可永久修改pip安装源。查看Python版本与对应torch版本的关系,确保兼容性。
八、安装cmake
使用cmake配置编译参数,安装cmake和cmake-gui,确保cmake操作顺利进行。
九、安装opencv
可以选择通过apt-get安装opencv-python或从源码构建。构建时注意解压、更新依赖、下载ippicv,确保opencv功能齐全。
十、安装caffe
从openpose提供的链接下载caffe源码,解压后修改Makefile配置参数,编译安装。
十一、安装openpose
在caffe目录下连接openpose,下载源码,配置编译参数,确保兼容性和接口接入,测试安装成功。
十二、安装ffmpeg
下载ffmpeg源码,安装依赖环境,配置并编译安装。推荐使用smplayer作为视频播放软件。
完成上述步骤后,环境搭建就已基本完成。评估官方模型,训练自己的模型,进行样本示例展示。安装视频播放软件,如smplayer,用于观看可视化效果。欢迎指出错误与建议,祝您搭建成功!
Ubuntu安装使用Segment Anything
安装Python 3..
先确保已安装Python 3.8及以上版本,当前服务器版本为3.7.0。
使用更新命令获取最新包列表。
准备安装所需的依赖包,步骤因博主不同而异。
下载源码包并解压,根据实际情况调整安装指令。
配置编译参数,设置为特定路径。
开启优化选项。
执行编译命令。
进行安装,注意软连接问题。
发现链接路径与预期不同,需调整软连接确保指向正确的Python版本。
创建新软连接,确保终端调用的Python版本为3..。
设置别名,确保用户直接调用的Python为所需版本。
在.bashrc文件中添加配置。
再次测试,确保Python版本正确。
安装PyTorch与torchvision,参考官方文档。
检查是否具备CUDA.2环境,确认兼容性。
选择满足需求的PyTorch版本,如1..1。
安装过程中可能尝试下载Python 3.9.,但因兼容性问题未能完成。
下载包大小显著,包括CUDA toolkit、PyTorch、MKL等。
忽略安装Python 3.9.的失败,继续安装所需版本。
安装Segment Anything,考虑调整pip软链接。
尝试使用pip -V确认链接,已进行相应操作。
开始使用Segment Anything,参考相关链接。
注意PyTorch和torchvision安装时的差异,根据实际情况调整。
从官方下载代码,使用VSCode打开。
安装Jupyter和Python扩展,尝试安装过程中可能遇到的报错。
安装过程中可能遇到torchaudio报错,再次确认。
替换sam_checkpoint路径为下载的checkpoint。
最终实现无报错的安装和使用流程。
Jetson nano部署Yolov8
于年1月日成功完成了Jetson nano B的Yolov8部署,无需科学上网,准备工作包括U盘。
1. 安装流程首先从官网获取Jetson nano开发者套件SD卡镜像并下载(压缩文件需解压)。
1.2 使用Etcher工具进行烧录
2. 配置Python环境:推荐Python 3.8,因ultralytics要求。创建独立环境,具体步骤如下:
2.1 安装基础环境
2.2 下载Python 3.8源代码至Jetson Nano
2.3 解压并进入Python-3.8.文件夹进行后续操作
2.4 到Python-3.8.中编译并配置Python环境
3.1 安装PyTorch和Torchvision:由于平台不兼容,需手动下载预编译和编译安装
3.2 将下载的文件传输至U盘,通过终端在Jetson nano中安装
3.3 安装ultralytics,注意在激活独立环境后操作
4. 使用时,每次启动需打开独立环境,可能遇到libomp.so.5库缺失,需安装OpenMP库解决
5. 个人简介:拥有丰富的学习和竞赛经历,目前准备出国留学,目标是新加坡国立大学的机器人学研究生
5.2 可通过以下方式联系:
CSDN主页,小红书和抖音,Gitee和Github代码仓库,以及ac@.com邮箱和微信。
detectron2安装及微软最新state of the art目标检测模型DynamicHead训练自己数据全程指南
首先,您需要从github.com/microsoft/Dy...仓库下载代码。
同时,下载并安装detectron2源码。
在Win系统中安装Detectron2时,有一些要点和避坑指南需要注意。
安装命令为:python setup.py build develop。
执行该命令可能会报错,提示找不到vc++ .0。这时,您需要在VS中安装C++组件。
接下来,需要安装依赖库,如torch、torchvision、pycocotools和fvcore等。
安装过程中,在Win上运行安装命令可能会遇到错误:nvcc.exe failed with exit status 1。
要解决此错误,需要修改detectron2\layers\csrc ms_rotated ms_rotated_cuda.cu代码前几行,将条件编译#ifdef WITH_CUDA和#ifdef WITH_HIP全部注释掉,只保留#include "box_iou_rotated/box_iou_rotated_utils.h"。
修改完成后,再次运行python setup.py build develop,并等待一段时间,就可以顺利编译并安装了。
DynamicHead训练代码原版不包含注册数据集的代码,需要修改train_net.py文件,将注册数据集的代码加入其中。修改后的完整代码如下所示。
请确保您的训练数据集符合coco格式,如果不是,需要编写代码将其转换为coco格式。
修改数据集路径的代码如下,其中coco文件夹是训练和验证集json文件所在路径,train_path和val_path是训练和验证集所在路径。
在以下代码中,需要修改数据集的类别信息和注册的训练验证集名字。
训练的脚本命令是:python train_net.py --config configs/dyhead_swint_atss_fpn_2x_ms.yaml --num-gpus 1。
命令中出现的configs文件夹中的yaml文件也需要修改,将其中的datasets修改为您代码中注册的数据集名字,并在代码中重写或覆盖选项。
运行上述训练脚本可能会遇到的问题及解决方案如下:
遇到"broken pipe"错误,即多进程数据加载错误,将加载进程数修改为1即可解决。
如果训练报错weights_decay是none,打印cfg查看哪些是none,发现weight_decay_bias是none,将weight_decay_bias设置为0而不是none即可成功训练。
Github上提供的预训练权重是在coco数据集上训练的,类别数与您的数据集不同,不能作为weights初始化。
最后,成功训练的图示。
NVIDIA Jetson NX安装torchvision教程
安装 torchvision 前,先确保已安装 pytorch,参考相关教程进行操作。
首先,切换至国内软件源,执行更新操作。
安装 torchvision 所需依赖。
使用 dpkg 手动安装时,注意到 libpython3-dev 未有候选版本,需手动安装。安装其他依赖已满足。
下载 arm 架构的 libpython3-dev_3.6.7-1~._arm.deb 包,确保版本与当前 python3(3.6.9)兼容。
使用 dpkg -i 安装 deb 包,若遇到依赖问题,直接在网页中查找所有依赖的下载链接。
安装 libpython3-dev 的依赖 libpython3.6-dev 时,出现版本不正确的错误。分析后发现 libpython3.6-dev 需要的版本为 3.6.9-1~.ubuntu1.4,已有的版本为 3.6.9-1~.,因此安装 libpython3.6-dev 的候选版本 libpython3.6-stdlib 中最后一个版本,即为所需版本 3.6.9-1~.ubuntu1.4。
安装 torchvision 源码,确保 pytorch 和 torchvision 版本匹配,如 torch 1.6 版本对应 torchvision 0.7.0 版本。
使用码云账号注册并导入 torchvision 仓库,完成代码下载。
进入 torchvision 目录,使用命令编译,通常需时约十分钟。
当出现 pillow 报错时,说明 torchvision 近于安装成功。返回上一级目录,使用 pip/pip3 安装 pillow。
若下载速度慢,可使用国内豆瓣源下载安装 pillow。
安装 pillow 后,再次尝试导入 torch 仍报错,需再次进入 torchvision 目录进行编译安装。这次配置完成迅速。
使用 pip3 list 查看已安装包及版本,确认 torchvision 安装完成。
执行卷积神经网络训练,速度比本地快四倍。使用 jtop 监控 CPU、GPU 运行情况,观察在 Jetson Nano 上使用 pytorch 并设置 CUDA 进行训练时,主要由 GPU 执行计算,W 功率能达到的算力相当不错。
树莓派安装pytorch,史上最全方法合集(附安装链接)
在树莓派上安装PyTorch是一项挑战,特别是对于arm架构的设备。以下是详细的安装步骤合集,旨在帮助你顺利搭建。1. 位系统下的PyTorch安装
虽然官方提供的树莓派系统为位,但部分库可能不支持。如果你的项目库在位下可用,可参考此部分。同时,这里会涉及到基础配置,如SSH、VNC和Python3.7的安装。2. 代理设置
仅对git操作提供代理设置,如果你有其他方式,可跳过此步骤。3. 位系统源码编译
由于官方资源无法满足需求,可能需要自编译。尽管遇到困难,但这是推荐的方法,因为自己编译更放心。注意编译过程中的问题和解决办法。4. 位系统安装
转向位系统是解决一些兼容问题的明智选择。位系统安装更为直接,但需注意官方隐藏的位系统链接。位PyTorch安装
找到并使用现成的位wheel文件,如大神仓库提供的资源,以简化安装过程。5. 环境测试与问题调试
安装后进行测试,可能会遇到小问题,如权限问题或torchvision的配置。逐步调试,确保每个步骤都正确无误。结论与总结
虽然过程曲折,但通过一步步的配置和尝试,最终实现了gloo分布式环境。记住,配置过程中遇到问题不要慌张,耐心解决每一个问题,一步步来,总会成功。如有任何疑问,本文作者愿意提供帮助和分享资源。 年8月日更新:已更新轮子文件链接,欢迎收藏和分享,共同进步。



2024-12-24 00:16
2024-12-23 23:52
2024-12-23 23:27
2024-12-23 23:06
2024-12-23 22:31
